 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter as Generators Than Classifiers: Leveraging LLMs and Synthetic Data for Low-Resource Multilingual Classification
Jan 22, 2026Large Language Models (LLMs) have demonstrated remarkable multilingual capabilities, making them promising tools in both high- and low-resource languages. One particularly valuable use case is generating synthetic samples that can be used to train smaller models in low-resource scenarios where human-labelled data is scarce. In this work, we investigate whether these synthetic data generation capabilities can serve as a form of distillation, producing smaller models that perform on par with or even better than massive LLMs across languages and tasks. To this end, we use a state-of-the-art multilingual LLM to generate synthetic datasets covering 11 languages and 4 classification tasks. These datasets are then used to train smaller models via fine-tuning or instruction tuning, or as synthetic in-context examples for compact LLMs. Our experiments show that even small amounts of synthetic data enable smaller models to outperform the large generator itself, particularly in low-resource languages. Overall, the results suggest that LLMs are best utilised as generators (teachers) rather than classifiers, producing data that empowers smaller and more efficient multilingual models.
RecGaze: The First Eye Tracking and User Interaction Dataset for Carousel Interfaces
Apr 29, 2025Carousel interfaces are widely used in e-commerce and streaming services, but little research has been devoted to them. Previous studies of interfaces for presenting search and recommendation results have focused on single ranked lists, but it appears their results cannot be extrapolated to carousels due to the added complexity. Eye tracking is a highly informative approach to understanding how users click, yet there are no eye tracking studies concerning carousels. There are very few interaction datasets on recommenders with carousel interfaces and none that contain gaze data. We introduce the RecGaze dataset: the first comprehensive feedback dataset on carousels that includes eye tracking results, clicks, cursor movements, and selection explanations. The dataset comprises of interactions from 3 movie selection tasks with 40 different carousel interfaces per user. In total, 87 users and 3,477 interactions are logged. In addition to the dataset, its description and possible use cases, we provide results of a survey on carousel design and the first analysis of gaze data on carousels, which reveals a golden triangle or F-pattern browsing behavior. Our work seeks to advance the field of carousel interfaces by providing the first dataset with eye tracking results on carousels. In this manner, we provide and encourage an empirical understanding of interactions with carousel interfaces, for building better recommender systems through gaze information, and also encourage the development of gaze-based recommenders.
A Survey on Automatic Credibility Assessment of Textual Credibility Signals in the Era of Large Language Models
Oct 28, 2024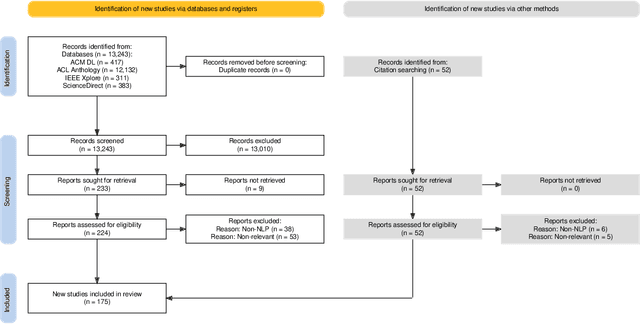
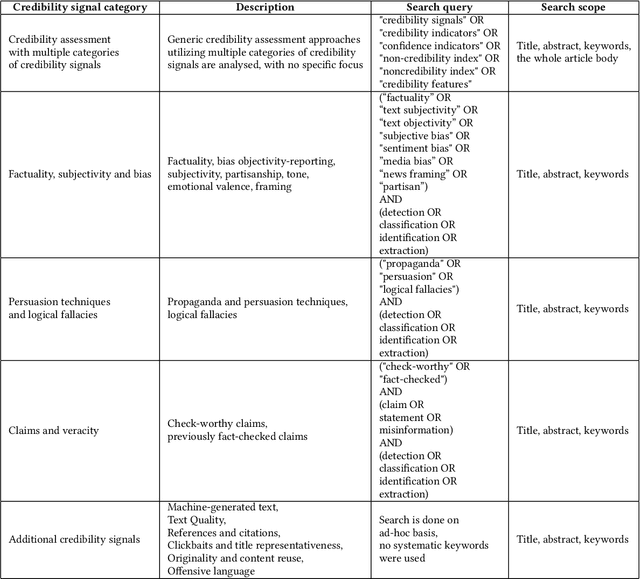
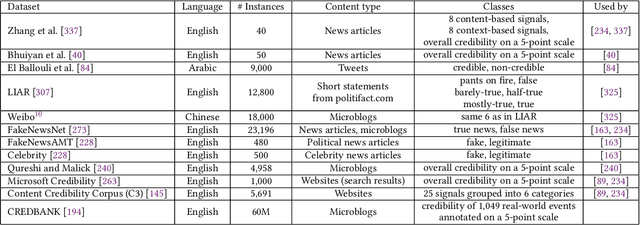
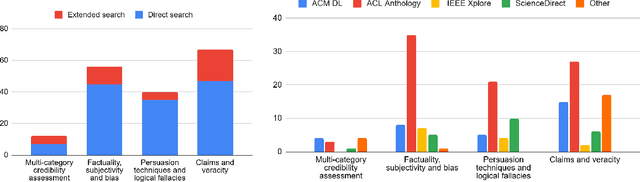
In the current era of social media and generative AI, an ability to automatically assess the credibility of online social media content is of tremendous importance. Credibility assessment is fundamentally based on aggregating credibility signals, which refer to small units of information, such as content factuality, bias, or a presence of persuasion techniques, into an overall credibility score. Credibility signals provide a more granular, more easily explainable and widely utilizable information in contrast to currently predominant fake news detection, which utilizes various (mostly latent) features. A growing body of research on automatic credibility assessment and detection of credibility signals can be characterized as highly fragmented and lacking mutual interconnections. This issue is even more prominent due to a lack of an up-to-date overview of research works on automatic credibility assessment. In this survey, we provide such systematic and comprehensive literature review of 175 research papers while focusing on textual credibility signals and Natural Language Processing (NLP), which undergoes a significant advancement due to Large Language Models (LLMs). While positioning the NLP research into the context of other multidisciplinary research works, we tackle with approaches for credibility assessment as well as with 9 categories of credibility signals (we provide a thorough analysis for 3 of them, namely: 1) factuality, subjectivity and bias, 2) persuasion techniques and logical fallacies, and 3) claims and veracity). Following the description of the existing methods, datasets and tools, we identify future challenges and opportunities, while paying a specific attention to recent rapid development of generative AI.
Use Random Selection for Now: Investigation of Few-Shot Selection Strategies in LLM-based Text Augmentation for Classification
Oct 14, 2024



The generative large language models (LLMs) are increasingly used for data augmentation tasks, where text samples are paraphrased (or generated anew) and then used for classifier fine-tuning. Existing works on augmentation leverage the few-shot scenarios, where samples are given to LLMs as part of prompts, leading to better augmentations. Yet, the samples are mostly selected randomly and a comprehensive overview of the effects of other (more ``informed'') sample selection strategies is lacking. In this work, we compare sample selection strategies existing in few-shot learning literature and investigate their effects in LLM-based textual augmentation. We evaluate this on in-distribution and out-of-distribution classifier performance. Results indicate, that while some ``informed'' selection strategies increase the performance of models, especially for out-of-distribution data, it happens only seldom and with marginal performance increases. Unless further advances are made, a default of random sample selection remains a good option for augmentation practitioners.
Task Prompt Vectors: Effective Initialization through Multi-Task Soft-Prompt Transfer
Aug 02, 2024Prompt tuning is a modular and efficient solution for training large language models (LLMs). One of its main advantages is task modularity, making it suitable for multi-task problems. However, current soft-prompt-based methods often sacrifice multi-task modularity, requiring the training process to be fully or partially repeated for each newly added task. While recent work on task vectors applied arithmetic operations on full model weights to achieve the desired multi-task performance, a similar approach for soft-prompts is still missing. To this end, we introduce Task Prompt Vectors, created by element-wise difference between weights of tuned soft-prompts and their random initialization. Experimental results on 12 NLU datasets show that task prompt vectors can be used in low-resource settings to effectively initialize prompt tuning on similar tasks. In addition, we show that task prompt vectors are independent of the random initialization of prompt tuning. This allows prompt arithmetics with the pre-trained vectors from different tasks. In this way, by arithmetic addition of task prompt vectors from multiple tasks, we are able to outperform a state-of-the-art baseline in some cases.
Fighting Randomness with Randomness: Mitigating Optimisation Instability of Fine-Tuning using Delayed Ensemble and Noisy Interpolation
Jun 18, 2024While fine-tuning of pre-trained language models generally helps to overcome the lack of labelled training samples, it also displays model performance instability. This instability mainly originates from randomness in initialisation or data shuffling. To address this, researchers either modify the training process or augment the available samples, which typically results in increased computational costs. We propose a new mitigation strategy, called Delayed Ensemble with Noisy Interpolation (DENI), that leverages the strengths of ensembling, noise regularisation and model interpolation, while retaining computational efficiency. We compare DENI with 9 representative mitigation strategies across 3 models, 4 tuning strategies and 7 text classification datasets. We show that: 1) DENI outperforms the best performing mitigation strategy (Ensemble), while using only a fraction of its cost; 2) the mitigation strategies are beneficial for parameter-efficient fine-tuning (PEFT) methods, outperforming full fine-tuning in specific cases; and 3) combining DENI with data augmentation often leads to even more effective instability mitigation.
Fine-Tuning, Prompting, In-Context Learning and Instruction-Tuning: How Many Labelled Samples Do We Need?
Feb 20, 2024When solving a task with limited labelled data, researchers can either use a general large language model without further update, or use the few examples to tune a specialised smaller model. When enough labels are available, the specialised models outperform the general ones on many NLP tasks. In this work, we aim to investigate how many labelled samples are required for the specialised models to achieve this superior performance, while taking the results variance into consideration. Observing the behaviour of prompting, in-context learning, fine-tuning and instruction-tuning, identifying their break-even points when increasing number of labelled training samples across three tasks of varying complexity, we find that the specialised models often need only few samples ($100-1000$) to be on par or better than the general ones. At the same time, the amount of required labelled data strongly depends on the task complexity and results variance.
On Sensitivity of Learning with Limited Labelled Data to the Effects of Randomness: Impact of Interactions and Systematic Choices
Feb 20, 2024



While learning with limited labelled data can improve performance when the labels are lacking, it is also sensitive to the effects of uncontrolled randomness introduced by so-called randomness factors (e.g., varying order of data). We propose a method to systematically investigate the effects of randomness factors while taking the interactions between them into consideration. To measure the true effects of an individual randomness factor, our method mitigates the effects of other factors and observes how the performance varies across multiple runs. Applying our method to multiple randomness factors across in-context learning and fine-tuning approaches on 7 representative text classification tasks and meta-learning on 3 tasks, we show that: 1) disregarding interactions between randomness factors in existing works caused inconsistent findings due to incorrect attribution of the effects of randomness factors, such as disproving the consistent sensitivity of in-context learning to sample order even with random sample selection; and 2) besides mutual interactions, the effects of randomness factors, especially sample order, are also dependent on more systematic choices unexplored in existing works, such as number of classes, samples per class or choice of prompt format.
Automatic Combination of Sample Selection Strategies for Few-Shot Learning
Feb 05, 2024In few-shot learning, such as meta-learning, few-shot fine-tuning or in-context learning, the limited number of samples used to train a model have a significant impact on the overall success. Although a large number of sample selection strategies exist, their impact on the performance of few-shot learning is not extensively known, as most of them have been so far evaluated in typical supervised settings only. In this paper, we thoroughly investigate the impact of 20 sample selection strategies on the performance of 5 few-shot learning approaches over 8 image and 6 text datasets. In addition, we propose a new method for automatic combination of sample selection strategies (ACSESS) that leverages the strengths and complementary information of the individual strategies. The experimental results show that our method consistently outperforms the individual selection strategies, as well as the recently proposed method for selecting support examples for in-context learning. We also show a strong modality, dataset and approach dependence for the majority of strategies as well as their dependence on the number of shots - demonstrating that the sample selection strategies play a significant role for lower number of shots, but regresses to random selection at higher number of shots.
Authorship Obfuscation in Multilingual Machine-Generated Text Detection
Jan 15, 2024



High-quality text generation capability of latest Large Language Models (LLMs) causes concerns about their misuse (e.g., in massive generation/spread of disinformation). Machine-generated text (MGT) detection is important to cope with such threats. However, it is susceptible to authorship obfuscation (AO) methods, such as paraphrasing, which can cause MGTs to evade detection. So far, this was evaluated only in monolingual settings. Thus, the susceptibility of recently proposed multilingual detectors is still unknown. We fill this gap by comprehensively benchmarking the performance of 10 well-known AO methods, attacking 37 MGT detection methods against MGTs in 11 languages (i.e., 10 $\times$ 37 $\times$ 11 = 4,070 combinations). We also evaluate the effect of data augmentation on adversarial robustness using obfuscated texts. The results indicate that all tested AO methods can cause detection evasion in all tested languages, where homoglyph attacks are especially successful.