 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 The Second Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 12, 2026This paper presents an overview of the NTIRE 2026 Second Challenge on Day and Night Raindrop Removal for Dual-Focused Images. Building upon the success of the first edition, this challenge attracted a wide range of impressive solutions, all developed and evaluated on our real-world Raindrop Clarity dataset~\cite{jin2024raindrop}. For this edition, we adjust the dataset with 14,139 images for training, 407 images for validation, and 593 images for testing. The primary goal of this challenge is to establish a strong and practical benchmark for the removal of raindrops under various illumination and focus conditions. In total, 168 teams have registered for the competition, and 17 teams submitted valid final solutions and fact sheets for the testing phase. The submitted methods achieved strong performance on the Raindrop Clarity dataset, demonstrating the growing progress in this challenging task.
PhysFormer: A Physics-Embedded Generative Model for Physically Self-Consistent Spectral Synthesis
Mar 02, 2026In scientific and engineering domains, modeling high-dimensional complex systems governed by partial differential equations (PDEs) remains challenging in terms of physical consistency and numerical stability. However, existing approaches, such as physics-informed neural networks (PINNs), typically rely on known physical fields or coefficients and enforce physical constraints via external loss functions, which can lead to training instability and make it difficult to handle high-dimensional or unobservable scenarios. To this end, we propose PhysFormer, a generative modeling framework that is self-consistent at both the data and physical levels. PhysFormer leverages a low-dimensional, physically interpretable latent space to learn key physical quantities directly from data without requiring known high-dimensional physical field parameters, and embeds the physical process of radiative flux generation within the network to ensure the physical consistency of the generated spectra. In high-dimensional, degenerate inversion tasks, PhysFormer constrains generation within physical limits and enhances spectral fidelity and inversion stability under varying signal-to-noise ratios (SNRs). More broadly, this approach shifts the physical processes from external loss functions into the generative mechanism itself, providing a physically consistent generative modeling paradigm for complex systems involving unknown or unobservable physical quantities.
MedGround: Bridging the Evidence Gap in Medical Vision-Language Models with Verified Grounding Data
Jan 11, 2026Vision-Language Models (VLMs) can generate convincing clinical narratives, yet frequently struggle to visually ground their statements. We posit this limitation arises from the scarcity of high-quality, large-scale clinical referring-localization pairs. To address this, we introduce MedGround, an automated pipeline that transforms segmentation resources into high-quality medical referring grounding data. Leveraging expert masks as spatial anchors, MedGround precisely derives localization targets, extracts shape and spatial cues, and guides VLMs to synthesize natural, clinically grounded queries that reflect morphology and location. To ensure data rigor, a multi-stage verification system integrates strict formatting checks, geometry- and medical-prior rules, and image-based visual judging to filter out ambiguous or visually unsupported samples. Finally, we present MedGround-35K, a novel multimodal medical dataset. Extensive experiments demonstrate that VLMs trained with MedGround-35K consistently achieve improved referring grounding performance, enhance multi-object semantic disambiguation, and exhibit strong generalization to unseen grounding settings. This work highlights MedGround as a scalable, data-driven approach to anchor medical language to verifiable visual evidence. Dataset and code will be released publicly upon acceptance.
The FM Agent
Oct 30, 2025Large language models (LLMs) are catalyzing the development of autonomous AI research agents for scientific and engineering discovery. We present FM Agent, a novel and general-purpose multi-agent framework that leverages a synergistic combination of LLM-based reasoning and large-scale evolutionary search to address complex real-world challenges. The core of FM Agent integrates several key innovations: 1) a cold-start initialization phase incorporating expert guidance, 2) a novel evolutionary sampling strategy for iterative optimization, 3) domain-specific evaluators that combine correctness, effectiveness, and LLM-supervised feedback, and 4) a distributed, asynchronous execution infrastructure built on Ray. Demonstrating broad applicability, our system has been evaluated across diverse domains, including operations research, machine learning, GPU kernel optimization, and classical mathematical problems. FM Agent reaches state-of-the-art results autonomously, without human interpretation or tuning -- 1976.3 on ALE-Bench (+5.2\%), 43.56\% on MLE-Bench (+4.0pp), up to 20x speedups on KernelBench, and establishes new state-of-the-art(SOTA) results on several classical mathematical problems. Beyond academic benchmarks, FM Agent shows considerable promise for both large-scale enterprise R\&D workflows and fundamental scientific research, where it can accelerate innovation, automate complex discovery processes, and deliver substantial engineering and scientific advances with broader societal impact.
Cross-domain Hyperspectral Image Classification based on Bi-directional Domain Adaptation
Jul 03, 2025Utilizing hyperspectral remote sensing technology enables the extraction of fine-grained land cover classes. Typically, satellite or airborne images used for training and testing are acquired from different regions or times, where the same class has significant spectral shifts in different scenes. In this paper, we propose a Bi-directional Domain Adaptation (BiDA) framework for cross-domain hyperspectral image (HSI) classification, which focuses on extracting both domain-invariant features and domain-specific information in the independent adaptive space, thereby enhancing the adaptability and separability to the target scene. In the proposed BiDA, a triple-branch transformer architecture (the source branch, target branch, and coupled branch) with semantic tokenizer is designed as the backbone. Specifically, the source branch and target branch independently learn the adaptive space of source and target domains, a Coupled Multi-head Cross-attention (CMCA) mechanism is developed in coupled branch for feature interaction and inter-domain correlation mining. Furthermore, a bi-directional distillation loss is designed to guide adaptive space learning using inter-domain correlation. Finally, we propose an Adaptive Reinforcement Strategy (ARS) to encourage the model to focus on specific generalized feature extraction within both source and target scenes in noise condition. Experimental results on cross-temporal/scene airborne and satellite datasets demonstrate that the proposed BiDA performs significantly better than some state-of-the-art domain adaptation approaches. In the cross-temporal tree species classification task, the proposed BiDA is more than 3\%$\sim$5\% higher than the most advanced method. The codes will be available from the website: https://github.com/YuxiangZhang-BIT/IEEE_TCSVT_BiDA.
NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 19, 2025



This paper reviews the NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images. This challenge received a wide range of impressive solutions, which are developed and evaluated using our collected real-world Raindrop Clarity dataset. Unlike existing deraining datasets, our Raindrop Clarity dataset is more diverse and challenging in degradation types and contents, which includes day raindrop-focused, day background-focused, night raindrop-focused, and night background-focused degradations. This dataset is divided into three subsets for competition: 14,139 images for training, 240 images for validation, and 731 images for testing. The primary objective of this challenge is to establish a new and powerful benchmark for the task of removing raindrops under varying lighting and focus conditions. There are a total of 361 participants in the competition, and 32 teams submitting valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the Raindrop Clarity dataset. The project can be found at https://lixinustc.github.io/CVPR-NTIRE2025-RainDrop-Competition.github.io/.
SPT: Spectral Transformer for Red Giant Stars Age and Mass Estimation
Jan 10, 2024The age and mass of red giants are essential for understanding the structure and evolution of the Milky Way. Traditional isochrone methods for these estimations are inherently limited due to overlapping isochrones in the Hertzsprung-Russell diagram, while asteroseismology, though more precise, requires high-precision, long-term observations. In response to these challenges, we developed a novel framework, Spectral Transformer (SPT), to predict the age and mass of red giants aligned with asteroseismology from their spectra. A key component of SPT, the Multi-head Hadamard Self-Attention mechanism, designed specifically for spectra, can capture complex relationships across different wavelength. Further, we introduced a Mahalanobis distance-based loss function to address scale imbalance and interaction mode loss, and incorporated Monte Carlo dropout for quantitative analysis of prediction uncertainty.Trained and tested on 3,880 red giant spectra from LAMOST, the SPT achieved remarkable age and mass estimations with average percentage errors of 17.64% and 6.61%, respectively, and provided uncertainties for each corresponding prediction. The results significantly outperform those of traditional machine learning algorithms and demonstrate a high level of consistency with asteroseismology methods and isochrone fitting techniques. In the future, our work will leverage datasets from the Chinese Space Station Telescope and the Large Synoptic Survey Telescope to enhance the precision of the model and broaden its applicability in the field of astronomy and astrophysics.
Language-aware Domain Generalization Network for Cross-Scene Hyperspectral Image Classification
Sep 06, 2022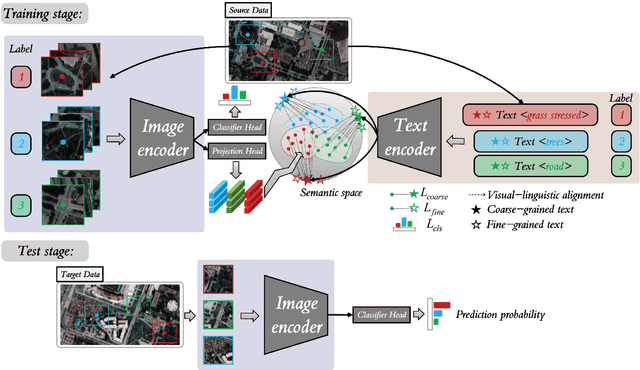
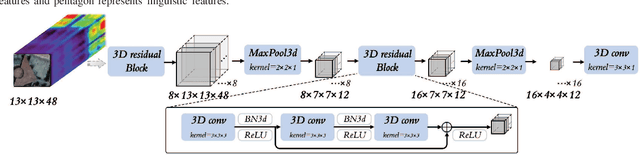
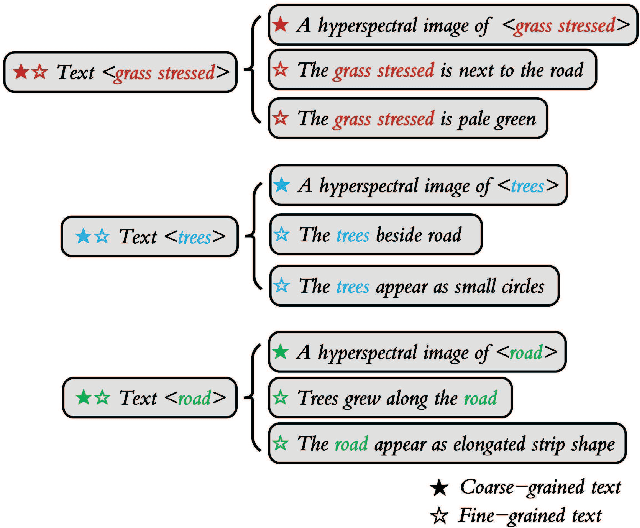
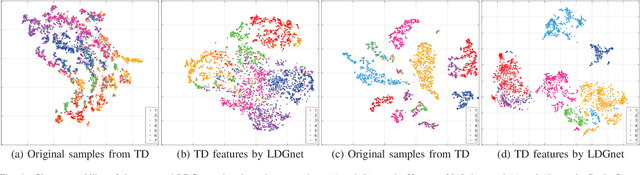
Text information including extensive prior knowledge about land cover classes has been ignored in hyperspectral image classification (HSI) tasks. It is necessary to explore the effectiveness of linguistic mode in assisting HSI classification. In addition, the large-scale pre-training image-text foundation models have demonstrated great performance in a variety of downstream applications, including zero-shot transfer. However, most domain generalization methods have never addressed mining linguistic modal knowledge to improve the generalization performance of model. To compensate for the inadequacies listed above, a Language-aware Domain Generalization Network (LDGnet) is proposed to learn cross-domain invariant representation from cross-domain shared prior knowledge. The proposed method only trains on the source domain (SD) and then transfers the model to the target domain (TD). The dual-stream architecture including image encoder and text encoder is used to extract visual and linguistic features, in which coarse-grained and fine-grained text representations are designed to extract two levels of linguistic features. Furthermore, linguistic features are used as cross-domain shared semantic space, and visual-linguistic alignment is completed by supervised contrastive learning in semantic space. Extensive experiments on three datasets demonstrate the superiority of the proposed method when compared with state-of-the-art techniques.
Hyperspectral and Multispectral Classification for Coastal Wetland Using Depthwise Feature Interaction Network
Jul 12, 2021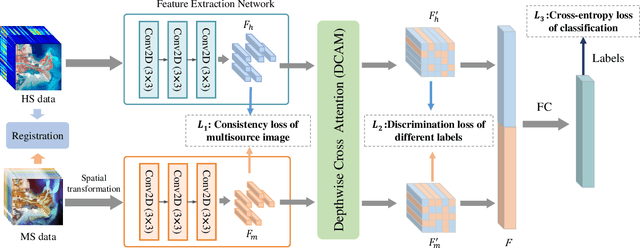
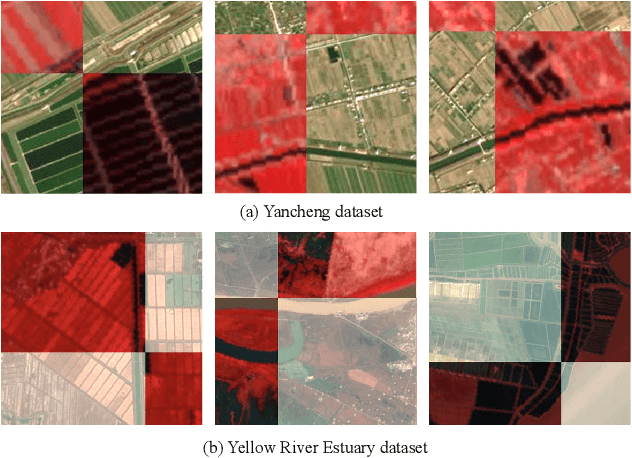
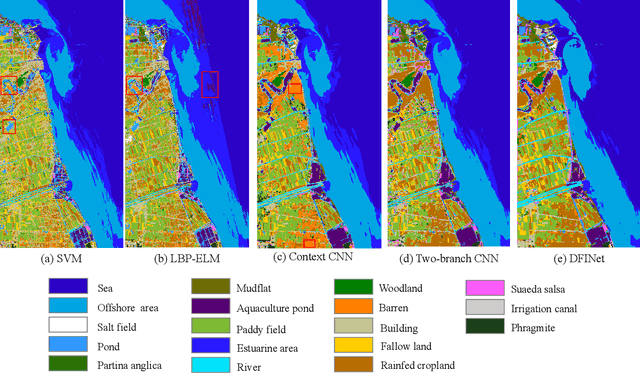
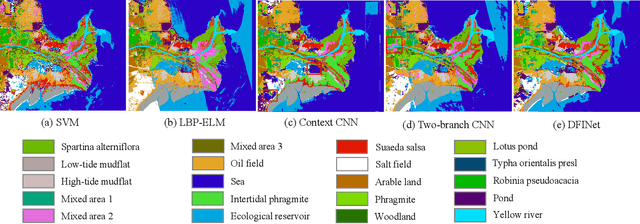
The monitoring of coastal wetlands is of great importance to the protection of marine and terrestrial ecosystems. However, due to the complex environment, severe vegetation mixture, and difficulty of access, it is impossible to accurately classify coastal wetlands and identify their species with traditional classifiers. Despite the integration of multisource remote sensing data for performance enhancement, there are still challenges with acquiring and exploiting the complementary merits from multisource data. In this paper, the Deepwise Feature Interaction Network (DFINet) is proposed for wetland classification. A depthwise cross attention module is designed to extract self-correlation and cross-correlation from multisource feature pairs. In this way, meaningful complementary information is emphasized for classification. DFINet is optimized by coordinating consistency loss, discrimination loss, and classification loss. Accordingly, DFINet reaches the standard solution-space under the regularity of loss functions, while the spatial consistency and feature discrimination are preserved. Comprehensive experimental results on two hyperspectral and multispectral wetland datasets demonstrate that the proposed DFINet outperforms other competitive methods in terms of overall accuracy.