 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLUFF: Benchmarking the Detection of False and Synthetic Content across 58 Low-Resource Languages
Feb 28, 2026Multilingual falsehoods threaten information integrity worldwide, yet detection benchmarks remain confined to English or a few high-resource languages, leaving low-resource linguistic communities without robust defense tools. We introduce BLUFF, a comprehensive benchmark for detecting false and synthetic content, spanning 79 languages with over 202K samples, combining human-written fact-checked content (122K+ samples across 57 languages) and LLM-generated content (79K+ samples across 71 languages). BLUFF uniquely covers both high-resource "big-head" (20) and low-resource "long-tail" (59) languages, addressing critical gaps in multilingual research on detecting false and synthetic content. Our dataset features four content types (human-written, LLM-generated, LLM-translated, and hybrid human-LLM text), bidirectional translation (English$\leftrightarrow$X), 39 textual modification techniques (36 manipulation tactics for fake news, 3 AI-editing strategies for real news), and varying edit intensities generated using 19 diverse LLMs. We present AXL-CoI (Adversarial Cross-Lingual Agentic Chainof-Interactions), a novel multi-agentic framework for controlled fake/real news generation, paired with mPURIFY, a quality filtering pipeline ensuring dataset integrity. Experiments reveal state-of-theart detectors suffer up to 25.3% F1 degradation on low-resource versus high-resource languages. BLUFF provides the research community with a multilingual benchmark, extensive linguistic-oriented benchmark evaluation, comprehensive documentation, and opensource tools to advance equitable falsehood detection. Dataset and code are available at: https://jsl5710.github.io/BLUFF/
CAPER: Enhancing Career Trajectory Prediction using Temporal Knowledge Graph and Ternary Relationship
Aug 28, 2024



The problem of career trajectory prediction (CTP) aims to predict one's future employer or job position. While several CTP methods have been developed for this problem, we posit that none of these methods (1) jointly considers the mutual ternary dependency between three key units (i.e., user, position, and company) of a career and (2) captures the characteristic shifts of key units in career over time, leading to an inaccurate understanding of the job movement patterns in the labor market. To address the above challenges, we propose a novel solution, named as CAPER, that solves the challenges via sophisticated temporal knowledge graph (TKG) modeling. It enables the utilization of a graph-structured knowledge base with rich expressiveness, effectively preserving the changes in job movement patterns. Furthermore, we devise an extrapolated career reasoning task on TKG for a realistic evaluation. The experiments on a real-world career trajectory dataset demonstrate that CAPER consistently and significantly outperforms four baselines, two recent TKG reasoning methods, and five state-of-the-art CTP methods in predicting one's future companies and positions-i.e., on average, yielding 6.80% and 34.58% more accurate predictions, respectively.
Authorship Obfuscation in Multilingual Machine-Generated Text Detection
Jan 15, 2024



High-quality text generation capability of latest Large Language Models (LLMs) causes concerns about their misuse (e.g., in massive generation/spread of disinformation). Machine-generated text (MGT) detection is important to cope with such threats. However, it is susceptible to authorship obfuscation (AO) methods, such as paraphrasing, which can cause MGTs to evade detection. So far, this was evaluated only in monolingual settings. Thus, the susceptibility of recently proposed multilingual detectors is still unknown. We fill this gap by comprehensively benchmarking the performance of 10 well-known AO methods, attacking 37 MGT detection methods against MGTs in 11 languages (i.e., 10 $\times$ 37 $\times$ 11 = 4,070 combinations). We also evaluate the effect of data augmentation on adversarial robustness using obfuscated texts. The results indicate that all tested AO methods can cause detection evasion in all tested languages, where homoglyph attacks are especially successful.
Fighting Fire with Fire: The Dual Role of LLMs in Crafting and Detecting Elusive Disinformation
Oct 24, 2023Recent ubiquity and disruptive impacts of large language models (LLMs) have raised concerns about their potential to be misused (.i.e, generating large-scale harmful and misleading content). To combat this emerging risk of LLMs, we propose a novel "Fighting Fire with Fire" (F3) strategy that harnesses modern LLMs' generative and emergent reasoning capabilities to counter human-written and LLM-generated disinformation. First, we leverage GPT-3.5-turbo to synthesize authentic and deceptive LLM-generated content through paraphrase-based and perturbation-based prefix-style prompts, respectively. Second, we apply zero-shot in-context semantic reasoning techniques with cloze-style prompts to discern genuine from deceptive posts and news articles. In our extensive experiments, we observe GPT-3.5-turbo's zero-shot superiority for both in-distribution and out-of-distribution datasets, where GPT-3.5-turbo consistently achieved accuracy at 68-72%, unlike the decline observed in previous customized and fine-tuned disinformation detectors. Our codebase and dataset are available at https://github.com/mickeymst/F3.
MULTITuDE: Large-Scale Multilingual Machine-Generated Text Detection Benchmark
Oct 20, 2023There is a lack of research into capabilities of recent LLMs to generate convincing text in languages other than English and into performance of detectors of machine-generated text in multilingual settings. This is also reflected in the available benchmarks which lack authentic texts in languages other than English and predominantly cover older generators. To fill this gap, we introduce MULTITuDE, a novel benchmarking dataset for multilingual machine-generated text detection comprising of 74,081 authentic and machine-generated texts in 11 languages (ar, ca, cs, de, en, es, nl, pt, ru, uk, and zh) generated by 8 multilingual LLMs. Using this benchmark, we compare the performance of zero-shot (statistical and black-box) and fine-tuned detectors. Considering the multilinguality, we evaluate 1) how these detectors generalize to unseen languages (linguistically similar as well as dissimilar) and unseen LLMs and 2) whether the detectors improve their performance when trained on multiple languages.
JAMES: Job Title Mapping with Multi-Aspect Embeddings and Reasoning
Feb 22, 2022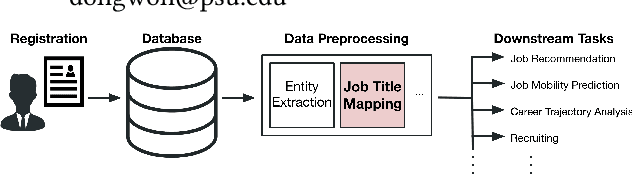



One of the most essential tasks needed for various downstream tasks in career analytics (e.g., career trajectory analysis, job mobility prediction, and job recommendation) is Job Title Mapping (JTM), where the goal is to map user-created (noisy and non-standard) job titles to predefined and standard job titles. However, solving JTM is domain-specific and non-trivial due to its inherent challenges: (1) user-created job titles are messy, (2) different job titles often overlap their job requirements, (3) job transition trajectories are inconsistent, and (4) the number of job titles in real world applications is large-scale. Toward this JTM problem, in this work, we propose a novel solution, named as JAMES, that constructs three unique embeddings of a target job title: topological, semantic, and syntactic embeddings, together with multi-aspect co-attention. In addition, we employ logical reasoning representations to collaboratively estimate similarities between messy job titles and standard job titles in the reasoning space. We conduct comprehensive experiments against ten competing models on the large-scale real-world dataset with more than 350,000 job titles. Our results show that JAMES significantly outperforms the best baseline by 10.06% in Precision@10 and by 17.52% in NDCG@10, respectively.
MathBERT: A Pre-trained Language Model for General NLP Tasks in Mathematics Education
Jun 02, 2021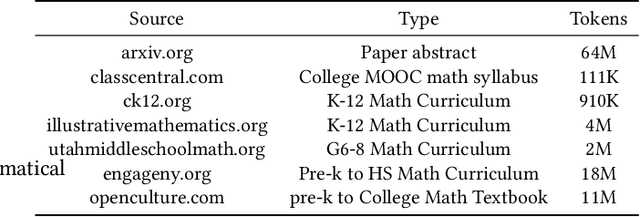
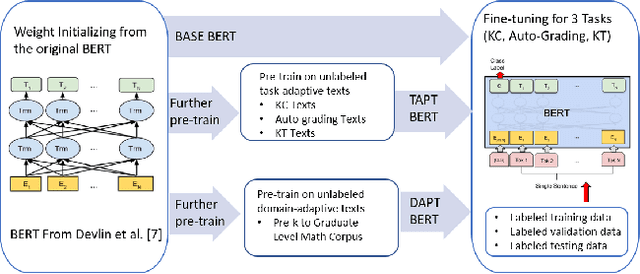
Due to the transfer learning nature of BERT model, researchers have achieved better performance than base BERT by further pre-training the original BERT on a huge domain-specific corpus. Due to the special nature of mathematical texts which often contain math equations and symbols, the original BERT model pre-trained on general English context will not fit Natural Language Processing (NLP) tasks in mathematical education well. Therefore, we propose MathBERT, a BERT pre-trained on large mathematical corpus including pre-k to graduate level mathematical content to tackle math-specific tasks. In addition, We generate a customized mathematical vocabulary to pre-train with MathBERT and compare the performance to the MathBERT pre-trained with the original BERT vocabulary. We select three important tasks in mathematical education such as knowledge component, auto-grading, and knowledge tracing prediction to evaluate the performance of MathBERT. Our experiments show that MathBERT outperforms the base BERT by 2-9\% margin. In some cases, MathBERT pre-trained with mathematical vocabulary is better than MathBERT trained with original vocabulary.To our best knowledge, MathBERT is the first pre-trained model for general purpose mathematics education tasks.
Classifying Math KCs via Task-Adaptive Pre-Trained BERT
May 24, 2021
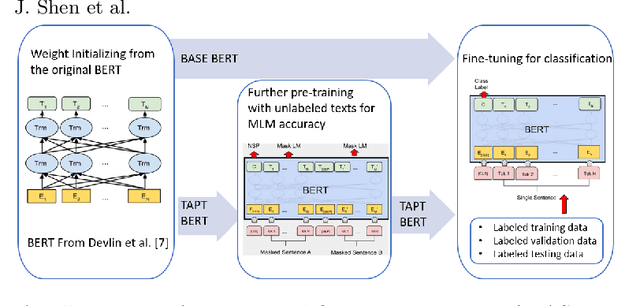
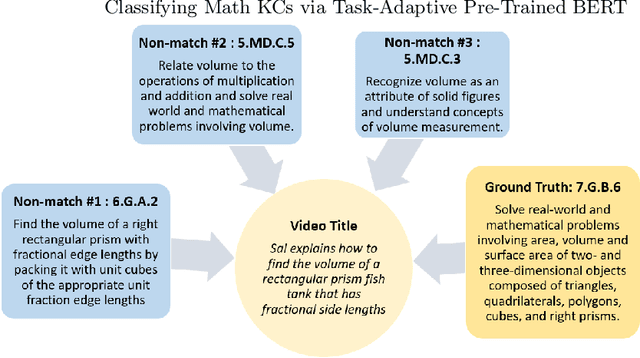
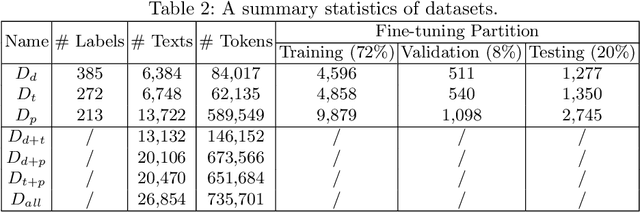
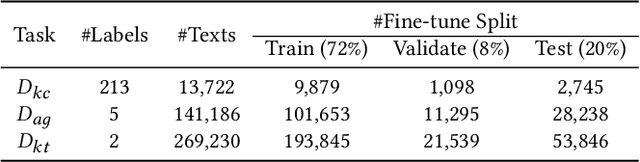
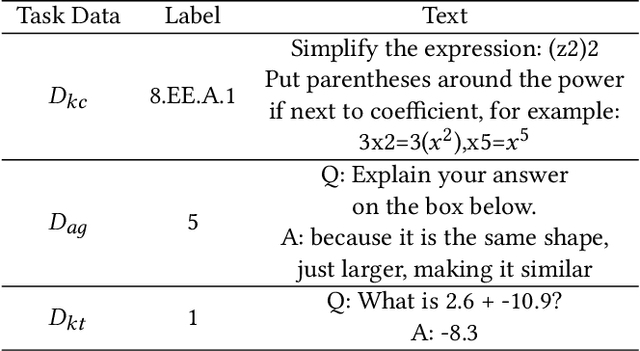
Educational content labeled with proper knowledge components (KCs) are particularly useful to teachers or content organizers. However, manually labeling educational content is labor intensive and error-prone. To address this challenge, prior research proposed machine learning based solutions to auto-label educational content with limited success. In this work, we significantly improve prior research by (1) expanding the input types to include KC descriptions, instructional video titles, and problem descriptions (i.e., three types of prediction task), (2) doubling the granularity of the prediction from 198 to 385 KC labels (i.e., more practical setting but much harder multinomial classification problem), (3) improving the prediction accuracies by 0.5-2.3% using Task-adaptive Pre-trained BERT, outperforming six baselines, and (4) proposing a simple evaluation measure by which we can recover 56-73% of mispredicted KC labels. All codes and data sets in the experiments are available at:https://github.com/tbs17/TAPT-BERT