 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Token Eviction: Mixed-Dimension Budget Allocation for Efficient KV Cache Compression
Mar 21, 2026Key-value (KV) caching is widely used to accelerate transformer inference, but its memory cost grows linearly with input length, limiting long-context deployment. Existing token eviction methods reduce memory by discarding less important tokens, which can be viewed as a coarse form of dimensionality reduction that assigns each token either zero or full dimension. We propose MixedDimKV, a mixed-dimension KV cache compression method that allocates dimensions to tokens at a more granular level, and MixedDimKV-H, which further integrates head-level importance information. Experiments on long-context benchmarks show that MixedDimKV outperforms prior KV cache compression methods that do not rely on head-level importance profiling. When equipped with the same head-level importance information, MixedDimKV-H consistently outperforms HeadKV. Notably, our approach achieves comparable performance to full attention on LongBench with only 6.25% of the KV cache. Furthermore, in the Needle-in-a-Haystack test, our solution maintains 100% accuracy at a 50K context length while using as little as 0.26% of the cache.
Requesting Expert Reasoning: Augmenting LLM Agents with Learned Collaborative Intervention
Feb 26, 2026Large Language Model (LLM) based agents excel at general reasoning but often fail in specialized domains where success hinges on long-tail knowledge absent from their training data. While human experts can provide this missing knowledge, their guidance is often unstructured and unreliable, making its direct integration into an agent's plan problematic. To address this, we introduce AHCE (Active Human-Augmented Challenge Engagement), a framework for on-demand Human-AI collaboration. At its core, the Human Feedback Module (HFM) employs a learned policy to treat the human expert as an interactive reasoning tool. Extensive experiments in Minecraft demonstrate the framework's effectiveness, increasing task success rates by 32% on normal difficulty tasks and nearly 70% on highly difficult tasks, all with minimal human intervention. Our work demonstrates that successfully augmenting agents requires learning how to request expert reasoning, moving beyond simple requests for help.
PT-DETR: Small Target Detection Based on Partially-Aware Detail Focus
Oct 30, 2025To address the challenges in UAV object detection, such as complex backgrounds, severe occlusion, dense small objects, and varying lighting conditions,this paper proposes PT-DETR based on RT-DETR, a novel detection algorithm specifically designed for small objects in UAV imagery. In the backbone network, we introduce the Partially-Aware Detail Focus (PADF) Module to enhance feature extraction for small objects. Additionally,we design the Median-Frequency Feature Fusion (MFFF) module,which effectively improves the model's ability to capture small-object details and contextual information. Furthermore,we incorporate Focaler-SIoU to strengthen the model's bounding box matching capability and increase its sensitivity to small-object features, thereby further enhancing detection accuracy and robustness. Compared with RT-DETR, our PT-DETR achieves mAP improvements of 1.6% and 1.7% on the VisDrone2019 dataset with lower computational complexity and fewer parameters, demonstrating its robustness and feasibility for small-object detection tasks.
MergeMoE: Efficient Compression of MoE Models via Expert Output Merging
Oct 16, 2025The Mixture-of-Experts (MoE) technique has proven to be a promising solution to efficiently scale the model size, which has been widely applied in recent LLM advancements. However, the substantial memory overhead of MoE models has made their compression an important research direction. In this work, we provide a theoretical analysis of expert merging, a recently proposed technique for compressing MoE models. Rather than interpreting expert merging from the conventional perspective of parameter aggregation, we approach it from the perspective of merging experts' outputs. Our key insight is that the merging process can be interpreted as inserting additional matrices into the forward computation, which naturally leads to an optimization formulation. Building on this analysis, we introduce MergeMoE, a method that leverages mathematical optimization to construct the compression matrices. We evaluate MergeMoE on multiple MoE models and show that our algorithm consistently outperforms the baselines with the same compression ratios.
BR-ASR: Efficient and Scalable Bias Retrieval Framework for Contextual Biasing ASR in Speech LLM
May 25, 2025While speech large language models (SpeechLLMs) have advanced standard automatic speech recognition (ASR), contextual biasing for named entities and rare words remains challenging, especially at scale. To address this, we propose BR-ASR: a Bias Retrieval framework for large-scale contextual biasing (up to 200k entries) via two innovations: (1) speech-and-bias contrastive learning to retrieve semantically relevant candidates; (2) dynamic curriculum learning that mitigates homophone confusion which negatively impacts the final performance. The is a general framework that allows seamless integration of the retrieved candidates into diverse ASR systems without fine-tuning. Experiments on LibriSpeech test-clean/-other achieve state-of-the-art (SOTA) biased word error rates (B-WER) of 2.8%/7.1% with 2000 bias words, delivering 45% relative improvement over prior methods. BR-ASR also demonstrates high scalability: when expanding the bias list to 200k where traditional methods generally fail, it induces only 0.3 / 2.9% absolute WER / B-WER degradation with a 99.99% pruning rate and only 20ms latency per query on test-other.
KeepKV: Eliminating Output Perturbation in KV Cache Compression for Efficient LLMs Inference
Apr 14, 2025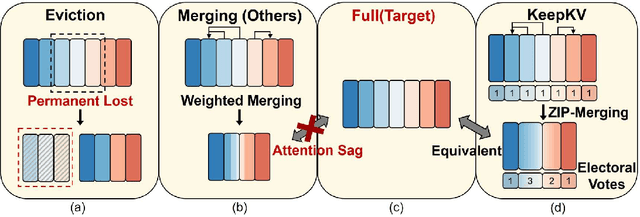
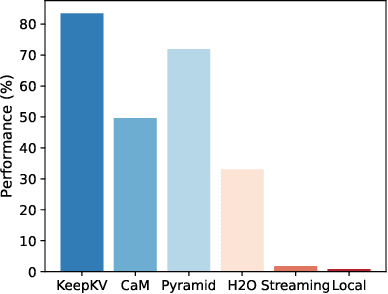
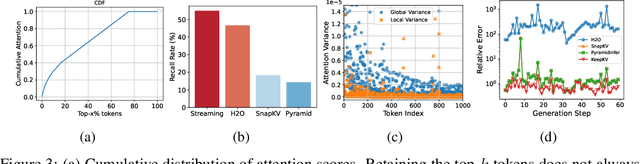
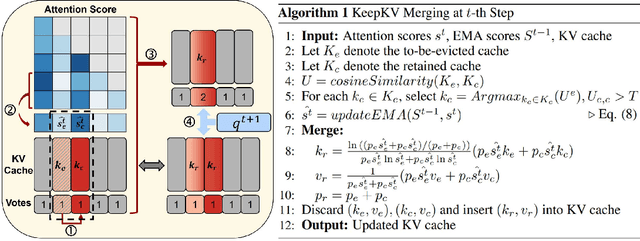
Efficient inference of large language models (LLMs) is hindered by an ever-growing key-value (KV) cache, making KV cache compression a critical research direction. Traditional methods selectively evict less important KV cache entries based on attention scores or position heuristics, which leads to information loss and hallucinations. Recently, merging-based strategies have been explored to retain more information by merging KV pairs that would be discarded; however, these existing approaches inevitably introduce inconsistencies in attention distributions before and after merging, causing output perturbation and degraded generation quality. To overcome this challenge, we propose KeepKV, a novel adaptive KV cache merging method designed to eliminate output perturbation while preserving performance under strict memory constraints. KeepKV introduces the Electoral Votes mechanism that records merging history and adaptively adjusts attention scores. Moreover, it further leverages a novel Zero Inference-Perturbation Merging methods, keeping attention consistency and compensating for attention loss resulting from cache merging. KeepKV successfully retains essential context information within a significantly compressed cache. Extensive experiments on various benchmarks and LLM architectures demonstrate that KeepKV substantially reduces memory usage, enhances inference throughput by more than 2x and keeps superior generation quality even with 10% KV cache budgets.
TdAttenMix: Top-Down Attention Guided Mixup
Jan 26, 2025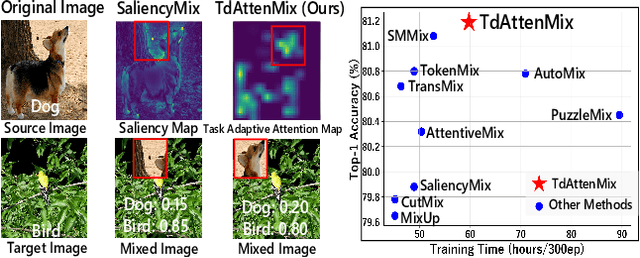
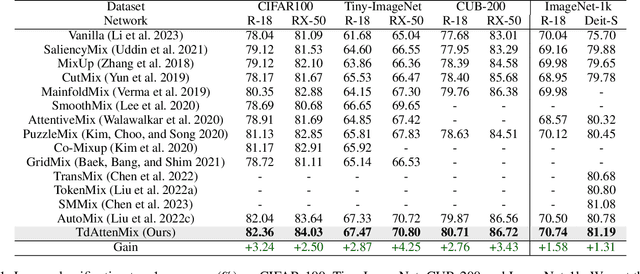
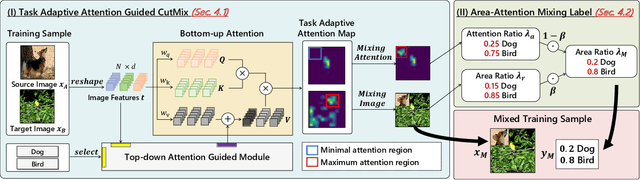
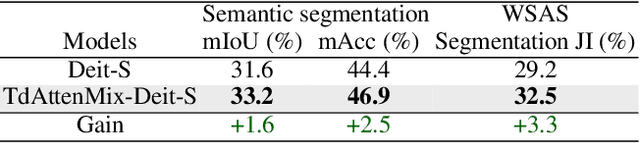
CutMix is a data augmentation strategy that cuts and pastes image patches to mixup training data. Existing methods pick either random or salient areas which are often inconsistent to labels, thus misguiding the training model. By our knowledge, we integrate human gaze to guide cutmix for the first time. Since human attention is driven by both high-level recognition and low-level clues, we propose a controllable Top-down Attention Guided Module to obtain a general artificial attention which balances top-down and bottom-up attention. The proposed TdATttenMix then picks the patches and adjust the label mixing ratio that focuses on regions relevant to the current label. Experimental results demonstrate that our TdAttenMix outperforms existing state-of-the-art mixup methods across eight different benchmarks. Additionally, we introduce a new metric based on the human gaze and use this metric to investigate the issue of image-label inconsistency. Project page: \url{https://github.com/morning12138/TdAttenMix}
Generalizable Audio Deepfake Detection via Latent Space Refinement and Augmentation
Jan 24, 2025Advances in speech synthesis technologies, like text-to-speech (TTS) and voice conversion (VC), have made detecting deepfake speech increasingly challenging. Spoofing countermeasures often struggle to generalize effectively, particularly when faced with unseen attacks. To address this, we propose a novel strategy that integrates Latent Space Refinement (LSR) and Latent Space Augmentation (LSA) to improve the generalization of deepfake detection systems. LSR introduces multiple learnable prototypes for the spoof class, refining the latent space to better capture the intricate variations within spoofed data. LSA further diversifies spoofed data representations by applying augmentation techniques directly in the latent space, enabling the model to learn a broader range of spoofing patterns. We evaluated our approach on four representative datasets, i.e. ASVspoof 2019 LA, ASVspoof 2021 LA and DF, and In-The-Wild. The results show that LSR and LSA perform well individually, and their integration achieves competitive results, matching or surpassing current state-of-the-art methods.
CCExpert: Advancing MLLM Capability in Remote Sensing Change Captioning with Difference-Aware Integration and a Foundational Dataset
Nov 18, 2024



Remote Sensing Image Change Captioning (RSICC) aims to generate natural language descriptions of surface changes between multi-temporal remote sensing images, detailing the categories, locations, and dynamics of changed objects (e.g., additions or disappearances). Many current methods attempt to leverage the long-sequence understanding and reasoning capabilities of multimodal large language models (MLLMs) for this task. However, without comprehensive data support, these approaches often alter the essential feature transmission pathways of MLLMs, disrupting the intrinsic knowledge within the models and limiting their potential in RSICC. In this paper, we propose a novel model, CCExpert, based on a new, advanced multimodal large model framework. Firstly, we design a difference-aware integration module to capture multi-scale differences between bi-temporal images and incorporate them into the original image context, thereby enhancing the signal-to-noise ratio of differential features. Secondly, we constructed a high-quality, diversified dataset called CC-Foundation, containing 200,000 image pairs and 1.2 million captions, to provide substantial data support for continue pretraining in this domain. Lastly, we employed a three-stage progressive training process to ensure the deep integration of the difference-aware integration module with the pretrained MLLM. CCExpert achieved a notable performance of $S^*_m=81.80$ on the LEVIR-CC benchmark, significantly surpassing previous state-of-the-art methods. The code and part of the dataset will soon be open-sourced at https://github.com/Meize0729/CCExpert.
SRMAE: Masked Image Modeling for Scale-Invariant Deep Representations
Aug 17, 2023



Due to the prevalence of scale variance in nature images, we propose to use image scale as a self-supervised signal for Masked Image Modeling (MIM). Our method involves selecting random patches from the input image and downsampling them to a low-resolution format. Our framework utilizes the latest advances in super-resolution (SR) to design the prediction head, which reconstructs the input from low-resolution clues and other patches. After 400 epochs of pre-training, our Super Resolution Masked Autoencoders (SRMAE) get an accuracy of 82.1% on the ImageNet-1K task. Image scale signal also allows our SRMAE to capture scale invariance representation. For the very low resolution (VLR) recognition task, our model achieves the best performance, surpassing DeriveNet by 1.3%. Our method also achieves an accuracy of 74.84% on the task of recognizing low-resolution facial expressions, surpassing the current state-of-the-art FMD by 9.48%.