 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnlineAnySeg: Online Zero-Shot 3D Segmentation by Visual Foundation Model Guided 2D Mask Merging
Mar 03, 2025Online 3D open-vocabulary segmentation of a progressively reconstructed scene is both a critical and challenging task for embodied applications. With the success of visual foundation models (VFMs) in the image domain, leveraging 2D priors to address 3D online segmentation has become a prominent research focus. Since segmentation results provided by 2D priors often require spatial consistency to be lifted into final 3D segmentation, an efficient method for identifying spatial overlap among 2D masks is essential - yet existing methods rarely achieve this in real time, mainly limiting its use to offline approaches. To address this, we propose an efficient method that lifts 2D masks generated by VFMs into a unified 3D instance using a hashing technique. By employing voxel hashing for efficient 3D scene querying, our approach reduces the time complexity of costly spatial overlap queries from $O(n^2)$ to $O(n)$. Accurate spatial associations further enable 3D merging of 2D masks through simple similarity-based filtering in a zero-shot manner, making our approach more robust to incomplete and noisy data. Evaluated on the ScanNet and SceneNN benchmarks, our approach achieves state-of-the-art performance in online, open-vocabulary 3D instance segmentation with leading efficiency.
Mitigating Sensitive Information Leakage in LLMs4Code through Machine Unlearning
Feb 09, 2025



Large Language Models for Code (LLMs4Code) excel at code generation tasks, yielding promise to release developers from huge software development burdens. Nonetheless, these models have been shown to suffer from the significant privacy risks due to the potential leakage of sensitive information embedded during training, known as the memorization problem. Addressing this issue is crucial for ensuring privacy compliance and upholding user trust, but till now there is a dearth of dedicated studies in the literature that focus on this specific direction. Recently, machine unlearning has emerged as a promising solution by enabling models to "forget" sensitive information without full retraining, offering an efficient and scalable approach compared to traditional data cleaning methods. In this paper, we empirically evaluate the effectiveness of unlearning techniques for addressing privacy concerns in LLMs4Code.Specifically, we investigate three state-of-the-art unlearning algorithms and three well-known open-sourced LLMs4Code, on a benchmark that takes into consideration both the privacy data to be forgotten as well as the code generation capabilites of these models. Results show that it is feasible to mitigate the privacy concerns of LLMs4Code through machine unlearning while maintain their code generation capabilities at the same time. We also dissect the forms of privacy protection/leakage after unlearning and observe that there is a shift from direct leakage to indirect leakage, which underscores the need for future studies addressing this risk.
CD-SGD: Distributed Stochastic Gradient Descent with Compression and Delay Compensation
Jun 21, 2021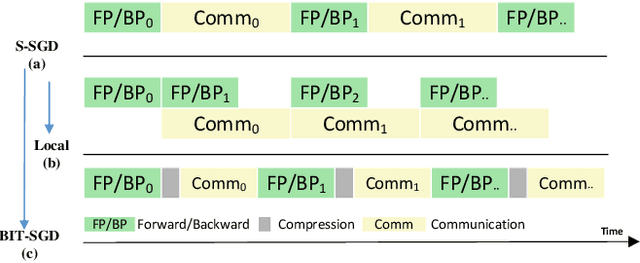



Communication overhead is the key challenge for distributed training. Gradient compression is a widely used approach to reduce communication traffic. When combining with parallel communication mechanism method like pipeline, gradient compression technique can greatly alleviate the impact of communication overhead. However, there exists two problems of gradient compression technique to be solved. Firstly, gradient compression brings in extra computation cost, which will delay the next training iteration. Secondly, gradient compression usually leads to the decrease of convergence accuracy.
OD-SGD: One-step Delay Stochastic Gradient Descent for Distributed Training
May 14, 2020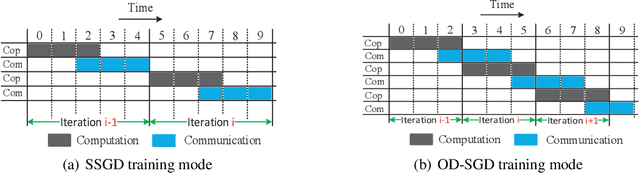


The training of modern deep learning neural network calls for large amounts of computation, which is often provided by GPUs or other specific accelerators. To scale out to achieve faster training speed, two update algorithms are mainly applied in the distributed training process, i.e. the Synchronous SGD algorithm (SSGD) and Asynchronous SGD algorithm (ASGD). SSGD obtains good convergence point while the training speed is slowed down by the synchronous barrier. ASGD has faster training speed but the convergence point is lower when compared to SSGD. To sufficiently utilize the advantages of SSGD and ASGD, we propose a novel technology named One-step Delay SGD (OD-SGD) to combine their strengths in the training process. Therefore, we can achieve similar convergence point and training speed as SSGD and ASGD separately. To the best of our knowledge, we make the first attempt to combine the features of SSGD and ASGD to improve distributed training performance. Each iteration of OD-SGD contains a global update in the parameter server node and local updates in the worker nodes, the local update is introduced to update and compensate the delayed local weights. We evaluate our proposed algorithm on MNIST, CIFAR-10 and ImageNet datasets. Experimental results show that OD-SGD can obtain similar or even slightly better accuracy than SSGD, while its training speed is much faster, which even exceeds the training speed of ASGD.
Communication Optimization Strategies for Distributed Deep Learning: A Survey
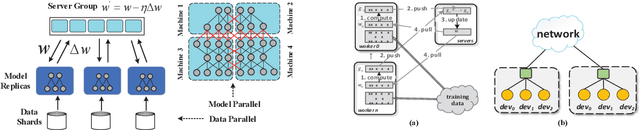
Mar 06, 2020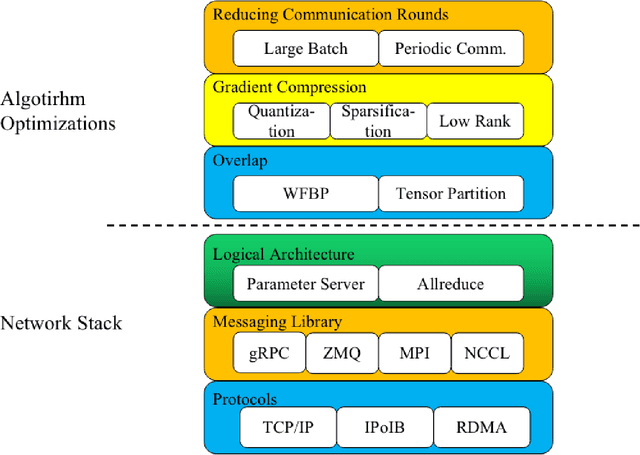

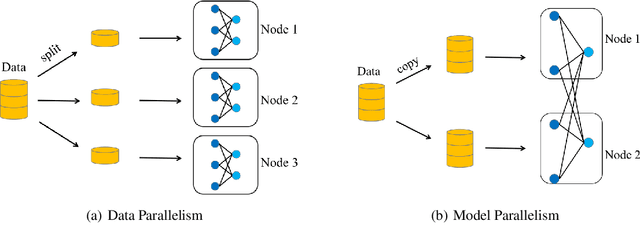

Recent trends in high-performance computing and deep learning lead to a proliferation of studies on large-scale deep neural network (DNN) training. However, the frequent communication requirements among computation nodes drastically slow down the overall training speed, which makes the bottleneck in distributed training, particularly in clusters with limited network bandwidth. To mitigate the drawbacks of distributed communication, researchers have proposed various optimization strategies. In this paper, we give a comprehensive survey of communication strategies from both algorithm and computer network perspectives. Algorithm optimizations focus on reducing the amount of communication in distributed training, while network optimizations focus on speeding up the communication between distributed devices. At the algorithm level, we describe how to reduce the number of communication rounds and transmitted bits per round, besides we shed light on how to overlap computation and communication. At the network level, we discuss the effect caused by network infrastructures, including communication schemes, network protocols, and topology. Finally, we extrapolate potential challenges and research directions for communication acceleration in distributed DNN training.