 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnseen Horizons: Unveiling the Real Capability of LLM Code Generation Beyond the Familiar
Dec 11, 2024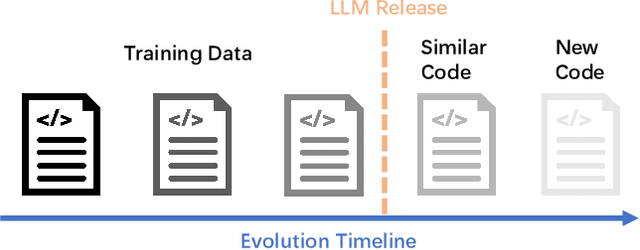

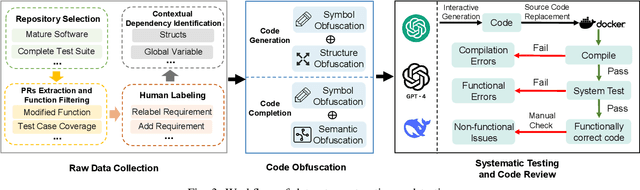
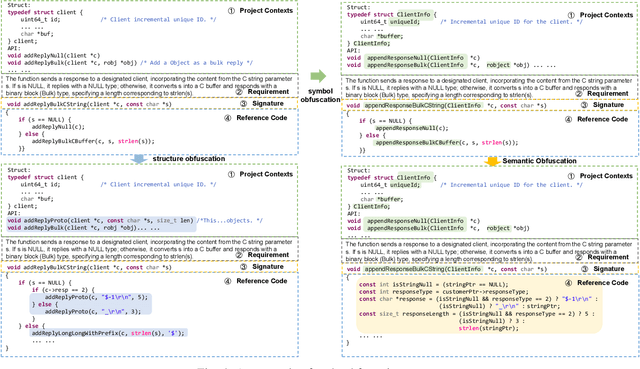
Recently, large language models (LLMs) have shown strong potential in code generation tasks. However, there are still gaps before they can be fully applied in actual software development processes. Accurately assessing the code generation capabilities of large language models has become an important basis for evaluating and improving the models. Some existing works have constructed datasets to evaluate the capabilities of these models. However, the current evaluation process may encounter the illusion of "Specialist in Familiarity", primarily due to three gaps: the exposure of target code, case timeliness, and dependency availability. The fundamental reason for these gaps is that the code in current datasets may have been extensively exposed and exercised during the training phase, and due to the continuous training and development of LLM, their timeliness has been severely compromised. The key to solve the problem is to, as much as possible, evaluate the LLMs using code that they have not encountered before. Thus, the fundamental idea in this paper is to draw on the concept of code obfuscation, changing code at different levels while ensuring the functionality and output. To this end, we build a code-obfuscation based benchmark OBFUSEVAL. We first collect 1,354 raw cases from five real-world projects, including function description and code. Then we use three-level strategy (symbol, structure and semantic) to obfuscate descriptions, code and context dependencies. We evaluate four LLMs on OBFU- SEVAL and compared the effectiveness of different obfuscation strategy. We use official test suites of these projects to evaluate the generated code. The results show that after obfuscation, the average decrease ratio of test pass rate can up to 62.5%.
Bridging Code Semantic and LLMs: Semantic Chain-of-Thought Prompting for Code Generation
Oct 22, 2023



Large language models (LLMs) have showcased remarkable prowess in code generation. However, automated code generation is still challenging since it requires a high-level semantic mapping between natural language requirements and codes. Most existing LLMs-based approaches for code generation rely on decoder-only causal language models often treate codes merely as plain text tokens, i.e., feeding the requirements as a prompt input, and outputing code as flat sequence of tokens, potentially missing the rich semantic features inherent in source code. To bridge this gap, this paper proposes the "Semantic Chain-of-Thought" approach to intruduce semantic information of code, named SeCoT. Our motivation is that the semantic information of the source code (\eg data flow and control flow) describes more precise program execution behavior, intention and function. By guiding LLM consider and integrate semantic information, we can achieve a more granular understanding and representation of code, enhancing code generation accuracy. Meanwhile, while traditional techniques leveraging such semantic information require complex static or dynamic code analysis to obtain features such as data flow and control flow, SeCoT demonstrates that this process can be fully automated via the intrinsic capabilities of LLMs (i.e., in-context learning), while being generalizable and applicable to challenging domains. While SeCoT can be applied with different LLMs, this paper focuses on the powerful GPT-style models: ChatGPT(close-source model) and WizardCoder(open-source model). The experimental study on three popular DL benchmarks (i.e., HumanEval, HumanEval-ET and MBPP) shows that SeCoT can achieves state-of-the-art performance, greatly improving the potential for large models and code generation.
Learning to Branch in Combinatorial Optimization with Graph Pointer Networks
Jul 04, 2023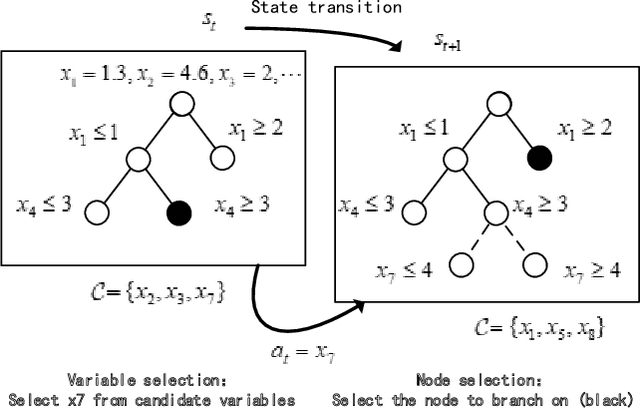
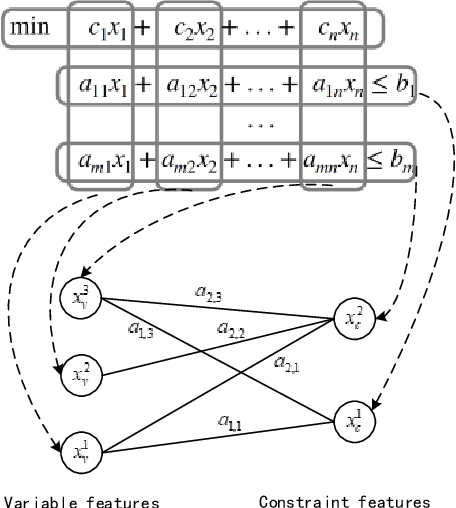


Branch-and-bound is a typical way to solve combinatorial optimization problems. This paper proposes a graph pointer network model for learning the variable selection policy in the branch-and-bound. We extract the graph features, global features and historical features to represent the solver state. The proposed model, which combines the graph neural network and the pointer mechanism, can effectively map from the solver state to the branching variable decisions. The model is trained to imitate the classic strong branching expert rule by a designed top-k Kullback-Leibler divergence loss function. Experiments on a series of benchmark problems demonstrate that the proposed approach significantly outperforms the widely used expert-designed branching rules. Our approach also outperforms the state-of-the-art machine-learning-based branch-and-bound methods in terms of solving speed and search tree size on all the test instances. In addition, the model can generalize to unseen instances and scale to larger instances.
One Adapter for All Programming Languages? Adapter Tuning for Code Search and Summarization
Mar 28, 2023As pre-trained models automate many code intelligence tasks, a widely used paradigm is to fine-tune a model on the task dataset for each programming language. A recent study reported that multilingual fine-tuning benefits a range of tasks and models. However, we find that multilingual fine-tuning leads to performance degradation on recent models UniXcoder and CodeT5. To alleviate the potentially catastrophic forgetting issue in multilingual models, we fix all pre-trained model parameters, insert the parameter-efficient structure adapter, and fine-tune it. Updating only 0.6\% of the overall parameters compared to full-model fine-tuning for each programming language, adapter tuning yields consistent improvements on code search and summarization tasks, achieving state-of-the-art results. In addition, we experimentally show its effectiveness in cross-lingual and low-resource scenarios. Multilingual fine-tuning with 200 samples per programming language approaches the results fine-tuned with the entire dataset on code summarization. Our experiments on three probing tasks show that adapter tuning significantly outperforms full-model fine-tuning and effectively overcomes catastrophic forgetting.
SAIH: A Scalable Evaluation Methodology for Understanding AI Performance Trend on HPC Systems
Dec 07, 2022Novel artificial intelligence (AI) technology has expedited various scientific research, e.g., cosmology, physics and bioinformatics, inevitably becoming a significant category of workload on high performance computing (HPC) systems. Existing AI benchmarks tend to customize well-recognized AI applications, so as to evaluate the AI performance of HPC systems under predefined problem size, in terms of datasets and AI models. Due to lack of scalability on the problem size, static AI benchmarks might be under competent to help understand the performance trend of evolving AI applications on HPC systems, in particular, the scientific AI applications on large-scale systems. In this paper, we propose a scalable evaluation methodology (SAIH) for analyzing the AI performance trend of HPC systems with scaling the problem sizes of customized AI applications. To enable scalability, SAIH builds a set of novel mechanisms for augmenting problem sizes. As the data and model constantly scale, we can investigate the trend and range of AI performance on HPC systems, and further diagnose system bottlenecks. To verify our methodology, we augment a cosmological AI application to evaluate a real HPC system equipped with GPUs as a case study of SAIH.
Bridging Pre-trained Models and Downstream Tasks for Source Code Understanding
Dec 04, 2021



With the great success of pre-trained models, the pretrain-then-finetune paradigm has been widely adopted on downstream tasks for source code understanding. However, compared to costly training a large-scale model from scratch, how to effectively adapt pre-trained models to a new task has not been fully explored. In this paper, we propose an approach to bridge pre-trained models and code-related tasks. We exploit semantic-preserving transformation to enrich downstream data diversity, and help pre-trained models learn semantic features invariant to these semantically equivalent transformations. Further, we introduce curriculum learning to organize the transformed data in an easy-to-hard manner to fine-tune existing pre-trained models. We apply our approach to a range of pre-trained models, and they significantly outperform the state-of-the-art models on tasks for source code understanding, such as algorithm classification, code clone detection, and code search. Our experiments even show that without heavy pre-training on code data, natural language pre-trained model RoBERTa fine-tuned with our lightweight approach could outperform or rival existing code pre-trained models fine-tuned on the above tasks, such as CodeBERT and GraphCodeBERT. This finding suggests that there is still much room for improvement in code pre-trained models.
CD-SGD: Distributed Stochastic Gradient Descent with Compression and Delay Compensation
Jun 21, 2021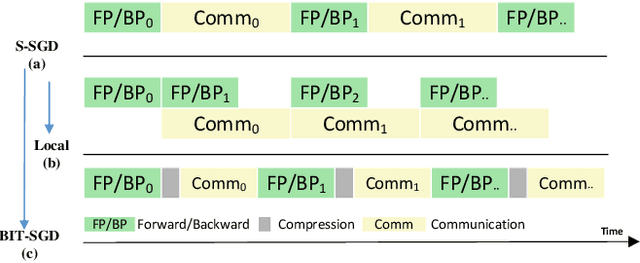



Communication overhead is the key challenge for distributed training. Gradient compression is a widely used approach to reduce communication traffic. When combining with parallel communication mechanism method like pipeline, gradient compression technique can greatly alleviate the impact of communication overhead. However, there exists two problems of gradient compression technique to be solved. Firstly, gradient compression brings in extra computation cost, which will delay the next training iteration. Secondly, gradient compression usually leads to the decrease of convergence accuracy.
deGraphCS: Embedding Variable-based Flow Graph for Neural Code Search
Mar 24, 2021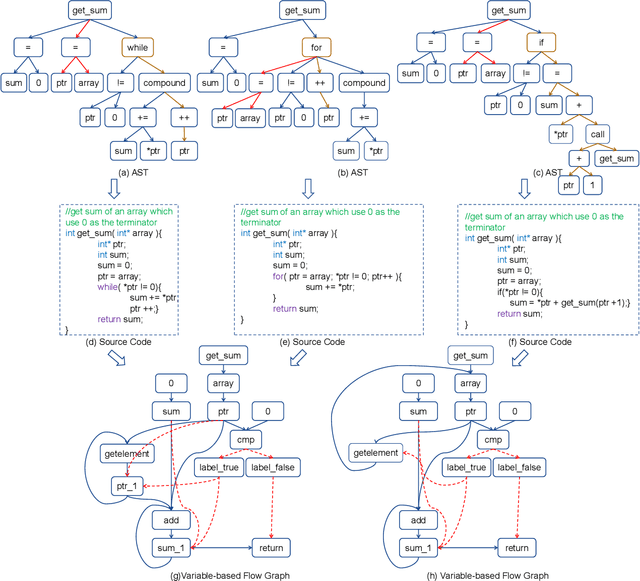
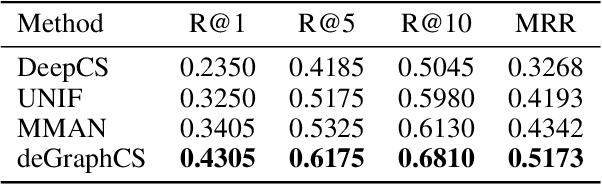
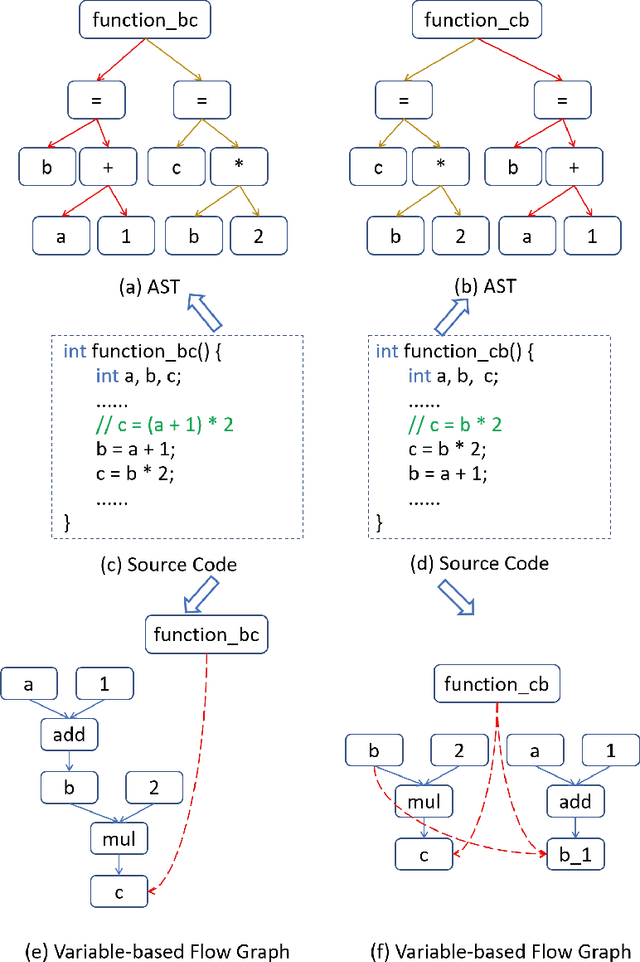

With the rapid increase in the amount of public code repositories, developers maintain a great desire to retrieve precise code snippets by using natural language. Despite existing deep learning based approaches(e.g., DeepCS and MMAN) have provided the end-to-end solutions (i.e., accepts natural language as queries and shows related code fragments retrieved directly from code corpus), the accuracy of code search in the large-scale repositories is still limited by the code representation (e.g., AST) and modeling (e.g., directly fusing the features in the attention stage). In this paper, we propose a novel learnable deep Graph for Code Search (calleddeGraphCS), to transfer source code into variable-based flow graphs based on the intermediate representation technique, which can model code semantics more precisely compared to process the code as text directly or use the syntactic tree representation. Furthermore, we propose a well-designed graph optimization mechanism to refine the code representation, and apply an improved gated graph neural network to model variable-based flow graphs. To evaluate the effectiveness of deGraphCS, we collect a large-scale dataset from GitHub containing 41,152 code snippets written in C language, and reproduce several typical deep code search methods for comparison. Besides, we design a qualitative user study to verify the practical value of our approach. The experimental results have shown that deGraphCS can achieve state-of-the-art performances, and accurately retrieve code snippets satisfying the needs of the users.
OD-SGD: One-step Delay Stochastic Gradient Descent for Distributed Training
May 14, 2020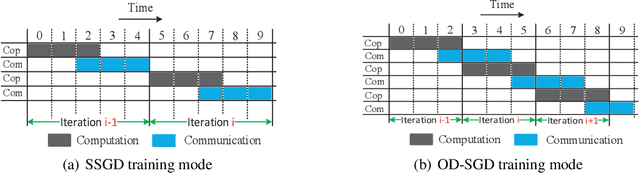

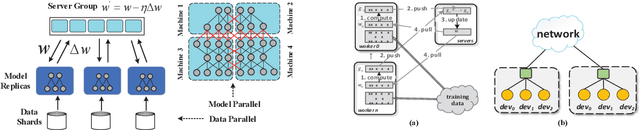

The training of modern deep learning neural network calls for large amounts of computation, which is often provided by GPUs or other specific accelerators. To scale out to achieve faster training speed, two update algorithms are mainly applied in the distributed training process, i.e. the Synchronous SGD algorithm (SSGD) and Asynchronous SGD algorithm (ASGD). SSGD obtains good convergence point while the training speed is slowed down by the synchronous barrier. ASGD has faster training speed but the convergence point is lower when compared to SSGD. To sufficiently utilize the advantages of SSGD and ASGD, we propose a novel technology named One-step Delay SGD (OD-SGD) to combine their strengths in the training process. Therefore, we can achieve similar convergence point and training speed as SSGD and ASGD separately. To the best of our knowledge, we make the first attempt to combine the features of SSGD and ASGD to improve distributed training performance. Each iteration of OD-SGD contains a global update in the parameter server node and local updates in the worker nodes, the local update is introduced to update and compensate the delayed local weights. We evaluate our proposed algorithm on MNIST, CIFAR-10 and ImageNet datasets. Experimental results show that OD-SGD can obtain similar or even slightly better accuracy than SSGD, while its training speed is much faster, which even exceeds the training speed of ASGD.