 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncreRTL: Traceability-Guided Incremental RTL Generation under Requirement Evolution
Mar 26, 2026Large language models (LLMs) have shown promise in generating RTL code from natural-language descriptions, but existing methods remain static and struggle to adapt to evolving design requirements, potentially causing structural drift and costly full regeneration. We propose IncreRTL, a LLM-driven framework for incremental RTL generation under requirement evolution. By constructing requirement-code traceability links to locate and regenerate affected code segments, IncreRTL achieves accurate and consistent updates. Evaluated on our newly constructed EvoRTL-Bench, IncreRTL demonstrates notable improvements in regeneration consistency and efficiency, advancing LLM-based RTL generation toward practical engineering deployment.
LookBench: A Live and Holistic Open Benchmark for Fashion Image Retrieval
Jan 21, 2026In this paper, we present LookBench (We use the term "look" to reflect retrieval that mirrors how people shop -- finding the exact item, a close substitute, or a visually consistent alternative.), a live, holistic and challenging benchmark for fashion image retrieval in real e-commerce settings. LookBench includes both recent product images sourced from live websites and AI-generated fashion images, reflecting contemporary trends and use cases. Each test sample is time-stamped and we intend to update the benchmark periodically, enabling contamination-aware evaluation aligned with declared training cutoffs. Grounded in our fine-grained attribute taxonomy, LookBench covers single-item and outfit-level retrieval across. Our experiments reveal that LookBench poses a significant challenge on strong baselines, with many models achieving below $60\%$ Recall@1. Our proprietary model achieves the best performance on LookBench, and we release an open-source counterpart that ranks second, with both models attaining state-of-the-art results on legacy Fashion200K evaluations. LookBench is designed to be updated semi-annually with new test samples and progressively harder task variants, providing a durable measure of progress. We publicly release our leaderboard, dataset, evaluation code, and trained models.
MindWatcher: Toward Smarter Multimodal Tool-Integrated Reasoning
Dec 29, 2025Traditional workflow-based agents exhibit limited intelligence when addressing real-world problems requiring tool invocation. Tool-integrated reasoning (TIR) agents capable of autonomous reasoning and tool invocation are rapidly emerging as a powerful approach for complex decision-making tasks involving multi-step interactions with external environments. In this work, we introduce MindWatcher, a TIR agent integrating interleaved thinking and multimodal chain-of-thought (CoT) reasoning. MindWatcher can autonomously decide whether and how to invoke diverse tools and coordinate their use, without relying on human prompts or workflows. The interleaved thinking paradigm enables the model to switch between thinking and tool calling at any intermediate stage, while its multimodal CoT capability allows manipulation of images during reasoning to yield more precise search results. We implement automated data auditing and evaluation pipelines, complemented by manually curated high-quality datasets for training, and we construct a benchmark, called MindWatcher-Evaluate Bench (MWE-Bench), to evaluate its performance. MindWatcher is equipped with a comprehensive suite of auxiliary reasoning tools, enabling it to address broad-domain multimodal problems. A large-scale, high-quality local image retrieval database, covering eight categories including cars, animals, and plants, endows model with robust object recognition despite its small size. Finally, we design a more efficient training infrastructure for MindWatcher, enhancing training speed and hardware utilization. Experiments not only demonstrate that MindWatcher matches or exceeds the performance of larger or more recent models through superior tool invocation, but also uncover critical insights for agent training, such as the genetic inheritance phenomenon in agentic RL.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
ChiseLLM: Unleashing the Power of Reasoning LLMs for Chisel Agile Hardware Development
Apr 27, 2025The growing demand for Domain-Specific Architecture (DSA) has driven the development of Agile Hardware Development Methodology (AHDM). Hardware Construction Language (HCL) like Chisel offers high-level abstraction features, making it an ideal language for HCL-Based AHDM. While Large Language Models (LLMs) excel in code generation tasks, they still face challenges with Chisel generation, particularly regarding syntax correctness and design variability. Recent reasoning models have significantly enhanced code generation capabilities through test-time scaling techniques. However, we found that reasoning models without domain adaptation cannot bring substantial benefits to Chisel code generation tasks. This paper presents ChiseLLM, a solution comprising data processing and transformation, prompt-guided reasoning trace synthesis, and domain-adapted model training. We constructed high-quality datasets from public RTL code resources and guided the model to adopt structured thinking patterns through prompt enhancement methods. Experiments demonstrate that our ChiseLLM-7B and ChiseLLM-32B models improved syntax correctness by 18.85% and 26.32% respectively over base models, while increasing variability design ability by 47.58% compared to baseline reasoning models. Our datasets and models are publicly available, providing high-performance, cost-effective models for HCL-Based AHDM, and offering an effective baseline for future research. Github repository: https://github.com/observerw/ChiseLLM
Unseen Horizons: Unveiling the Real Capability of LLM Code Generation Beyond the Familiar
Dec 11, 2024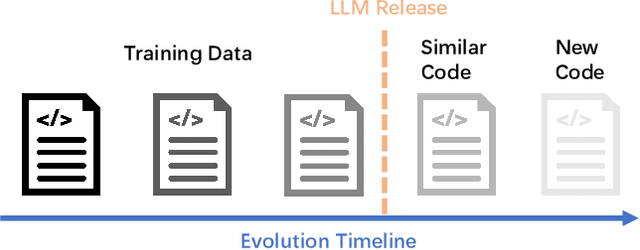

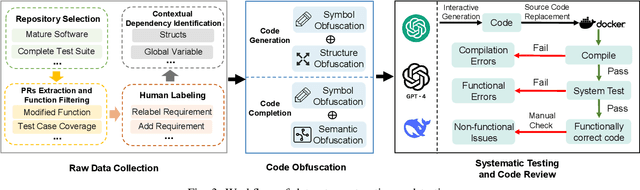
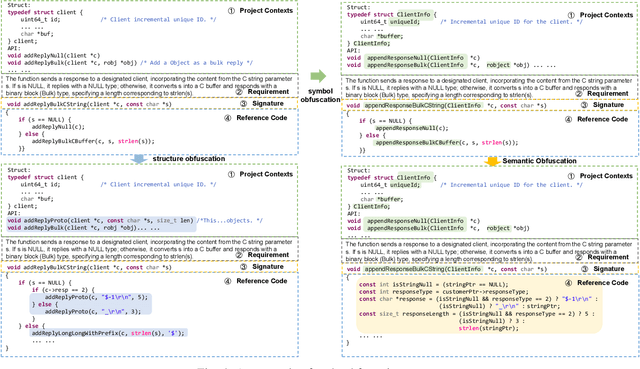
Recently, large language models (LLMs) have shown strong potential in code generation tasks. However, there are still gaps before they can be fully applied in actual software development processes. Accurately assessing the code generation capabilities of large language models has become an important basis for evaluating and improving the models. Some existing works have constructed datasets to evaluate the capabilities of these models. However, the current evaluation process may encounter the illusion of "Specialist in Familiarity", primarily due to three gaps: the exposure of target code, case timeliness, and dependency availability. The fundamental reason for these gaps is that the code in current datasets may have been extensively exposed and exercised during the training phase, and due to the continuous training and development of LLM, their timeliness has been severely compromised. The key to solve the problem is to, as much as possible, evaluate the LLMs using code that they have not encountered before. Thus, the fundamental idea in this paper is to draw on the concept of code obfuscation, changing code at different levels while ensuring the functionality and output. To this end, we build a code-obfuscation based benchmark OBFUSEVAL. We first collect 1,354 raw cases from five real-world projects, including function description and code. Then we use three-level strategy (symbol, structure and semantic) to obfuscate descriptions, code and context dependencies. We evaluate four LLMs on OBFU- SEVAL and compared the effectiveness of different obfuscation strategy. We use official test suites of these projects to evaluate the generated code. The results show that after obfuscation, the average decrease ratio of test pass rate can up to 62.5%.
SPT: Spectral Transformer for Red Giant Stars Age and Mass Estimation
Jan 10, 2024The age and mass of red giants are essential for understanding the structure and evolution of the Milky Way. Traditional isochrone methods for these estimations are inherently limited due to overlapping isochrones in the Hertzsprung-Russell diagram, while asteroseismology, though more precise, requires high-precision, long-term observations. In response to these challenges, we developed a novel framework, Spectral Transformer (SPT), to predict the age and mass of red giants aligned with asteroseismology from their spectra. A key component of SPT, the Multi-head Hadamard Self-Attention mechanism, designed specifically for spectra, can capture complex relationships across different wavelength. Further, we introduced a Mahalanobis distance-based loss function to address scale imbalance and interaction mode loss, and incorporated Monte Carlo dropout for quantitative analysis of prediction uncertainty.Trained and tested on 3,880 red giant spectra from LAMOST, the SPT achieved remarkable age and mass estimations with average percentage errors of 17.64% and 6.61%, respectively, and provided uncertainties for each corresponding prediction. The results significantly outperform those of traditional machine learning algorithms and demonstrate a high level of consistency with asteroseismology methods and isochrone fitting techniques. In the future, our work will leverage datasets from the Chinese Space Station Telescope and the Large Synoptic Survey Telescope to enhance the precision of the model and broaden its applicability in the field of astronomy and astrophysics.
Image Restoration with Point Spread Function Regularization and Active Learning
Oct 31, 2023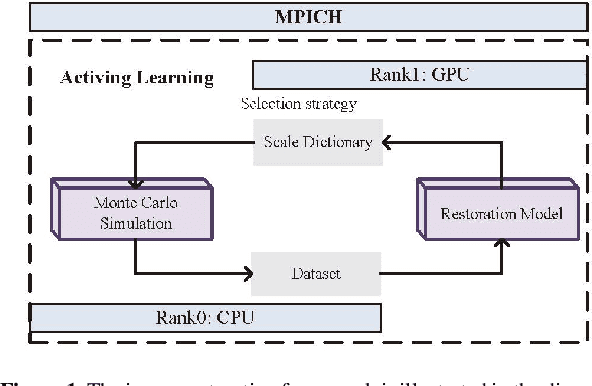


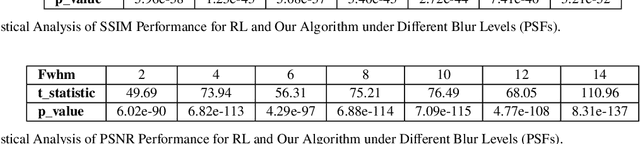
Large-scale astronomical surveys can capture numerous images of celestial objects, including galaxies and nebulae. Analysing and processing these images can reveal intricate internal structures of these objects, allowing researchers to conduct comprehensive studies on their morphology, evolution, and physical properties. However, varying noise levels and point spread functions can hamper the accuracy and efficiency of information extraction from these images. To mitigate these effects, we propose a novel image restoration algorithm that connects a deep learning-based restoration algorithm with a high-fidelity telescope simulator. During the training stage, the simulator generates images with different levels of blur and noise to train the neural network based on the quality of restored images. After training, the neural network can directly restore images obtained by the telescope, as represented by the simulator. We have tested the algorithm using real and simulated observation data and have found that it effectively enhances fine structures in blurry images and increases the quality of observation images. This algorithm can be applied to large-scale sky survey data, such as data obtained by LSST, Euclid, and CSST, to further improve the accuracy and efficiency of information extraction, promoting advances in the field of astronomical research.
Bridging Code Semantic and LLMs: Semantic Chain-of-Thought Prompting for Code Generation
Oct 22, 2023



Large language models (LLMs) have showcased remarkable prowess in code generation. However, automated code generation is still challenging since it requires a high-level semantic mapping between natural language requirements and codes. Most existing LLMs-based approaches for code generation rely on decoder-only causal language models often treate codes merely as plain text tokens, i.e., feeding the requirements as a prompt input, and outputing code as flat sequence of tokens, potentially missing the rich semantic features inherent in source code. To bridge this gap, this paper proposes the "Semantic Chain-of-Thought" approach to intruduce semantic information of code, named SeCoT. Our motivation is that the semantic information of the source code (\eg data flow and control flow) describes more precise program execution behavior, intention and function. By guiding LLM consider and integrate semantic information, we can achieve a more granular understanding and representation of code, enhancing code generation accuracy. Meanwhile, while traditional techniques leveraging such semantic information require complex static or dynamic code analysis to obtain features such as data flow and control flow, SeCoT demonstrates that this process can be fully automated via the intrinsic capabilities of LLMs (i.e., in-context learning), while being generalizable and applicable to challenging domains. While SeCoT can be applied with different LLMs, this paper focuses on the powerful GPT-style models: ChatGPT(close-source model) and WizardCoder(open-source model). The experimental study on three popular DL benchmarks (i.e., HumanEval, HumanEval-ET and MBPP) shows that SeCoT can achieves state-of-the-art performance, greatly improving the potential for large models and code generation.
At Which Training Stage Does Code Data Help LLMs Reasoning?
Sep 30, 2023



Large Language Models (LLMs) have exhibited remarkable reasoning capabilities and become the foundation of language technologies. Inspired by the great success of code data in training LLMs, we naturally wonder at which training stage introducing code data can really help LLMs reasoning. To this end, this paper systematically explores the impact of code data on LLMs at different stages. Concretely, we introduce the code data at the pre-training stage, instruction-tuning stage, and both of them, respectively. Then, the reasoning capability of LLMs is comprehensively and fairly evaluated via six reasoning tasks in five domains. We critically analyze the experimental results and provide conclusions with insights. First, pre-training LLMs with the mixture of code and text can significantly enhance LLMs' general reasoning capability almost without negative transfer on other tasks. Besides, at the instruction-tuning stage, code data endows LLMs the task-specific reasoning capability. Moreover, the dynamic mixing strategy of code and text data assists LLMs to learn reasoning capability step-by-step during training. These insights deepen the understanding of LLMs regarding reasoning ability for their application, such as scientific question answering, legal support, etc. The source code and model parameters are released at the link:~\url{https://github.com/yingweima2022/CodeLLM}.