 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplitMeanFlow: Interval Splitting Consistency in Few-Step Generative Modeling
Jul 22, 2025


Generative models like Flow Matching have achieved state-of-the-art performance but are often hindered by a computationally expensive iterative sampling process. To address this, recent work has focused on few-step or one-step generation by learning the average velocity field, which directly maps noise to data. MeanFlow, a leading method in this area, learns this field by enforcing a differential identity that connects the average and instantaneous velocities. In this work, we argue that this differential formulation is a limiting special case of a more fundamental principle. We return to the first principles of average velocity and leverage the additivity property of definite integrals. This leads us to derive a novel, purely algebraic identity we term Interval Splitting Consistency. This identity establishes a self-referential relationship for the average velocity field across different time intervals without resorting to any differential operators. Based on this principle, we introduce SplitMeanFlow, a new training framework that enforces this algebraic consistency directly as a learning objective. We formally prove that the differential identity at the core of MeanFlow is recovered by taking the limit of our algebraic consistency as the interval split becomes infinitesimal. This establishes SplitMeanFlow as a direct and more general foundation for learning average velocity fields. From a practical standpoint, our algebraic approach is significantly more efficient, as it eliminates the need for JVP computations, resulting in simpler implementation, more stable training, and broader hardware compatibility. One-step and two-step SplitMeanFlow models have been successfully deployed in large-scale speech synthesis products (such as Doubao), achieving speedups of 20x.
Advanced Zero-Shot Text-to-Speech for Background Removal and Preservation with Controllable Masked Speech Prediction
Feb 11, 2025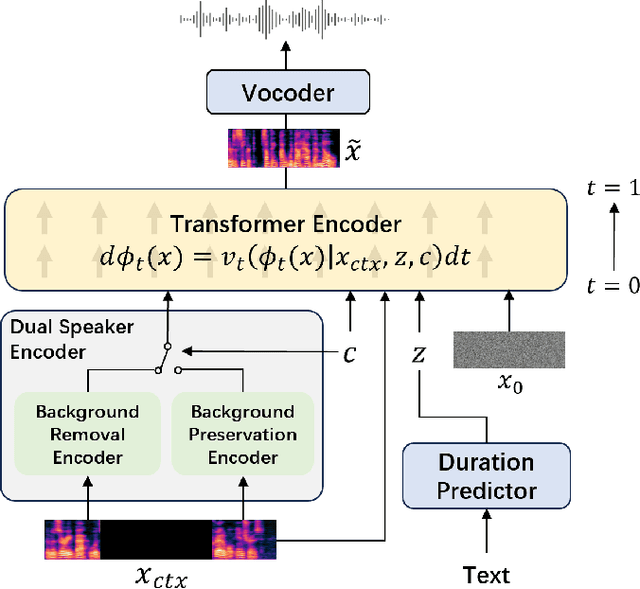
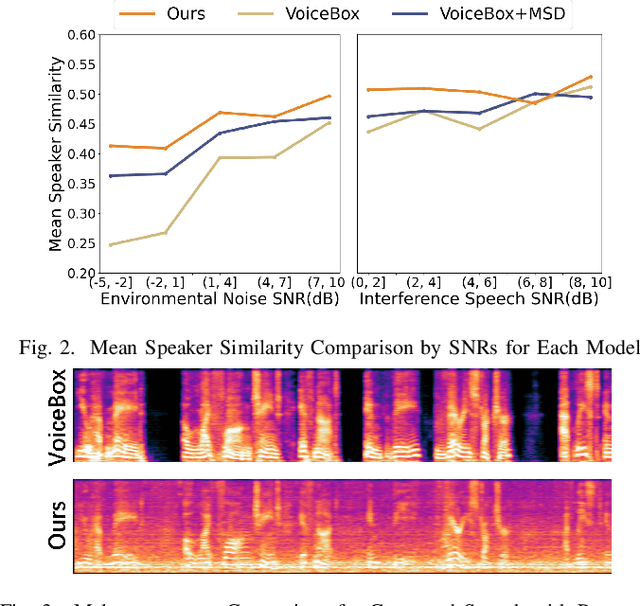


The acoustic background plays a crucial role in natural conversation. It provides context and helps listeners understand the environment, but a strong background makes it difficult for listeners to understand spoken words. The appropriate handling of these backgrounds is situation-dependent: Although it may be necessary to remove background to ensure speech clarity, preserving the background is sometimes crucial to maintaining the contextual integrity of the speech. Despite recent advancements in zero-shot Text-to-Speech technologies, current systems often struggle with speech prompts containing backgrounds. To address these challenges, we propose a Controllable Masked Speech Prediction strategy coupled with a dual-speaker encoder, utilizing a task-related control signal to guide the prediction of dual background removal and preservation targets. Experimental results demonstrate that our approach enables precise control over the removal or preservation of background across various acoustic conditions and exhibits strong generalization capabilities in unseen scenarios.
Prototype and Instance Contrastive Learning for Unsupervised Domain Adaptation in Speaker Verification
Oct 22, 2024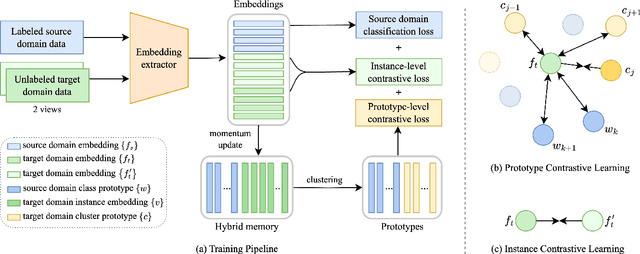
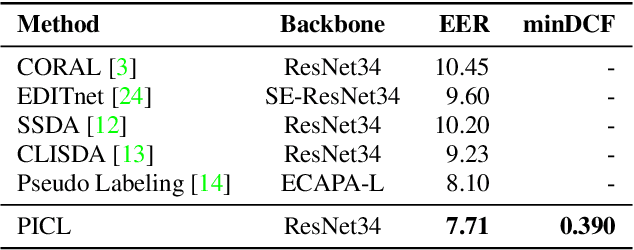
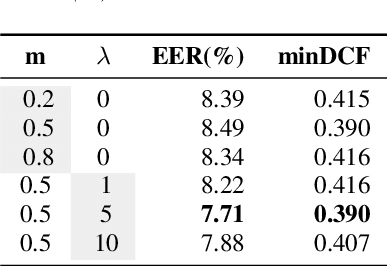
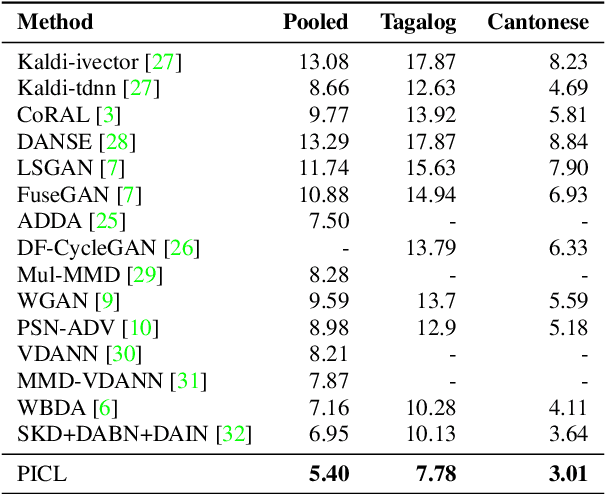
Speaker verification system trained on one domain usually suffers performance degradation when applied to another domain. To address this challenge, researchers commonly use feature distribution matching-based methods in unsupervised domain adaptation scenarios where some unlabeled target domain data is available. However, these methods often have limited performance improvement and lack generalization in various mismatch situations. In this paper, we propose Prototype and Instance Contrastive Learning (PICL), a novel method for unsupervised domain adaptation in speaker verification through dual-level contrastive learning. For prototype contrastive learning, we generate pseudo labels via clustering to create dynamically updated prototype representations, aligning instances with their corresponding class or cluster prototypes. For instance contrastive learning, we minimize the distance between different views or augmentations of the same instance, ensuring robust and invariant representations resilient to variations like noise. This dual-level approach provides both high-level and low-level supervision, leading to improved generalization and robustness of the speaker verification model. Unlike previous studies that only evaluated mismatches in one situation, we have conducted relevant explorations on various datasets and achieved state-of-the-art performance currently, which also proves the generalization of our method.
Disentangling the Prosody and Semantic Information with Pre-trained Model for In-Context Learning based Zero-Shot Voice Conversion
Sep 10, 2024Voice conversion (VC) aims to modify the speaker's timbre while retaining speech content. Previous approaches have tokenized the outputs from self-supervised into semantic tokens, facilitating disentanglement of speech content information. Recently, in-context learning (ICL) has emerged in text-to-speech (TTS) systems for effectively modeling specific characteristics such as timbre through context conditioning. This paper proposes an ICL capability enhanced VC system (ICL-VC) employing a mask and reconstruction training strategy based on flow-matching generative models. Augmented with semantic tokens, our experiments on the LibriTTS dataset demonstrate that ICL-VC improves speaker similarity. Additionally, we find that k-means is a versatile tokenization method applicable to various pre-trained models. However, the ICL-VC system faces challenges in preserving the prosody of the source speech. To mitigate this issue, we propose incorporating prosody embeddings extracted from a pre-trained emotion recognition model into our system. Integration of prosody embeddings notably enhances the system's capability to preserve source speech prosody, as validated on the Emotional Speech Database.
Flow-TSVAD: Target-Speaker Voice Activity Detection via Latent Flow Matching
Sep 07, 2024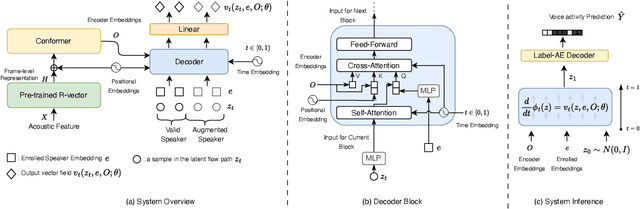

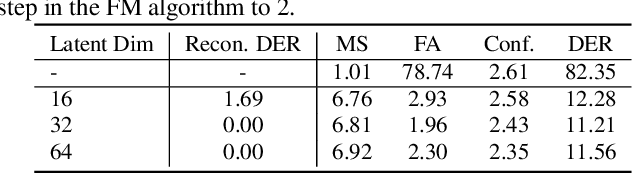
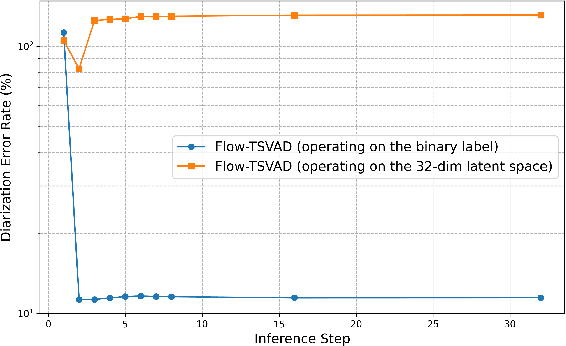
Speaker diarization is typically considered a discriminative task, using discriminative approaches to produce fixed diarization results. In this paper, we explore the use of neural network-based generative methods for speaker diarization for the first time. We implement a Flow-Matching (FM) based generative algorithm within the sequence-to-sequence target speaker voice activity detection (Seq2Seq-TSVAD) diarization system. Our experiments reveal that applying the generative method directly to the original binary label sequence space of the TS-VAD output is ineffective. To address this issue, we propose mapping the binary label sequence into a dense latent space before applying the generative algorithm and our proposed Flow-TSVAD method outperforms the Seq2Seq-TSVAD system. Additionally, we observe that the FM algorithm converges rapidly during the inference stage, requiring only two inference steps to achieve promising results. As a generative model, Flow-TSVAD allows for sampling different diarization results by running the model multiple times. Moreover, ensembling results from various sampling instances further enhances diarization performance.
Overview of Speaker Modeling and Its Applications: From the Lens of Deep Speaker Representation Learning
Jul 21, 2024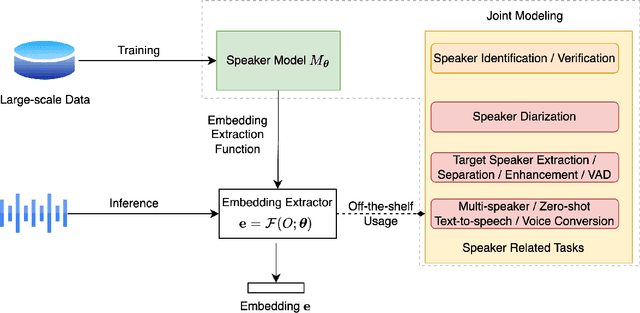
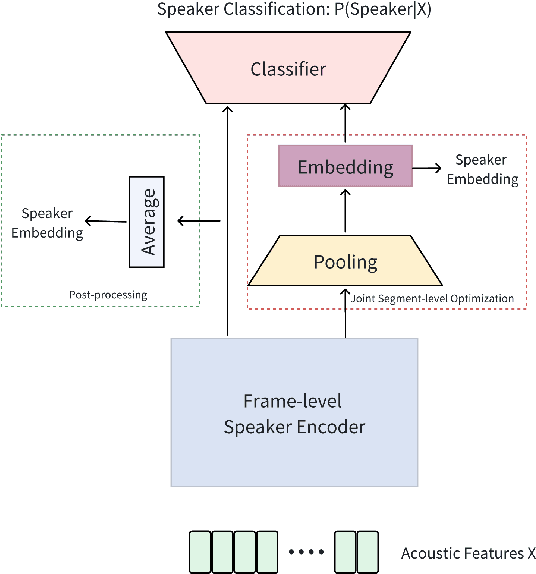
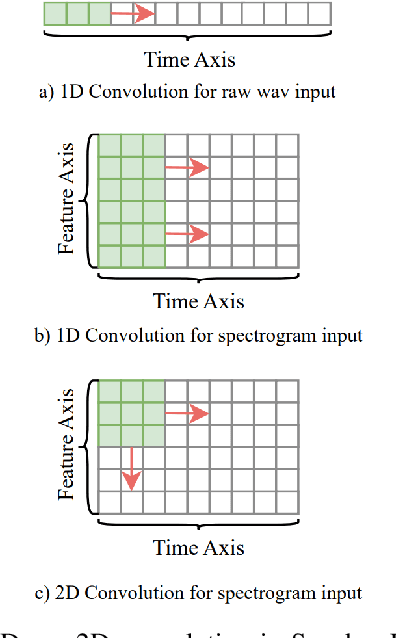
Speaker individuality information is among the most critical elements within speech signals. By thoroughly and accurately modeling this information, it can be utilized in various intelligent speech applications, such as speaker recognition, speaker diarization, speech synthesis, and target speaker extraction. In this article, we aim to present, from a unique perspective, the developmental history, paradigm shifts, and application domains of speaker modeling technologies within the context of deep representation learning framework. This review is designed to provide a clear reference for researchers in the speaker modeling field, as well as for those who wish to apply speaker modeling techniques to specific downstream tasks.
Generating Speakers by Prompting Listener Impressions for Pre-trained Multi-Speaker Text-to-Speech Systems
Jun 13, 2024



This paper proposes a speech synthesis system that allows users to specify and control the acoustic characteristics of a speaker by means of prompts describing the speaker's traits of synthesized speech. Unlike previous approaches, our method utilizes listener impressions to construct prompts, which are easier to collect and align more naturally with everyday descriptions of speaker traits. We adopt the Low-rank Adaptation (LoRA) technique to swiftly tailor a pre-trained language model to our needs, facilitating the extraction of speaker-related traits from the prompt text. Besides, different from other prompt-driven text-to-speech (TTS) systems, we separate the prompt-to-speaker module from the multi-speaker TTS system, enhancing system flexibility and compatibility with various pre-trained multi-speaker TTS systems. Moreover, for the prompt-to-speaker characteristic module, we also compared the discriminative method and flow-matching based generative method and we found that combining both methods can help the system simultaneously capture speaker-related information from prompts better and generate speech with higher fidelity.
Target Speech Diarization with Multimodal Prompts
Jun 11, 2024



Traditional speaker diarization seeks to detect ``who spoke when'' according to speaker characteristics. Extending to target speech diarization, we detect ``when target event occurs'' according to the semantic characteristics of speech. We propose a novel Multimodal Target Speech Diarization (MM-TSD) framework, which accommodates diverse and multi-modal prompts to specify target events in a flexible and user-friendly manner, including semantic language description, pre-enrolled speech, pre-registered face image, and audio-language logical prompts. We further propose a voice-face aligner module to project human voice and face representation into a shared space. We develop a multi-modal dataset based on VoxCeleb2 for MM-TSD training and evaluation. Additionally, we conduct comparative analysis and ablation studies for each category of prompts to validate the efficacy of each component in the proposed framework. Furthermore, our framework demonstrates versatility in performing various signal processing tasks, including speaker diarization and overlap speech detection, using task-specific prompts. MM-TSD achieves robust and comparable performance as a unified system compared to specialized models. Moreover, MM-TSD shows capability to handle complex conversations for real-world dataset.
Prompt-driven Target Speech Diarization
Oct 23, 2023We introduce a novel task named `target speech diarization', which seeks to determine `when target event occurred' within an audio signal. We devise a neural architecture called Prompt-driven Target Speech Diarization (PTSD), that works with diverse prompts that specify the target speech events of interest. We train and evaluate PTSD using sim2spk, sim3spk and sim4spk datasets, which are derived from the Librispeech. We show that the proposed framework accurately localizes target speech events. Furthermore, our framework exhibits versatility through its impressive performance in three diarization-related tasks: target speaker voice activity detection, overlapped speech detection and gender diarization. In particular, PTSD achieves comparable performance to specialized models across these tasks on both real and simulated data. This work serves as a reference benchmark and provides valuable insights into prompt-driven target speech processing.
Leveraging In-the-Wild Data for Effective Self-Supervised Pretraining in Speaker Recognition
Sep 27, 2023Current speaker recognition systems primarily rely on supervised approaches, constrained by the scale of labeled datasets. To boost the system performance, researchers leverage large pretrained models such as WavLM to transfer learned high-level features to the downstream speaker recognition task. However, this approach introduces extra parameters as the pretrained model remains in the inference stage. Another group of researchers directly apply self-supervised methods such as DINO to speaker embedding learning, yet they have not explored its potential on large-scale in-the-wild datasets. In this paper, we present the effectiveness of DINO training on the large-scale WenetSpeech dataset and its transferability in enhancing the supervised system performance on the CNCeleb dataset. Additionally, we introduce a confidence-based data filtering algorithm to remove unreliable data from the pretraining dataset, leading to better performance with less training data. The associated pretrained models, confidence files, pretraining and finetuning scripts will be made available in the Wespeaker toolkit.