 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoisy Self-Training with Data Augmentations for Offensive and Hate Speech Detection Tasks
Jul 31, 2023

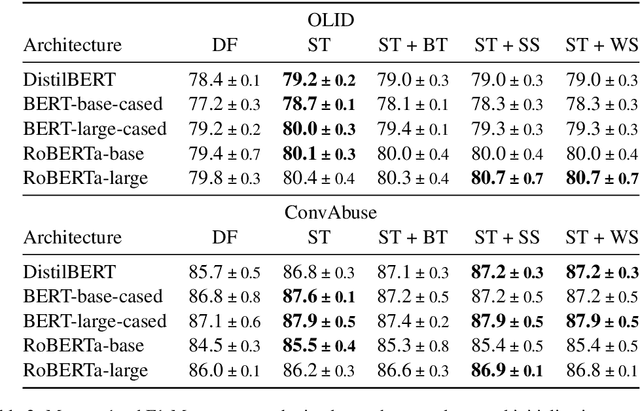
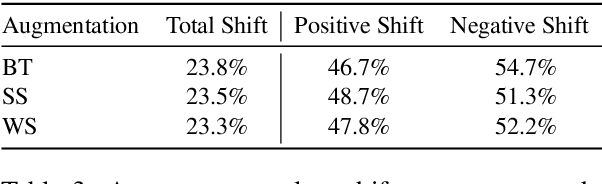
Online social media is rife with offensive and hateful comments, prompting the need for their automatic detection given the sheer amount of posts created every second. Creating high-quality human-labelled datasets for this task is difficult and costly, especially because non-offensive posts are significantly more frequent than offensive ones. However, unlabelled data is abundant, easier, and cheaper to obtain. In this scenario, self-training methods, using weakly-labelled examples to increase the amount of training data, can be employed. Recent "noisy" self-training approaches incorporate data augmentation techniques to ensure prediction consistency and increase robustness against noisy data and adversarial attacks. In this paper, we experiment with default and noisy self-training using three different textual data augmentation techniques across five different pre-trained BERT architectures varying in size. We evaluate our experiments on two offensive/hate-speech datasets and demonstrate that (i) self-training consistently improves performance regardless of model size, resulting in up to +1.5% F1-macro on both datasets, and (ii) noisy self-training with textual data augmentations, despite being successfully applied in similar settings, decreases performance on offensive and hate-speech domains when compared to the default method, even with state-of-the-art augmentations such as backtranslation.
Toxic Language Detection in Social Media for Brazilian Portuguese: New Dataset and Multilingual Analysis
Oct 09, 2020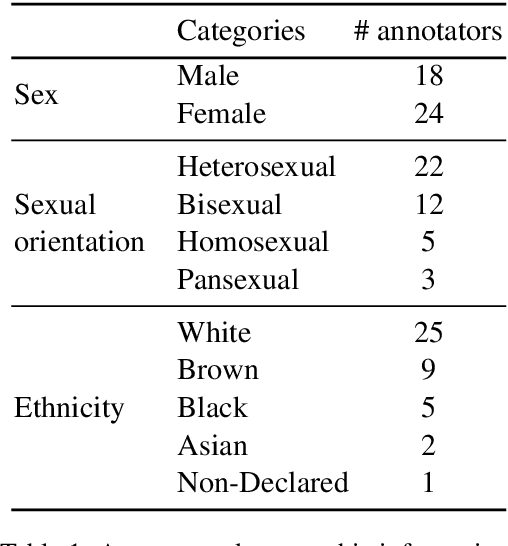
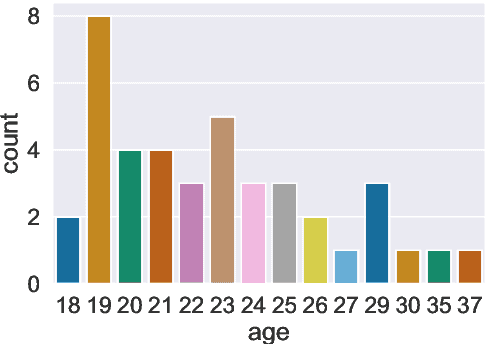
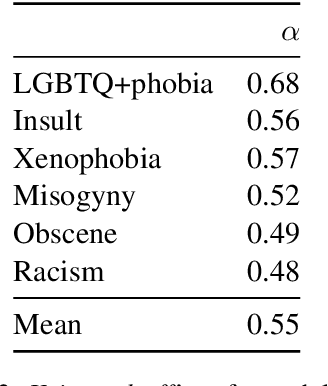

Hate speech and toxic comments are a common concern of social media platform users. Although these comments are, fortunately, the minority in these platforms, they are still capable of causing harm. Therefore, identifying these comments is an important task for studying and preventing the proliferation of toxicity in social media. Previous work in automatically detecting toxic comments focus mainly in English, with very few work in languages like Brazilian Portuguese. In this paper, we propose a new large-scale dataset for Brazilian Portuguese with tweets annotated as either toxic or non-toxic or in different types of toxicity. We present our dataset collection and annotation process, where we aimed to select candidates covering multiple demographic groups. State-of-the-art BERT models were able to achieve 76% macro-F1 score using monolingual data in the binary case. We also show that large-scale monolingual data is still needed to create more accurate models, despite recent advances in multilingual approaches. An error analysis and experiments with multi-label classification show the difficulty of classifying certain types of toxic comments that appear less frequently in our data and highlights the need to develop models that are aware of different categories of toxicity.
Measuring What Counts: The case of Rumour Stance Classification
Oct 09, 2020
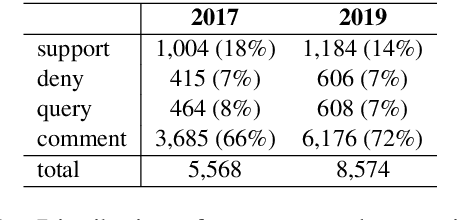
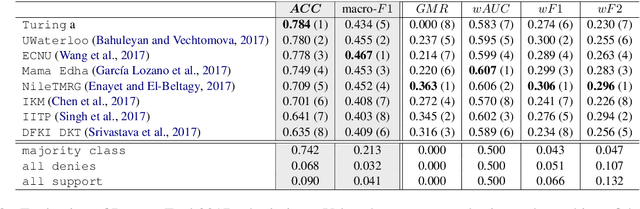
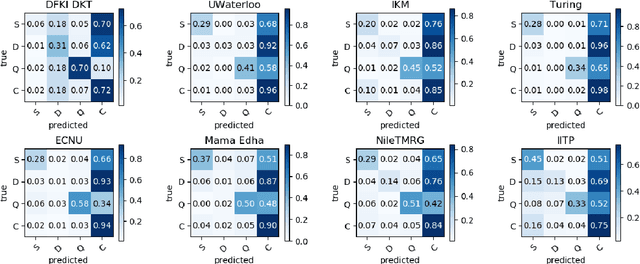
Stance classification can be a powerful tool for understanding whether and which users believe in online rumours. The task aims to automatically predict the stance of replies towards a given rumour, namely support, deny, question, or comment. Numerous methods have been proposed and their performance compared in the RumourEval shared tasks in 2017 and 2019. Results demonstrated that this is a challenging problem since naturally occurring rumour stance data is highly imbalanced. This paper specifically questions the evaluation metrics used in these shared tasks. We re-evaluate the systems submitted to the two RumourEval tasks and show that the two widely adopted metrics -- accuracy and macro-F1 -- are not robust for the four-class imbalanced task of rumour stance classification, as they wrongly favour systems with highly skewed accuracy towards the majority class. To overcome this problem, we propose new evaluation metrics for rumour stance detection. These are not only robust to imbalanced data but also score higher systems that are capable of recognising the two most informative minority classes (support and deny).