 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImputing Knowledge Tracing Data with Subject-Based Training via LSTM Variational Autoencoders Frameworks
Feb 24, 2023The issue of missing data poses a great challenge on boosting performance and application of deep learning models in the {\em Knowledge Tracing} (KT) problem. However, there has been the lack of understanding on the issue in the literature. %are not sufficient studies tackling this problem. In this work, to address this challenge, we adopt a subject-based training method to split and impute data by student IDs instead of row number splitting which we call non-subject based training. The benefit of subject-based training can retain the complete sequence for each student and hence achieve efficient training. Further, we leverage two existing deep generative frameworks, namely variational Autoencoders (VAE) and Longitudinal Variational Autoencoders (LVAE) frameworks and build LSTM kernels into them to form LSTM-VAE and LSTM LVAE (noted as VAE and LVAE for simplicity) models to generate quality data. In LVAE, a Gaussian Process (GP) model is trained to disentangle the correlation between the subject (i.e., student) descriptor information (e.g., age, gender) and the latent space. The paper finally compare the model performance between training the original data and training the data imputed with generated data from non-subject based model VAE-NS and subject-based training models (i.e., VAE and LVAE). We demonstrate that the generated data from LSTM-VAE and LSTM-LVAE can boost the original model performance by about 50%. Moreover, the original model just needs 10% more student data to surpass the original performance if the prediction model is small and 50\% more data if the prediction model is large with our proposed frameworks.
JAMES: Job Title Mapping with Multi-Aspect Embeddings and Reasoning
Feb 22, 2022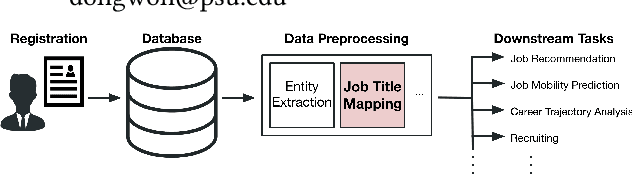



One of the most essential tasks needed for various downstream tasks in career analytics (e.g., career trajectory analysis, job mobility prediction, and job recommendation) is Job Title Mapping (JTM), where the goal is to map user-created (noisy and non-standard) job titles to predefined and standard job titles. However, solving JTM is domain-specific and non-trivial due to its inherent challenges: (1) user-created job titles are messy, (2) different job titles often overlap their job requirements, (3) job transition trajectories are inconsistent, and (4) the number of job titles in real world applications is large-scale. Toward this JTM problem, in this work, we propose a novel solution, named as JAMES, that constructs three unique embeddings of a target job title: topological, semantic, and syntactic embeddings, together with multi-aspect co-attention. In addition, we employ logical reasoning representations to collaboratively estimate similarities between messy job titles and standard job titles in the reasoning space. We conduct comprehensive experiments against ten competing models on the large-scale real-world dataset with more than 350,000 job titles. Our results show that JAMES significantly outperforms the best baseline by 10.06% in Precision@10 and by 17.52% in NDCG@10, respectively.
MathBERT: A Pre-trained Language Model for General NLP Tasks in Mathematics Education
Jun 02, 2021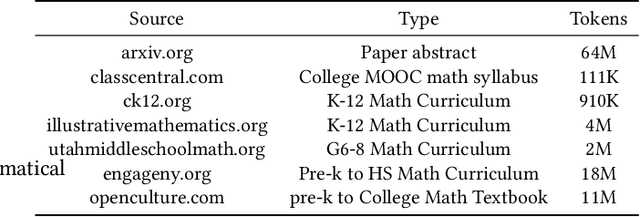
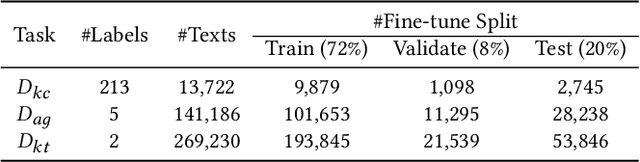
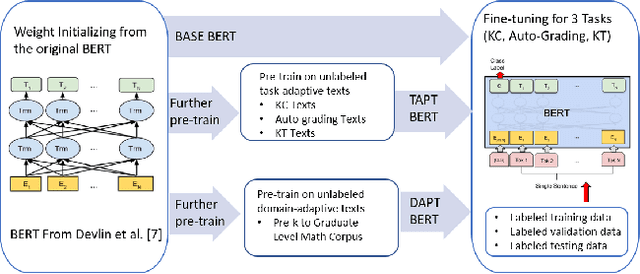
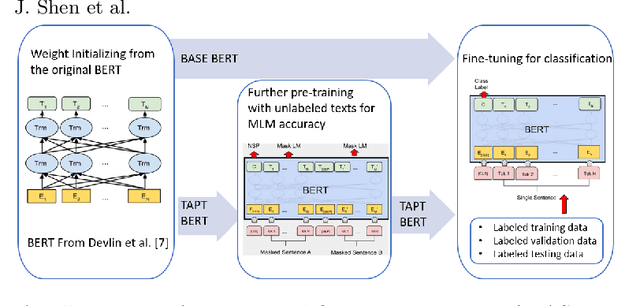
Due to the transfer learning nature of BERT model, researchers have achieved better performance than base BERT by further pre-training the original BERT on a huge domain-specific corpus. Due to the special nature of mathematical texts which often contain math equations and symbols, the original BERT model pre-trained on general English context will not fit Natural Language Processing (NLP) tasks in mathematical education well. Therefore, we propose MathBERT, a BERT pre-trained on large mathematical corpus including pre-k to graduate level mathematical content to tackle math-specific tasks. In addition, We generate a customized mathematical vocabulary to pre-train with MathBERT and compare the performance to the MathBERT pre-trained with the original BERT vocabulary. We select three important tasks in mathematical education such as knowledge component, auto-grading, and knowledge tracing prediction to evaluate the performance of MathBERT. Our experiments show that MathBERT outperforms the base BERT by 2-9\% margin. In some cases, MathBERT pre-trained with mathematical vocabulary is better than MathBERT trained with original vocabulary.To our best knowledge, MathBERT is the first pre-trained model for general purpose mathematics education tasks.
Classifying Math KCs via Task-Adaptive Pre-Trained BERT
May 24, 2021
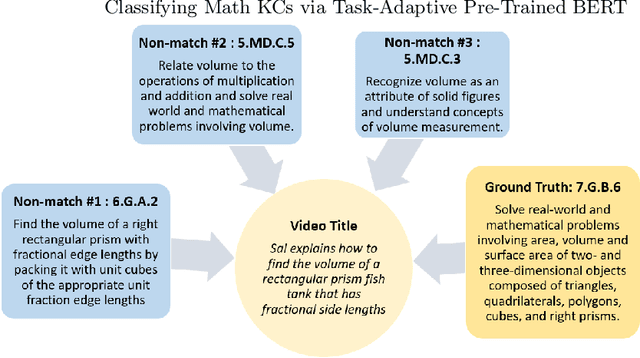
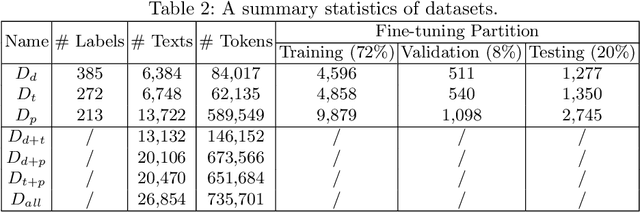
Educational content labeled with proper knowledge components (KCs) are particularly useful to teachers or content organizers. However, manually labeling educational content is labor intensive and error-prone. To address this challenge, prior research proposed machine learning based solutions to auto-label educational content with limited success. In this work, we significantly improve prior research by (1) expanding the input types to include KC descriptions, instructional video titles, and problem descriptions (i.e., three types of prediction task), (2) doubling the granularity of the prediction from 198 to 385 KC labels (i.e., more practical setting but much harder multinomial classification problem), (3) improving the prediction accuracies by 0.5-2.3% using Task-adaptive Pre-trained BERT, outperforming six baselines, and (4) proposing a simple evaluation measure by which we can recover 56-73% of mispredicted KC labels. All codes and data sets in the experiments are available at:https://github.com/tbs17/TAPT-BERT