 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Based Adversarial Persuasion Attacks on Fact-Checking Systems
Jan 23, 2026Automated fact-checking (AFC) systems are susceptible to adversarial attacks, enabling false claims to evade detection. Existing adversarial frameworks typically rely on injecting noise or altering semantics, yet no existing framework exploits the adversarial potential of persuasion techniques, which are widely used in disinformation campaigns to manipulate audiences. In this paper, we introduce a novel class of persuasive adversarial attacks on AFCs by employing a generative LLM to rephrase claims using persuasion techniques. Considering 15 techniques grouped into 6 categories, we study the effects of persuasion on both claim verification and evidence retrieval using a decoupled evaluation strategy. Experiments on the FEVER and FEVEROUS benchmarks show that persuasion attacks can substantially degrade both verification performance and evidence retrieval. Our analysis identifies persuasion techniques as a potent class of adversarial attacks, highlighting the need for more robust AFC systems.
A Cross-Domain Study of the Use of Persuasion Techniques in Online Disinformation
Dec 19, 2024Disinformation, irrespective of domain or language, aims to deceive or manipulate public opinion, typically through employing advanced persuasion techniques. Qualitative and quantitative research on the weaponisation of persuasion techniques in disinformation has been mostly topic-specific (e.g., COVID-19) with limited cross-domain studies, resulting in a lack of comprehensive understanding of these strategies. This study employs a state-of-the-art persuasion technique classifier to conduct a large-scale, multi-domain analysis of the role of 16 persuasion techniques in disinformation narratives. It shows how different persuasion techniques are employed disproportionately in different disinformation domains. We also include a detailed case study on climate change disinformation, highlighting how linguistic, psychological, and cultural factors shape the adaptation of persuasion strategies to fit unique thematic contexts.
A Survey on Automatic Credibility Assessment of Textual Credibility Signals in the Era of Large Language Models
Oct 28, 2024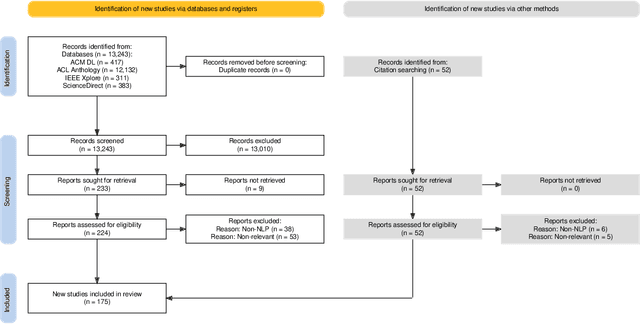
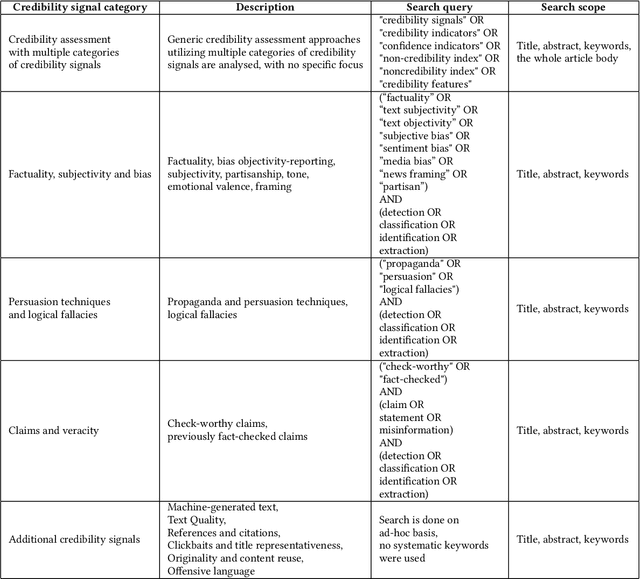
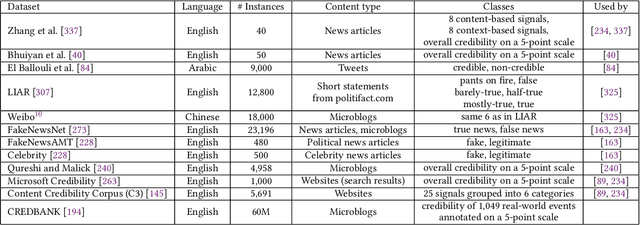
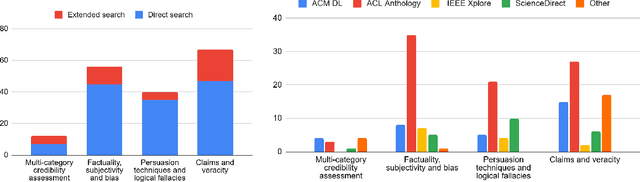
In the current era of social media and generative AI, an ability to automatically assess the credibility of online social media content is of tremendous importance. Credibility assessment is fundamentally based on aggregating credibility signals, which refer to small units of information, such as content factuality, bias, or a presence of persuasion techniques, into an overall credibility score. Credibility signals provide a more granular, more easily explainable and widely utilizable information in contrast to currently predominant fake news detection, which utilizes various (mostly latent) features. A growing body of research on automatic credibility assessment and detection of credibility signals can be characterized as highly fragmented and lacking mutual interconnections. This issue is even more prominent due to a lack of an up-to-date overview of research works on automatic credibility assessment. In this survey, we provide such systematic and comprehensive literature review of 175 research papers while focusing on textual credibility signals and Natural Language Processing (NLP), which undergoes a significant advancement due to Large Language Models (LLMs). While positioning the NLP research into the context of other multidisciplinary research works, we tackle with approaches for credibility assessment as well as with 9 categories of credibility signals (we provide a thorough analysis for 3 of them, namely: 1) factuality, subjectivity and bias, 2) persuasion techniques and logical fallacies, and 3) claims and veracity). Following the description of the existing methods, datasets and tools, we identify future challenges and opportunities, while paying a specific attention to recent rapid development of generative AI.
EUvsDisinfo: a Dataset for Multilingual Detection of Pro-Kremlin Disinformation in News Articles
Jun 18, 2024



This work introduces EUvsDisinfo, a multilingual dataset of trustworthy and disinformation articles related to pro-Kremlin themes. It is sourced directly from the debunk articles written by experts leading the EUvsDisinfo project. Our dataset is the largest to-date resource in terms of the overall number of articles and distinct languages. It also provides the largest topical and temporal coverage. Using this dataset, we investigate the dissemination of pro-Kremlin disinformation across different languages, uncovering language-specific patterns targeting specific disinformation topics. We further analyse the evolution of topic distribution over an eight-year period, noting a significant surge in disinformation content before the full-scale invasion of Ukraine in 2022. Lastly, we demonstrate the dataset's applicability in training models to effectively distinguish between disinformation and trustworthy content in multilingual settings.
Detecting Misinformation with LLM-Predicted Credibility Signals and Weak Supervision
Sep 14, 2023Credibility signals represent a wide range of heuristics that are typically used by journalists and fact-checkers to assess the veracity of online content. Automating the task of credibility signal extraction, however, is very challenging as it requires high-accuracy signal-specific extractors to be trained, while there are currently no sufficiently large datasets annotated with all credibility signals. This paper investigates whether large language models (LLMs) can be prompted effectively with a set of 18 credibility signals to produce weak labels for each signal. We then aggregate these potentially noisy labels using weak supervision in order to predict content veracity. We demonstrate that our approach, which combines zero-shot LLM credibility signal labeling and weak supervision, outperforms state-of-the-art classifiers on two misinformation datasets without using any ground-truth labels for training. We also analyse the contribution of the individual credibility signals towards predicting content veracity, which provides new valuable insights into their role in misinformation detection.
Noisy Self-Training with Data Augmentations for Offensive and Hate Speech Detection Tasks
Jul 31, 2023

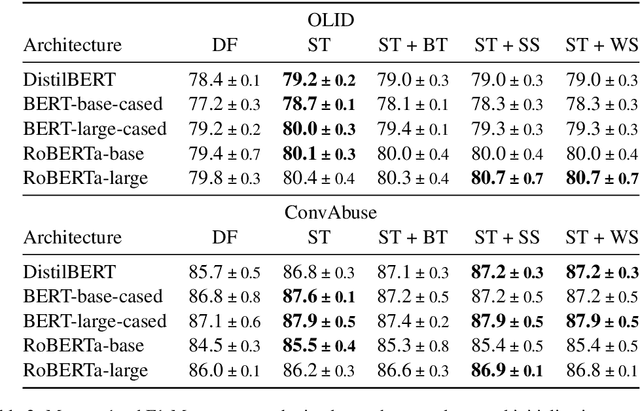
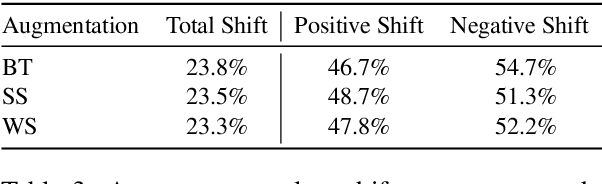
Online social media is rife with offensive and hateful comments, prompting the need for their automatic detection given the sheer amount of posts created every second. Creating high-quality human-labelled datasets for this task is difficult and costly, especially because non-offensive posts are significantly more frequent than offensive ones. However, unlabelled data is abundant, easier, and cheaper to obtain. In this scenario, self-training methods, using weakly-labelled examples to increase the amount of training data, can be employed. Recent "noisy" self-training approaches incorporate data augmentation techniques to ensure prediction consistency and increase robustness against noisy data and adversarial attacks. In this paper, we experiment with default and noisy self-training using three different textual data augmentation techniques across five different pre-trained BERT architectures varying in size. We evaluate our experiments on two offensive/hate-speech datasets and demonstrate that (i) self-training consistently improves performance regardless of model size, resulting in up to +1.5% F1-macro on both datasets, and (ii) noisy self-training with textual data augmentations, despite being successfully applied in similar settings, decreases performance on offensive and hate-speech domains when compared to the default method, even with state-of-the-art augmentations such as backtranslation.
Team SheffieldVeraAI at SemEval-2023 Task 3: Mono and multilingual approaches for news genre, topic and persuasion technique classification
Mar 16, 2023



This paper describes our approach for SemEval-2023 Task 3: Detecting the category, the framing, and the persuasion techniques in online news in a multi-lingual setup. For Subtask 1 (News Genre), we propose an ensemble of fully trained and adapter mBERT models which was ranked joint-first for German, and had the highest mean rank of multi-language teams. For Subtask 2 (Framing), we achieved first place in 3 languages, and the best average rank across all the languages, by using two separate ensembles: a monolingual RoBERTa-MUPPETLARGE and an ensemble of XLM-RoBERTaLARGE with adapters and task adaptive pretraining. For Subtask 3 (Persuasion Techniques), we train a monolingual RoBERTa-Base model for English and a multilingual mBERT model for the remaining languages, which achieved top 10 for all languages, including 2nd for English. For each subtask, we compare monolingual and multilingual approaches, and consider class imbalance techniques.
Toxic Language Detection in Social Media for Brazilian Portuguese: New Dataset and Multilingual Analysis
Oct 09, 2020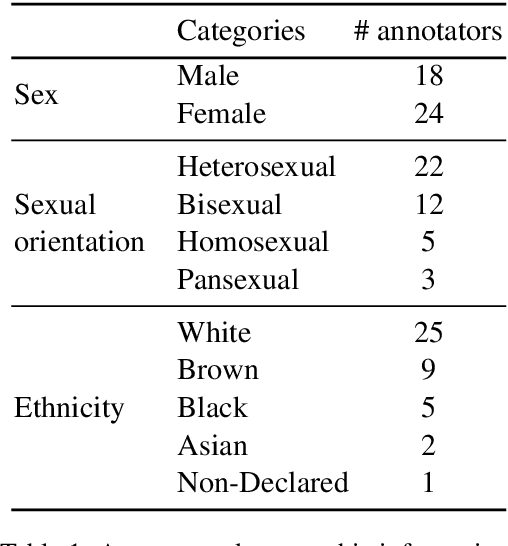
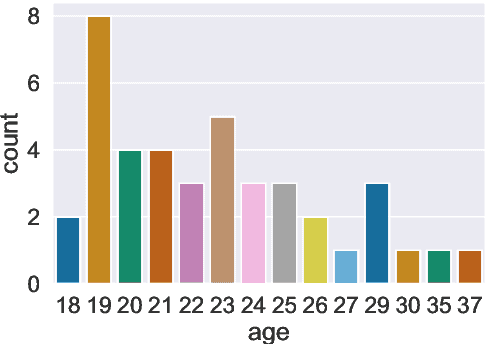
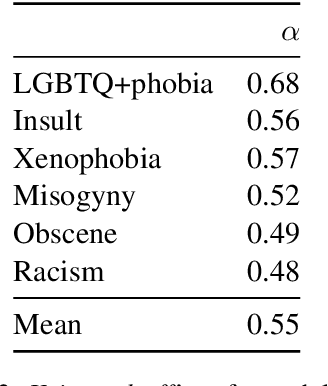

Hate speech and toxic comments are a common concern of social media platform users. Although these comments are, fortunately, the minority in these platforms, they are still capable of causing harm. Therefore, identifying these comments is an important task for studying and preventing the proliferation of toxicity in social media. Previous work in automatically detecting toxic comments focus mainly in English, with very few work in languages like Brazilian Portuguese. In this paper, we propose a new large-scale dataset for Brazilian Portuguese with tweets annotated as either toxic or non-toxic or in different types of toxicity. We present our dataset collection and annotation process, where we aimed to select candidates covering multiple demographic groups. State-of-the-art BERT models were able to achieve 76% macro-F1 score using monolingual data in the binary case. We also show that large-scale monolingual data is still needed to create more accurate models, despite recent advances in multilingual approaches. An error analysis and experiments with multi-label classification show the difficulty of classifying certain types of toxic comments that appear less frequently in our data and highlights the need to develop models that are aware of different categories of toxicity.