 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-aware Domain Generalization Network for Cross-Scene Hyperspectral Image Classification
Paper and Code
Sep 06, 2022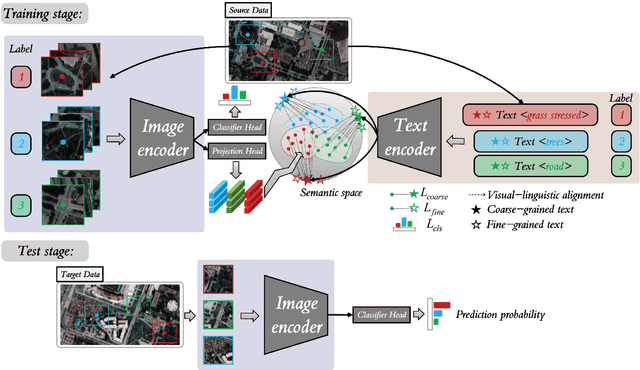
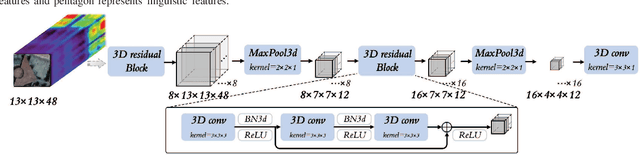
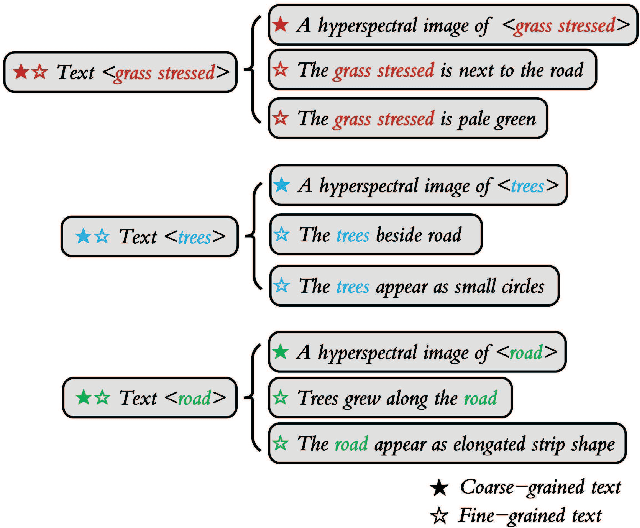
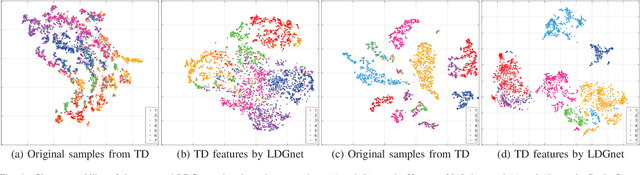
Text information including extensive prior knowledge about land cover classes has been ignored in hyperspectral image classification (HSI) tasks. It is necessary to explore the effectiveness of linguistic mode in assisting HSI classification. In addition, the large-scale pre-training image-text foundation models have demonstrated great performance in a variety of downstream applications, including zero-shot transfer. However, most domain generalization methods have never addressed mining linguistic modal knowledge to improve the generalization performance of model. To compensate for the inadequacies listed above, a Language-aware Domain Generalization Network (LDGnet) is proposed to learn cross-domain invariant representation from cross-domain shared prior knowledge. The proposed method only trains on the source domain (SD) and then transfers the model to the target domain (TD). The dual-stream architecture including image encoder and text encoder is used to extract visual and linguistic features, in which coarse-grained and fine-grained text representations are designed to extract two levels of linguistic features. Furthermore, linguistic features are used as cross-domain shared semantic space, and visual-linguistic alignment is completed by supervised contrastive learning in semantic space. Extensive experiments on three datasets demonstrate the superiority of the proposed method when compared with state-of-the-art techniques.