 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Karp Dataset
Jan 24, 2025Understanding the mathematical reasoning capabilities of Large Language Models (LLMs) is a central topic in the study of artificial intelligence. This new domain necessitates the creation of datasets of reasoning tasks for both training and benchmarking the performance of LLMs. To this end, we introduce the Karp dataset: The first dataset composed of detailed proofs of NP-completeness reductions. The reductions vary in difficulty, ranging from simple exercises of undergraduate courses to more challenging reductions from academic papers. We compare the performance of state-of-the-art models on this task and demonstrate the effect of fine-tuning with the Karp dataset on reasoning capacity.
Modeling and Analyzing Scorer Preferences in Short-Answer Math Questions
Jun 01, 2023Automated scoring of student responses to open-ended questions, including short-answer questions, has great potential to scale to a large number of responses. Recent approaches for automated scoring rely on supervised learning, i.e., training classifiers or fine-tuning language models on a small number of responses with human-provided score labels. However, since scoring is a subjective process, these human scores are noisy and can be highly variable, depending on the scorer. In this paper, we investigate a collection of models that account for the individual preferences and tendencies of each human scorer in the automated scoring task. We apply these models to a short-answer math response dataset where each response is scored (often differently) by multiple different human scorers. We conduct quantitative experiments to show that our scorer models lead to improved automated scoring accuracy. We also conduct quantitative experiments and case studies to analyze the individual preferences and tendencies of scorers. We found that scorers can be grouped into several obvious clusters, with each cluster having distinct features, and analyzed them in detail.
Automatic Short Math Answer Grading via In-context Meta-learning
May 30, 2022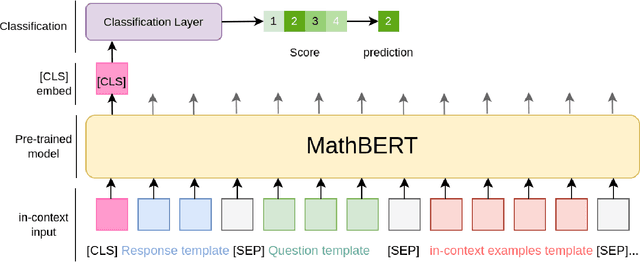


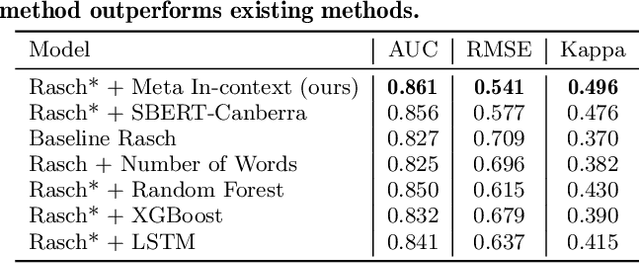
Automatic short answer grading is an important research direction in the exploration of how to use artificial intelligence (AI)-based tools to improve education. Current state-of-the-art approaches use neural language models to create vectorized representations of students responses, followed by classifiers to predict the score. However, these approaches have several key limitations, including i) they use pre-trained language models that are not well-adapted to educational subject domains and/or student-generated text and ii) they almost always train one model per question, ignoring the linkage across a question and result in a significant model storage problem due to the size of advanced language models. In this paper, we study the problem of automatic short answer grading for students' responses to math questions and propose a novel framework for this task. First, we use MathBERT, a variant of the popular language model BERT adapted to mathematical content, as our base model and fine-tune it for the downstream task of student response grading. Second, we use an in-context learning approach that provides scoring examples as input to the language model to provide additional context information and promote generalization to previously unseen questions. We evaluate our framework on a real-world dataset of student responses to open-ended math questions and show that our framework (often significantly) outperforms existing approaches, especially for new questions that are not seen during training.
MathBERT: A Pre-trained Language Model for General NLP Tasks in Mathematics Education
Jun 02, 2021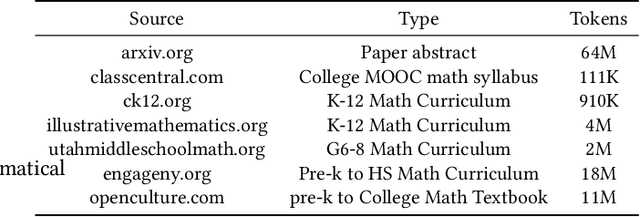
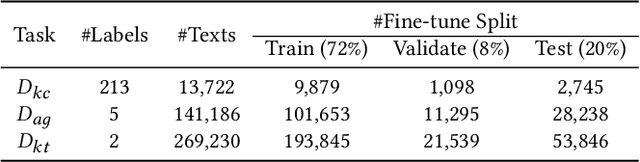
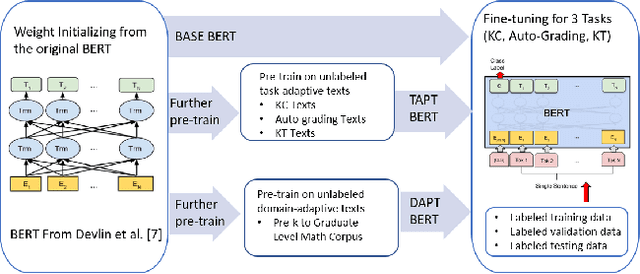
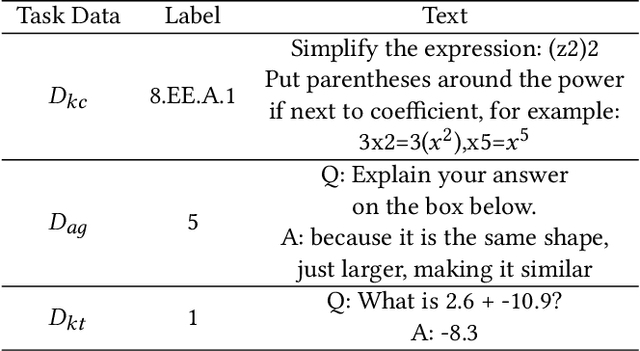
Due to the transfer learning nature of BERT model, researchers have achieved better performance than base BERT by further pre-training the original BERT on a huge domain-specific corpus. Due to the special nature of mathematical texts which often contain math equations and symbols, the original BERT model pre-trained on general English context will not fit Natural Language Processing (NLP) tasks in mathematical education well. Therefore, we propose MathBERT, a BERT pre-trained on large mathematical corpus including pre-k to graduate level mathematical content to tackle math-specific tasks. In addition, We generate a customized mathematical vocabulary to pre-train with MathBERT and compare the performance to the MathBERT pre-trained with the original BERT vocabulary. We select three important tasks in mathematical education such as knowledge component, auto-grading, and knowledge tracing prediction to evaluate the performance of MathBERT. Our experiments show that MathBERT outperforms the base BERT by 2-9\% margin. In some cases, MathBERT pre-trained with mathematical vocabulary is better than MathBERT trained with original vocabulary.To our best knowledge, MathBERT is the first pre-trained model for general purpose mathematics education tasks.
Classifying Math KCs via Task-Adaptive Pre-Trained BERT
May 24, 2021
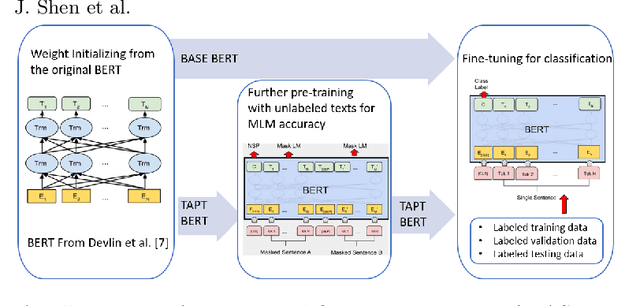
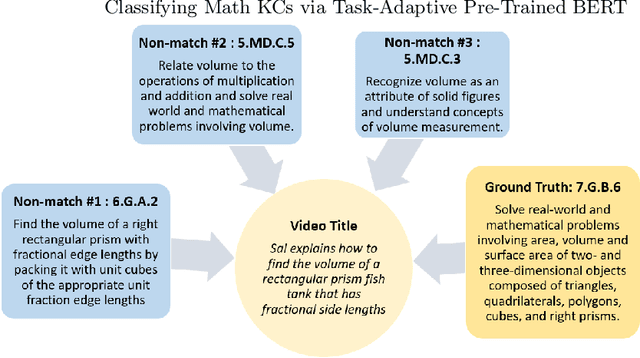
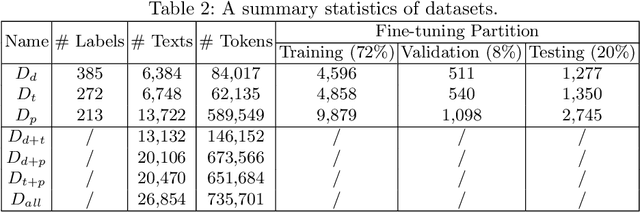
Educational content labeled with proper knowledge components (KCs) are particularly useful to teachers or content organizers. However, manually labeling educational content is labor intensive and error-prone. To address this challenge, prior research proposed machine learning based solutions to auto-label educational content with limited success. In this work, we significantly improve prior research by (1) expanding the input types to include KC descriptions, instructional video titles, and problem descriptions (i.e., three types of prediction task), (2) doubling the granularity of the prediction from 198 to 385 KC labels (i.e., more practical setting but much harder multinomial classification problem), (3) improving the prediction accuracies by 0.5-2.3% using Task-adaptive Pre-trained BERT, outperforming six baselines, and (4) proposing a simple evaluation measure by which we can recover 56-73% of mispredicted KC labels. All codes and data sets in the experiments are available at:https://github.com/tbs17/TAPT-BERT
Achieving User-Side Fairness in Contextual Bandits
Oct 22, 2020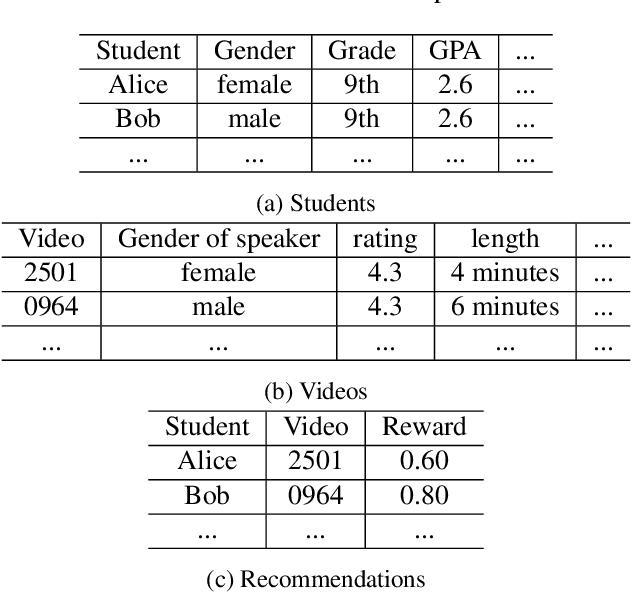
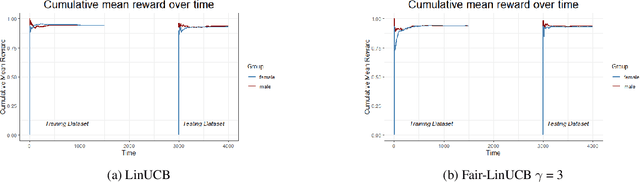
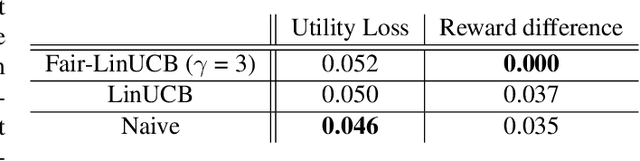
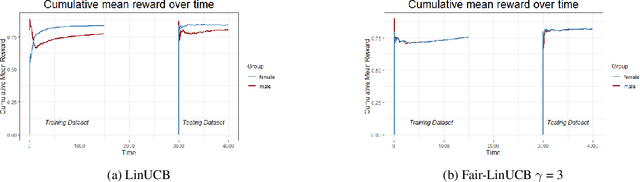
Personalized recommendation based on multi-arm bandit (MAB) algorithms has shown to lead to high utility and efficiency as it can dynamically adapt the recommendation strategy based on feedback. However, unfairness could incur in personalized recommendation. In this paper, we study how to achieve user-side fairness in personalized recommendation. We formulate our fair personalized recommendation as a modified contextual bandit and focus on achieving fairness on the individual whom is being recommended an item as opposed to achieving fairness on the items that are being recommended. We introduce and define a metric that captures the fairness in terms of rewards received for both the privileged and protected groups. We develop a fair contextual bandit algorithm, Fair-LinUCB, that improves upon the traditional LinUCB algorithm to achieve group-level fairness of users. Our algorithm detects and monitors unfairness while it learns to recommend personalized videos to students to achieve high efficiency. We provide a theoretical regret analysis and show that our algorithm has a slightly higher regret bound than LinUCB. We conduct numerous experimental evaluations to compare the performances of our fair contextual bandit to that of LinUCB and show that our approach achieves group-level fairness while maintaining a high utility.
Context-Aware Attentive Knowledge Tracing
Jul 24, 2020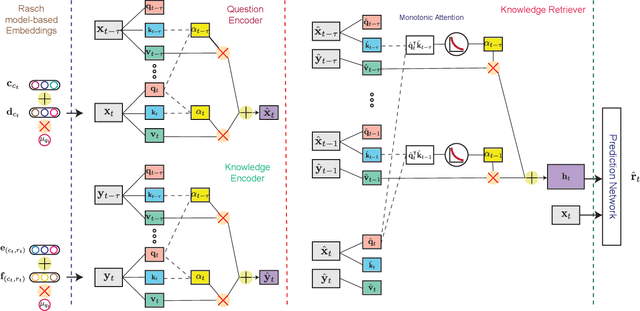

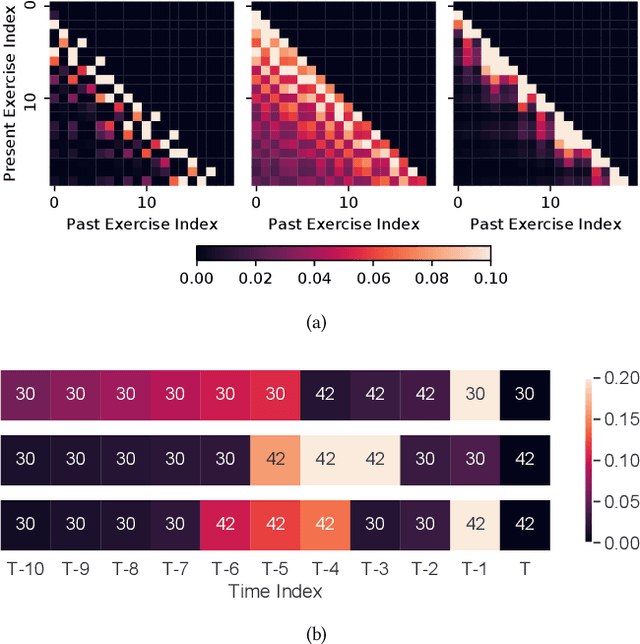
Knowledge tracing (KT) refers to the problem of predicting future learner performance given their past performance in educational applications. Recent developments in KT using flexible deep neural network-based models excel at this task. However, these models often offer limited interpretability, thus making them insufficient for personalized learning, which requires using interpretable feedback and actionable recommendations to help learners achieve better learning outcomes. In this paper, we propose attentive knowledge tracing (AKT), which couples flexible attention-based neural network models with a series of novel, interpretable model components inspired by cognitive and psychometric models. AKT uses a novel monotonic attention mechanism that relates a learner's future responses to assessment questions to their past responses; attention weights are computed using exponential decay and a context-aware relative distance measure, in addition to the similarity between questions. Moreover, we use the Rasch model to regularize the concept and question embeddings; these embeddings are able to capture individual differences among questions on the same concept without using an excessive number of parameters. We conduct experiments on several real-world benchmark datasets and show that AKT outperforms existing KT methods (by up to $6\%$ in AUC in some cases) on predicting future learner responses. We also conduct several case studies and show that AKT exhibits excellent interpretability and thus has potential for automated feedback and personalization in real-world educational settings.