 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Generalizable Representations of Mathematical Strategies
Apr 09, 2026Pretrained encoders for mathematical texts have achieved significant improvements on various tasks such as formula classification and information retrieval. Yet they remain limited in representing and capturing student strategies for entire solution pathways. Previously, this has been accomplished either through labor-intensive manual labeling, which does not scale, or by learning representations tied to platform-specific actions, which limits generalizability. In this work, we present a novel approach for learning problem-invariant representations of entire algebraic solution pathways. We first construct transition embeddings by computing vector differences between consecutive algebraic states encoded by high-capacity pretrained models, emphasizing transformations rather than problem-specific features. Sequence-level embeddings are then learned via SimCSE, using contrastive objectives to position semantically similar solution pathways close in embedding space while separating dissimilar strategies. We evaluate these embeddings through multiple tasks, including multi-label action classification, solution efficiency prediction, and sequence reconstruction, and demonstrate their capacity to encode meaningful strategy information. Furthermore, we derive embedding-based measures of strategy uniqueness, diversity, and conformity that correlate with both short-term and distal learning outcomes, providing scalable proxies for mathematical creativity and divergent thinking. This approach facilitates platform-agnostic and cross-problem analyses of student problem-solving behaviors, demonstrating the effectiveness of transition-based sequence embeddings for educational data mining and automated assessment.
MathBERT: A Pre-trained Language Model for General NLP Tasks in Mathematics Education
Jun 02, 2021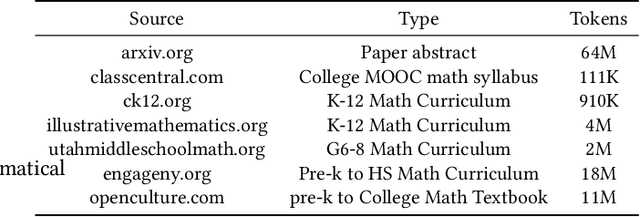
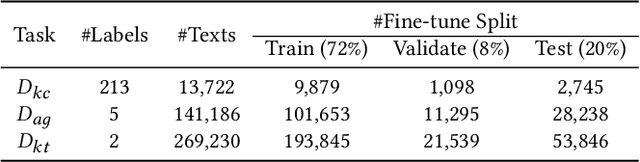
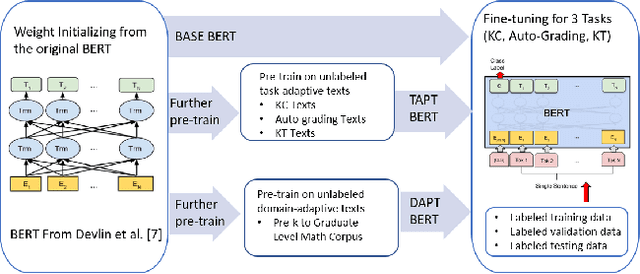
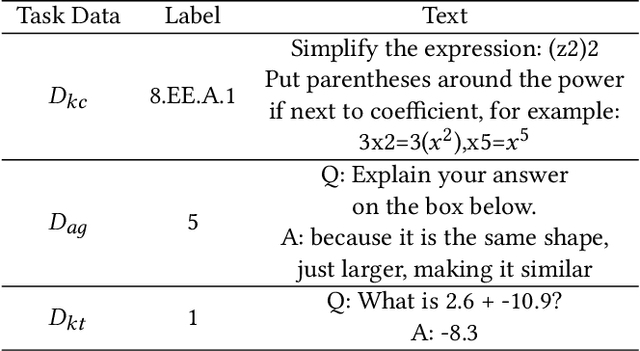
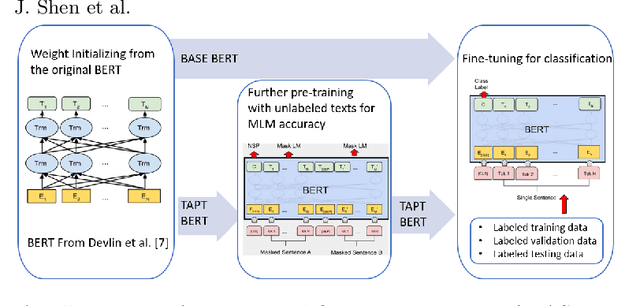
Due to the transfer learning nature of BERT model, researchers have achieved better performance than base BERT by further pre-training the original BERT on a huge domain-specific corpus. Due to the special nature of mathematical texts which often contain math equations and symbols, the original BERT model pre-trained on general English context will not fit Natural Language Processing (NLP) tasks in mathematical education well. Therefore, we propose MathBERT, a BERT pre-trained on large mathematical corpus including pre-k to graduate level mathematical content to tackle math-specific tasks. In addition, We generate a customized mathematical vocabulary to pre-train with MathBERT and compare the performance to the MathBERT pre-trained with the original BERT vocabulary. We select three important tasks in mathematical education such as knowledge component, auto-grading, and knowledge tracing prediction to evaluate the performance of MathBERT. Our experiments show that MathBERT outperforms the base BERT by 2-9\% margin. In some cases, MathBERT pre-trained with mathematical vocabulary is better than MathBERT trained with original vocabulary.To our best knowledge, MathBERT is the first pre-trained model for general purpose mathematics education tasks.
Classifying Math KCs via Task-Adaptive Pre-Trained BERT
May 24, 2021
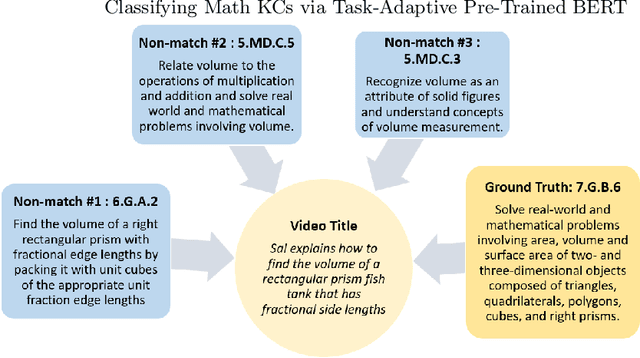
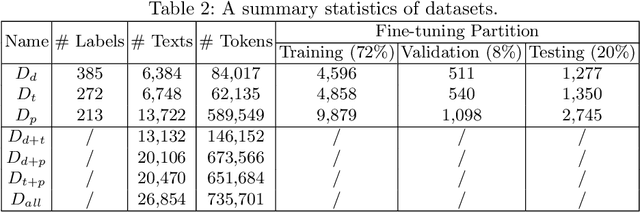
Educational content labeled with proper knowledge components (KCs) are particularly useful to teachers or content organizers. However, manually labeling educational content is labor intensive and error-prone. To address this challenge, prior research proposed machine learning based solutions to auto-label educational content with limited success. In this work, we significantly improve prior research by (1) expanding the input types to include KC descriptions, instructional video titles, and problem descriptions (i.e., three types of prediction task), (2) doubling the granularity of the prediction from 198 to 385 KC labels (i.e., more practical setting but much harder multinomial classification problem), (3) improving the prediction accuracies by 0.5-2.3% using Task-adaptive Pre-trained BERT, outperforming six baselines, and (4) proposing a simple evaluation measure by which we can recover 56-73% of mispredicted KC labels. All codes and data sets in the experiments are available at:https://github.com/tbs17/TAPT-BERT