 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRL-VLA$^3$: Reinforcement Learning VLA Accelerating via Full Asynchronism
Feb 05, 2026In recent years, Vision-Language-Action (VLA) models have emerged as a crucial pathway towards general embodied intelligence, yet their training efficiency has become a key bottleneck. Although existing reinforcement learning (RL)-based training frameworks like RLinf can enhance model generalization, they still rely on synchronous execution, leading to severe resource underutilization and throughput limitations during environment interaction, policy generation (rollout), and model update phases (actor). To overcome this challenge, this paper, for the first time, proposes and implements a fully-asynchronous policy training framework encompassing the entire pipeline from environment interaction, rollout generation, to actor policy updates. Systematically drawing inspiration from asynchronous optimization ideas in large model RL, our framework designs a multi-level decoupled architecture. This includes asynchronous parallelization of environment interaction and trajectory collection, streaming execution for policy generation, and decoupled scheduling for training updates. We validated the effectiveness of our method across diverse VLA models and environments. On the LIBERO benchmark, the framework achieves throughput improvements of up to 59.25\% compared to existing synchronous strategies. When deeply optimizing separation strategies, throughput can be increased by as much as 126.67\%. We verified the effectiveness of each asynchronous component via ablation studies. Scaling law validation across 8 to 256 GPUs demonstrates our method's excellent scalability under most conditions.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
A Data-Centric Approach to Generalizable Speech Deepfake Detection
Dec 24, 2025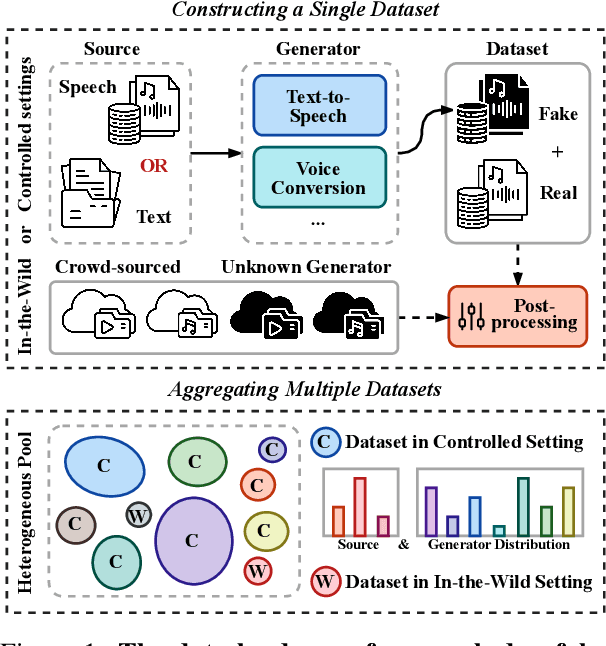
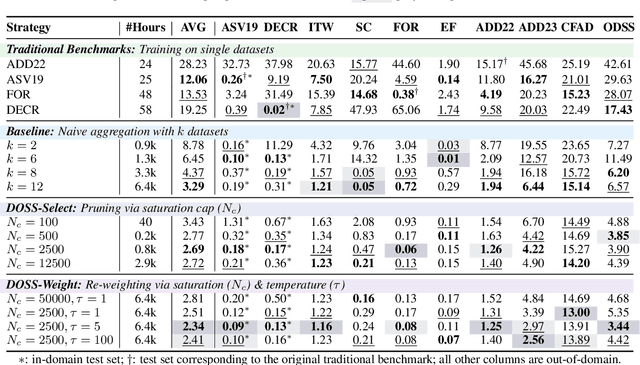
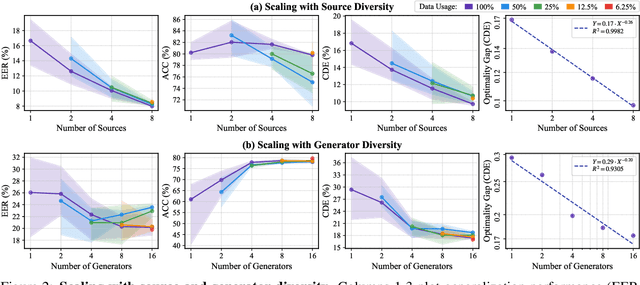
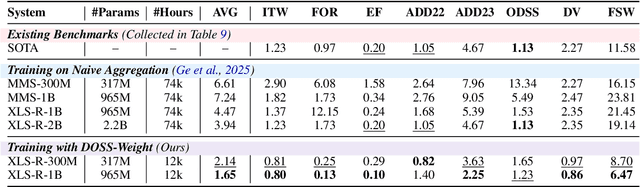
Achieving robust generalization in speech deepfake detection (SDD) remains a primary challenge, as models often fail to detect unseen forgery methods. While research has focused on model-centric and algorithm-centric solutions, the impact of data composition is often underexplored. This paper proposes a data-centric approach, analyzing the SDD data landscape from two practical perspectives: constructing a single dataset and aggregating multiple datasets. To address the first perspective, we conduct a large-scale empirical study to characterize the data scaling laws for SDD, quantifying the impact of source and generator diversity. To address the second, we propose the Diversity-Optimized Sampling Strategy (DOSS), a principled framework for mixing heterogeneous data with two implementations: DOSS-Select (pruning) and DOSS-Weight (re-weighting). Our experiments show that DOSS-Select outperforms the naive aggregation baseline while using only 3% of the total available data. Furthermore, our final model, trained on a 12k-hour curated data pool using the optimal DOSS-Weight strategy, achieves state-of-the-art performance, outperforming large-scale baselines with greater data and model efficiency on both public benchmarks and a new challenge set of various commercial APIs.
Improving Deepfake Detection with Reinforcement Learning-Based Adaptive Data Augmentation
Nov 10, 2025The generalization capability of deepfake detectors is critical for real-world use. Data augmentation via synthetic fake face generation effectively enhances generalization, yet current SoTA methods rely on fixed strategies-raising a key question: Is a single static augmentation sufficient, or does the diversity of forgery features demand dynamic approaches? We argue existing methods overlook the evolving complexity of real-world forgeries (e.g., facial warping, expression manipulation), which fixed policies cannot fully simulate. To address this, we propose CRDA (Curriculum Reinforcement-Learning Data Augmentation), a novel framework guiding detectors to progressively master multi-domain forgery features from simple to complex. CRDA synthesizes augmented samples via a configurable pool of forgery operations and dynamically generates adversarial samples tailored to the detector's current learning state. Central to our approach is integrating reinforcement learning (RL) and causal inference. An RL agent dynamically selects augmentation actions based on detector performance to efficiently explore the vast augmentation space, adapting to increasingly challenging forgeries. Simultaneously, the agent introduces action space variations to generate heterogeneous forgery patterns, guided by causal inference to mitigate spurious correlations-suppressing task-irrelevant biases and focusing on causally invariant features. This integration ensures robust generalization by decoupling synthetic augmentation patterns from the model's learned representations. Extensive experiments show our method significantly improves detector generalizability, outperforming SOTA methods across multiple cross-domain datasets.
From Sharpness to Better Generalization for Speech Deepfake Detection
Jun 13, 2025Generalization remains a critical challenge in speech deepfake detection (SDD). While various approaches aim to improve robustness, generalization is typically assessed through performance metrics like equal error rate without a theoretical framework to explain model performance. This work investigates sharpness as a theoretical proxy for generalization in SDD. We analyze how sharpness responds to domain shifts and find it increases in unseen conditions, indicating higher model sensitivity. Based on this, we apply Sharpness-Aware Minimization (SAM) to reduce sharpness explicitly, leading to better and more stable performance across diverse unseen test sets. Furthermore, correlation analysis confirms a statistically significant relationship between sharpness and generalization in most test settings. These findings suggest that sharpness can serve as a theoretical indicator for generalization in SDD and that sharpness-aware training offers a promising strategy for improving robustness.
Generalizable Audio Deepfake Detection via Latent Space Refinement and Augmentation
Jan 24, 2025Advances in speech synthesis technologies, like text-to-speech (TTS) and voice conversion (VC), have made detecting deepfake speech increasingly challenging. Spoofing countermeasures often struggle to generalize effectively, particularly when faced with unseen attacks. To address this, we propose a novel strategy that integrates Latent Space Refinement (LSR) and Latent Space Augmentation (LSA) to improve the generalization of deepfake detection systems. LSR introduces multiple learnable prototypes for the spoof class, refining the latent space to better capture the intricate variations within spoofed data. LSA further diversifies spoofed data representations by applying augmentation techniques directly in the latent space, enabling the model to learn a broader range of spoofing patterns. We evaluated our approach on four representative datasets, i.e. ASVspoof 2019 LA, ASVspoof 2021 LA and DF, and In-The-Wild. The results show that LSR and LSA perform well individually, and their integration achieves competitive results, matching or surpassing current state-of-the-art methods.
Prototype and Instance Contrastive Learning for Unsupervised Domain Adaptation in Speaker Verification
Oct 22, 2024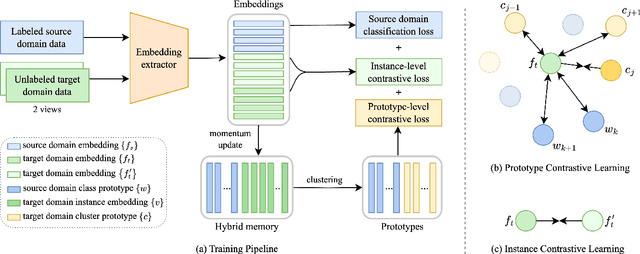
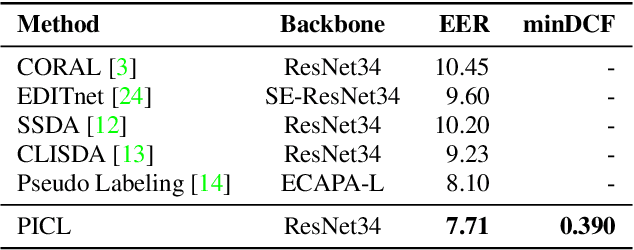
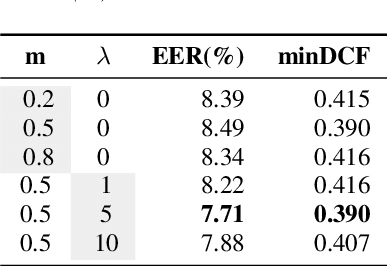
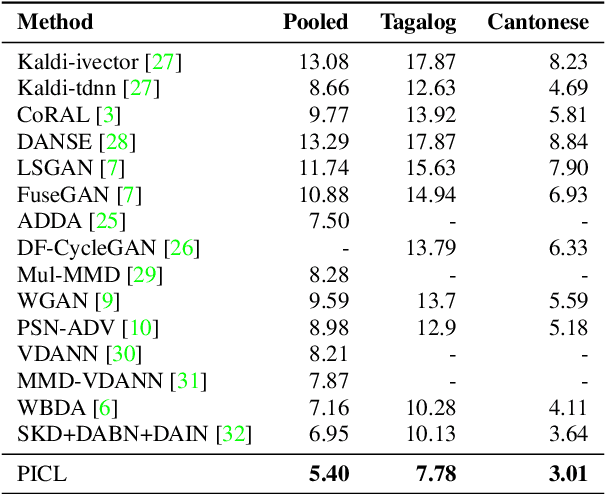
Speaker verification system trained on one domain usually suffers performance degradation when applied to another domain. To address this challenge, researchers commonly use feature distribution matching-based methods in unsupervised domain adaptation scenarios where some unlabeled target domain data is available. However, these methods often have limited performance improvement and lack generalization in various mismatch situations. In this paper, we propose Prototype and Instance Contrastive Learning (PICL), a novel method for unsupervised domain adaptation in speaker verification through dual-level contrastive learning. For prototype contrastive learning, we generate pseudo labels via clustering to create dynamically updated prototype representations, aligning instances with their corresponding class or cluster prototypes. For instance contrastive learning, we minimize the distance between different views or augmentations of the same instance, ensuring robust and invariant representations resilient to variations like noise. This dual-level approach provides both high-level and low-level supervision, leading to improved generalization and robustness of the speaker verification model. Unlike previous studies that only evaluated mismatches in one situation, we have conducted relevant explorations on various datasets and achieved state-of-the-art performance currently, which also proves the generalization of our method.
Unified Audio Event Detection
Sep 13, 2024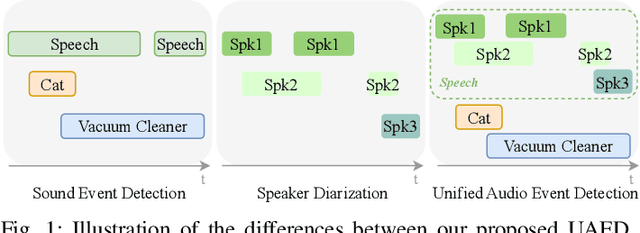
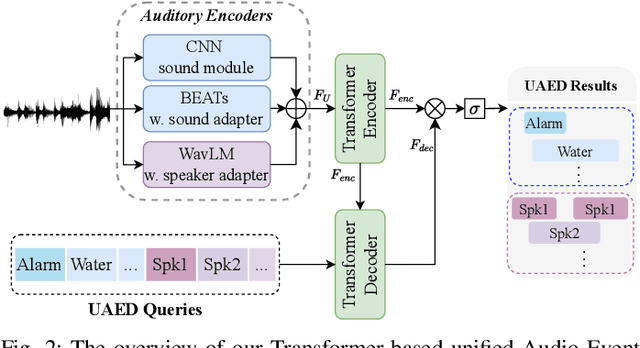
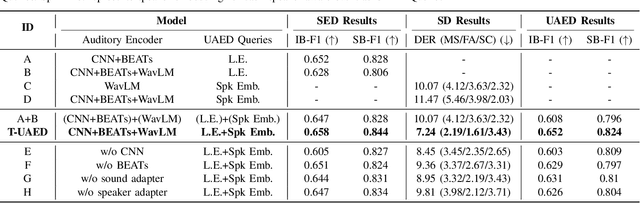
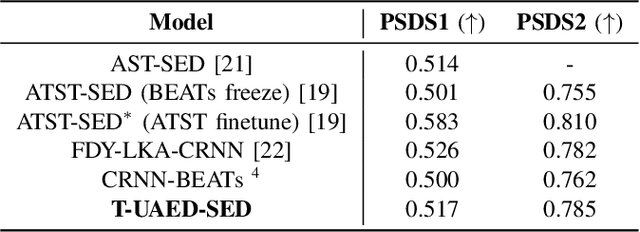
Sound Event Detection (SED) detects regions of sound events, while Speaker Diarization (SD) segments speech conversations attributed to individual speakers. In SED, all speaker segments are classified as a single speech event, while in SD, non-speech sounds are treated merely as background noise. Thus, both tasks provide only partial analysis in complex audio scenarios involving both speech conversation and non-speech sounds. In this paper, we introduce a novel task called Unified Audio Event Detection (UAED) for comprehensive audio analysis. UAED explores the synergy between SED and SD tasks, simultaneously detecting non-speech sound events and fine-grained speech events based on speaker identities. To tackle this task, we propose a Transformer-based UAED (T-UAED) framework and construct the UAED Data derived from the Librispeech dataset and DESED soundbank. Experiments demonstrate that the proposed framework effectively exploits task interactions and substantially outperforms the baseline that simply combines the outputs of SED and SD models. T-UAED also shows its versatility by performing comparably to specialized models for individual SED and SD tasks on DESED and CALLHOME datasets.
Riemannian Federated Learning via Averaging Gradient Stream
Sep 11, 2024In recent years, federated learning has garnered significant attention as an efficient and privacy-preserving distributed learning paradigm. In the Euclidean setting, Federated Averaging (FedAvg) and its variants are a class of efficient algorithms for expected (empirical) risk minimization. This paper develops and analyzes a Riemannian Federated Averaging Gradient Stream (RFedAGS) algorithm, which is a generalization of FedAvg, to problems defined on a Riemannian manifold. Under standard assumptions, the convergence rate of RFedAGS with fixed step sizes is proven to be sublinear for an approximate stationary solution. If decaying step sizes are used, the global convergence is established. Furthermore, assuming that the objective obeys the Riemannian Polyak-{\L}ojasiewicz property, the optimal gaps generated by RFedAGS with fixed step size are linearly decreasing up to a tiny upper bound, meanwhile, if decaying step sizes are used, then the gaps sublinearly vanish. Numerical simulations conducted on synthetic and real-world data demonstrate the performance of the proposed RFedAGS.
Visual Hallucinations of Multi-modal Large Language Models
Feb 22, 2024



Visual hallucination (VH) means that a multi-modal LLM (MLLM) imagines incorrect details about an image in visual question answering. Existing studies find VH instances only in existing image datasets, which results in biased understanding of MLLMs' performance under VH due to limited diversity of such VH instances. In this work, we propose a tool called VHTest to generate a diverse set of VH instances. Specifically, VHTest finds some initial VH instances in existing image datasets (e.g., COCO), generates a text description for each VH mode, and uses a text-to-image generative model (e.g., DALL-E-3) to generate VH images based on the text descriptions. We collect a benchmark dataset with 1,200 VH instances in 8 VH modes using VHTest. We find that existing MLLMs such as GPT-4V, LLaVA-1.5, and MiniGPT-v2 hallucinate for a large fraction of the instances in our benchmark. Moreover, we find that fine-tuning an MLLM using our benchmark dataset reduces its likelihood to hallucinate without sacrificing its performance on other benchmarks. Our benchmarks are publicly available: https://github.com/wenhuang2000/VHTest.