 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnseen Horizons: Unveiling the Real Capability of LLM Code Generation Beyond the Familiar
Dec 11, 2024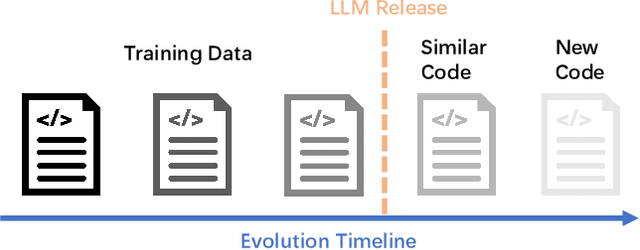

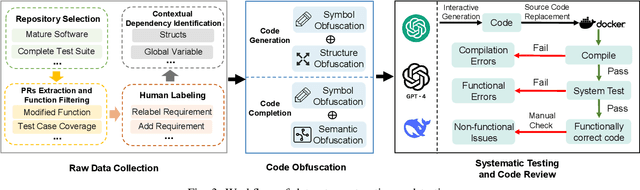
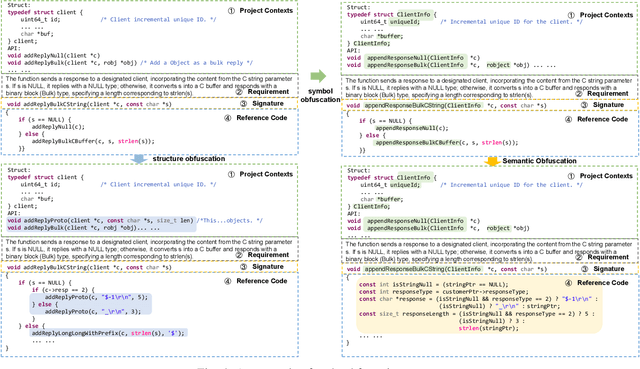
Recently, large language models (LLMs) have shown strong potential in code generation tasks. However, there are still gaps before they can be fully applied in actual software development processes. Accurately assessing the code generation capabilities of large language models has become an important basis for evaluating and improving the models. Some existing works have constructed datasets to evaluate the capabilities of these models. However, the current evaluation process may encounter the illusion of "Specialist in Familiarity", primarily due to three gaps: the exposure of target code, case timeliness, and dependency availability. The fundamental reason for these gaps is that the code in current datasets may have been extensively exposed and exercised during the training phase, and due to the continuous training and development of LLM, their timeliness has been severely compromised. The key to solve the problem is to, as much as possible, evaluate the LLMs using code that they have not encountered before. Thus, the fundamental idea in this paper is to draw on the concept of code obfuscation, changing code at different levels while ensuring the functionality and output. To this end, we build a code-obfuscation based benchmark OBFUSEVAL. We first collect 1,354 raw cases from five real-world projects, including function description and code. Then we use three-level strategy (symbol, structure and semantic) to obfuscate descriptions, code and context dependencies. We evaluate four LLMs on OBFU- SEVAL and compared the effectiveness of different obfuscation strategy. We use official test suites of these projects to evaluate the generated code. The results show that after obfuscation, the average decrease ratio of test pass rate can up to 62.5%.
Bridging Pre-trained Models and Downstream Tasks for Source Code Understanding
Dec 04, 2021



With the great success of pre-trained models, the pretrain-then-finetune paradigm has been widely adopted on downstream tasks for source code understanding. However, compared to costly training a large-scale model from scratch, how to effectively adapt pre-trained models to a new task has not been fully explored. In this paper, we propose an approach to bridge pre-trained models and code-related tasks. We exploit semantic-preserving transformation to enrich downstream data diversity, and help pre-trained models learn semantic features invariant to these semantically equivalent transformations. Further, we introduce curriculum learning to organize the transformed data in an easy-to-hard manner to fine-tune existing pre-trained models. We apply our approach to a range of pre-trained models, and they significantly outperform the state-of-the-art models on tasks for source code understanding, such as algorithm classification, code clone detection, and code search. Our experiments even show that without heavy pre-training on code data, natural language pre-trained model RoBERTa fine-tuned with our lightweight approach could outperform or rival existing code pre-trained models fine-tuned on the above tasks, such as CodeBERT and GraphCodeBERT. This finding suggests that there is still much room for improvement in code pre-trained models.