 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvanced Zero-Shot Text-to-Speech for Background Removal and Preservation with Controllable Masked Speech Prediction
Paper and Code
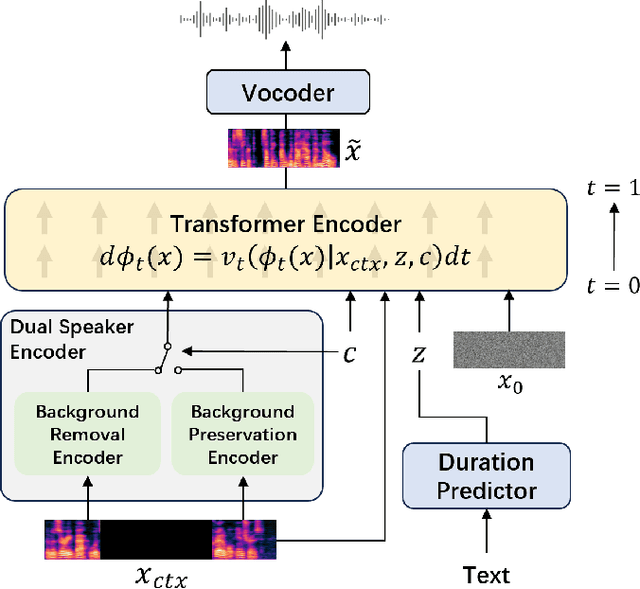
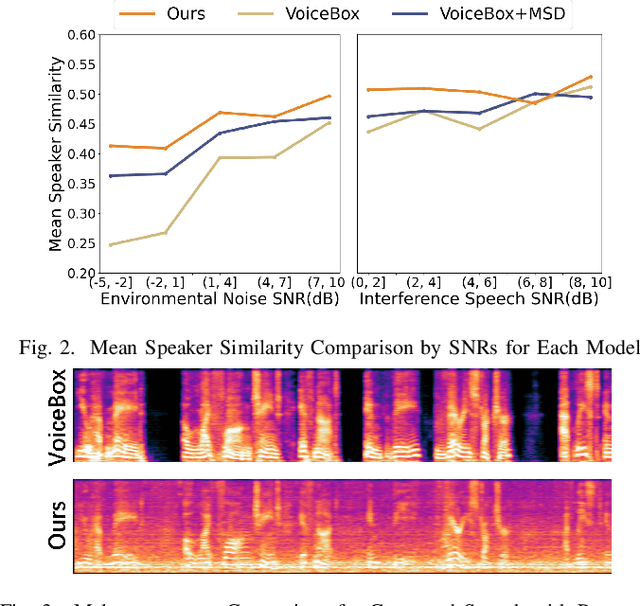


The acoustic background plays a crucial role in natural conversation. It provides context and helps listeners understand the environment, but a strong background makes it difficult for listeners to understand spoken words. The appropriate handling of these backgrounds is situation-dependent: Although it may be necessary to remove background to ensure speech clarity, preserving the background is sometimes crucial to maintaining the contextual integrity of the speech. Despite recent advancements in zero-shot Text-to-Speech technologies, current systems often struggle with speech prompts containing backgrounds. To address these challenges, we propose a Controllable Masked Speech Prediction strategy coupled with a dual-speaker encoder, utilizing a task-related control signal to guide the prediction of dual background removal and preservation targets. Experimental results demonstrate that our approach enables precise control over the removal or preservation of background across various acoustic conditions and exhibits strong generalization capabilities in unseen scenarios.