 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Tabular Foundation Models Meet Strategic Tabular Data: A Prior Alignment Approach
May 19, 2026Tabular foundation models based on pretrained prior-data fitted networks~(PFNs) have shown strong generalization on diverse tabular tasks, but they are typically designed for \emph{non-strategic} settings where data distributions are independent of deployed classifiers. In many real-world decision scenarios, however, individuals may strategically modify their features after deployment to obtain favorable outcomes, inducing a post-deployment distribution shift. This paper studies whether PFN-style tabular foundation models can generalize to such \emph{strategic} tabular data. We show that strategic manipulation creates a mismatch between the non-strategic prior learned during pretraining and the post-manipulation strategic prior, which leads to systematic prediction bias. To address this issue, we propose \textbf{Strategic Prior-data Fitted Network}~\textit{(SPN)}, an inference-time strategy-aware framework that adapts tabular foundation models to strategic environments without retraining. SPN constructs strategic in-context examples to approximate post-manipulation inputs and aligns PFN predictions with the induced strategic distribution. Experiments on real-world and synthetic tabular datasets show that SPN consistently improves robustness and predictive performance under strategic manipulation compared with both tabular foundation models and classical tabular methods.
We Need a More Robust Classifier: Dual Causal Learning Empowers Domain-Incremental Time Series Classification
Jan 15, 2026The World Wide Web thrives on intelligent services that rely on accurate time series classification, which has recently witnessed significant progress driven by advances in deep learning. However, existing studies face challenges in domain incremental learning. In this paper, we propose a lightweight and robust dual-causal disentanglement framework (DualCD) to enhance the robustness of models under domain incremental scenarios, which can be seamlessly integrated into time series classification models. Specifically, DualCD first introduces a temporal feature disentanglement module to capture class-causal features and spurious features. The causal features can offer sufficient predictive power to support the classifier in domain incremental learning settings. To accurately capture these causal features, we further design a dual-causal intervention mechanism to eliminate the influence of both intra-class and inter-class confounding features. This mechanism constructs variant samples by combining the current class's causal features with intra-class spurious features and with causal features from other classes. The causal intervention loss encourages the model to accurately predict the labels of these variant samples based solely on the causal features. Extensive experiments on multiple datasets and models demonstrate that DualCD effectively improves performance in domain incremental scenarios. We summarize our rich experiments into a comprehensive benchmark to facilitate research in domain incremental time series classification.
UniSearch: Rethinking Search System with a Unified Generative Architecture
Sep 10, 2025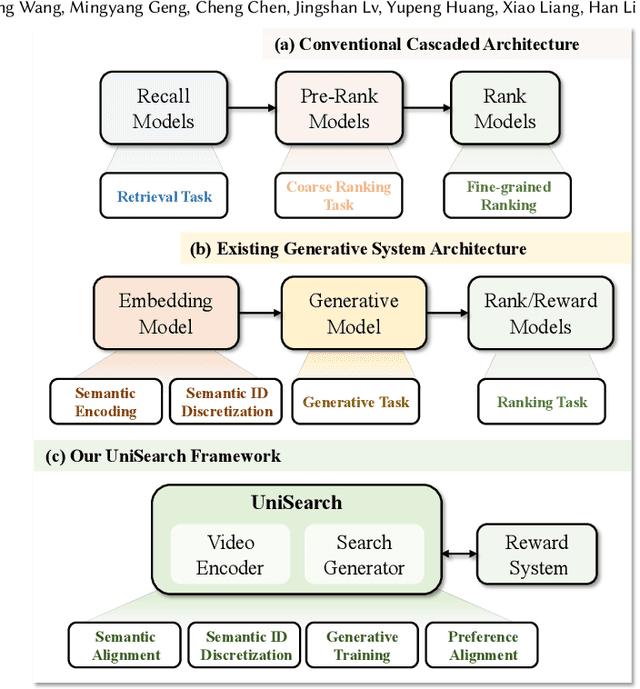
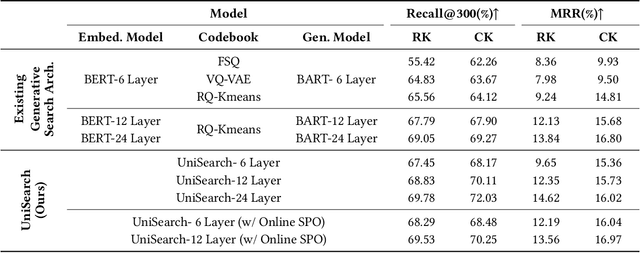
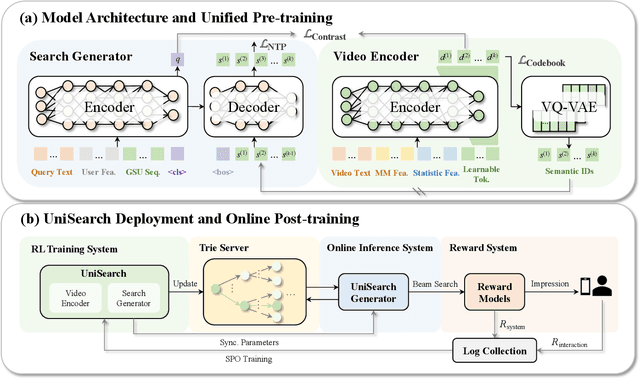
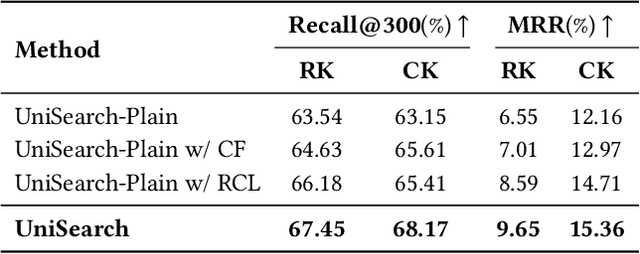
Modern search systems play a crucial role in facilitating information acquisition. Traditional search engines typically rely on a cascaded architecture, where results are retrieved through recall, pre-ranking, and ranking stages. The complexity of designing and maintaining multiple modules makes it difficult to achieve holistic performance gains. Recent advances in generative recommendation have motivated the exploration of unified generative search as an alternative. However, existing approaches are not genuinely end-to-end: they typically train an item encoder to tokenize candidates first and then optimize a generator separately, leading to objective inconsistency and limited generalization. To address these limitations, we propose UniSearch, a unified generative search framework for Kuaishou Search. UniSearch replaces the cascaded pipeline with an end-to-end architecture that integrates a Search Generator and a Video Encoder. The Generator produces semantic identifiers of relevant items given a user query, while the Video Encoder learns latent item embeddings and provides their tokenized representations. A unified training framework jointly optimizes both components, enabling mutual enhancement and improving representation quality and generation accuracy. Furthermore, we introduce Search Preference Optimization (SPO), which leverages a reward model and real user feedback to better align generation with user preferences. Extensive experiments on industrial-scale datasets, together with online A/B testing in both short-video and live search scenarios, demonstrate the strong effectiveness and deployment potential of UniSearch. Notably, its deployment in live search yields the largest single-experiment improvement in recent years of our product's history, highlighting its practical value for real-world applications.
Mitigating Sensitive Information Leakage in LLMs4Code through Machine Unlearning
Feb 09, 2025



Large Language Models for Code (LLMs4Code) excel at code generation tasks, yielding promise to release developers from huge software development burdens. Nonetheless, these models have been shown to suffer from the significant privacy risks due to the potential leakage of sensitive information embedded during training, known as the memorization problem. Addressing this issue is crucial for ensuring privacy compliance and upholding user trust, but till now there is a dearth of dedicated studies in the literature that focus on this specific direction. Recently, machine unlearning has emerged as a promising solution by enabling models to "forget" sensitive information without full retraining, offering an efficient and scalable approach compared to traditional data cleaning methods. In this paper, we empirically evaluate the effectiveness of unlearning techniques for addressing privacy concerns in LLMs4Code.Specifically, we investigate three state-of-the-art unlearning algorithms and three well-known open-sourced LLMs4Code, on a benchmark that takes into consideration both the privacy data to be forgotten as well as the code generation capabilites of these models. Results show that it is feasible to mitigate the privacy concerns of LLMs4Code through machine unlearning while maintain their code generation capabilities at the same time. We also dissect the forms of privacy protection/leakage after unlearning and observe that there is a shift from direct leakage to indirect leakage, which underscores the need for future studies addressing this risk.
deGraphCS: Embedding Variable-based Flow Graph for Neural Code Search
Mar 24, 2021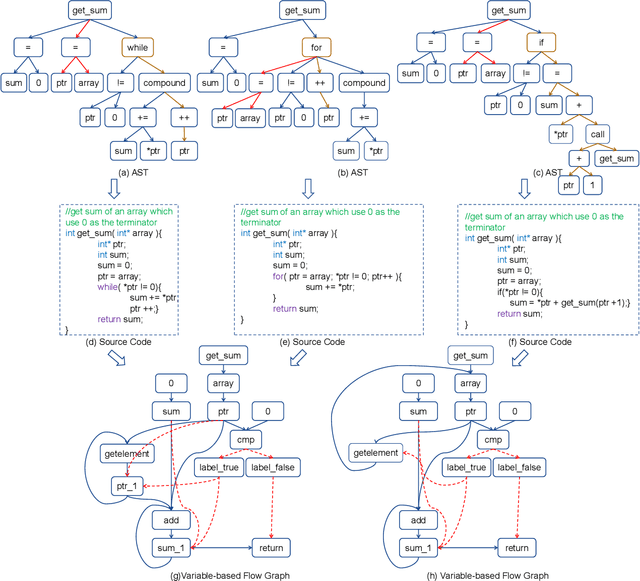
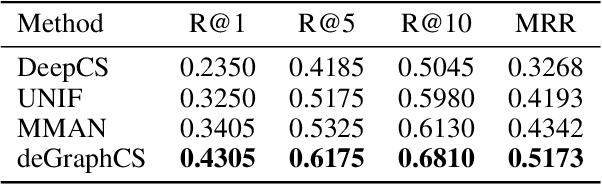
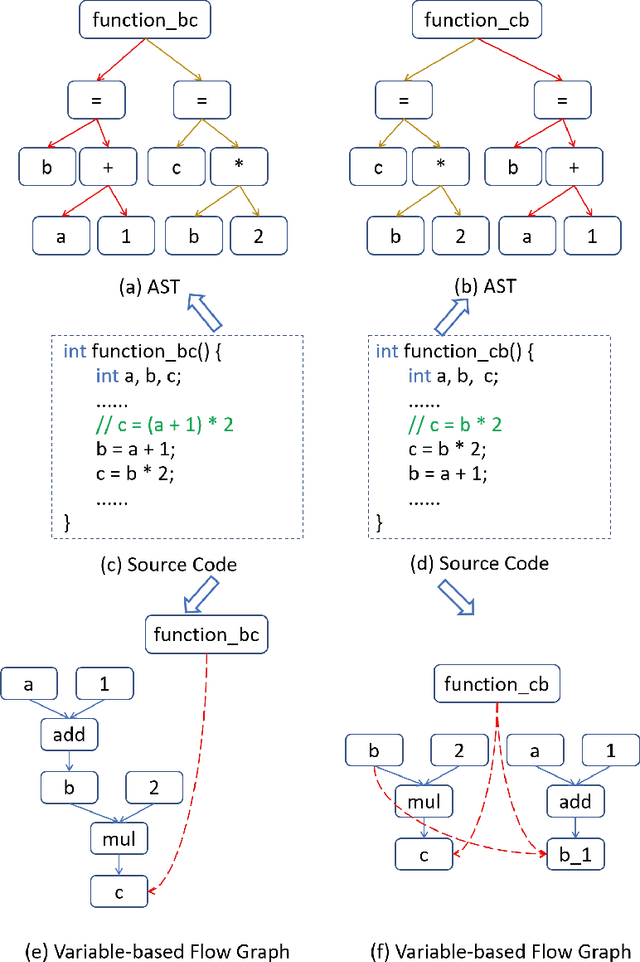

With the rapid increase in the amount of public code repositories, developers maintain a great desire to retrieve precise code snippets by using natural language. Despite existing deep learning based approaches(e.g., DeepCS and MMAN) have provided the end-to-end solutions (i.e., accepts natural language as queries and shows related code fragments retrieved directly from code corpus), the accuracy of code search in the large-scale repositories is still limited by the code representation (e.g., AST) and modeling (e.g., directly fusing the features in the attention stage). In this paper, we propose a novel learnable deep Graph for Code Search (calleddeGraphCS), to transfer source code into variable-based flow graphs based on the intermediate representation technique, which can model code semantics more precisely compared to process the code as text directly or use the syntactic tree representation. Furthermore, we propose a well-designed graph optimization mechanism to refine the code representation, and apply an improved gated graph neural network to model variable-based flow graphs. To evaluate the effectiveness of deGraphCS, we collect a large-scale dataset from GitHub containing 41,152 code snippets written in C language, and reproduce several typical deep code search methods for comparison. Besides, we design a qualitative user study to verify the practical value of our approach. The experimental results have shown that deGraphCS can achieve state-of-the-art performances, and accurately retrieve code snippets satisfying the needs of the users.
Attention-based Fault-tolerant Approach for Multi-agent Reinforcement Learning Systems
Oct 05, 2019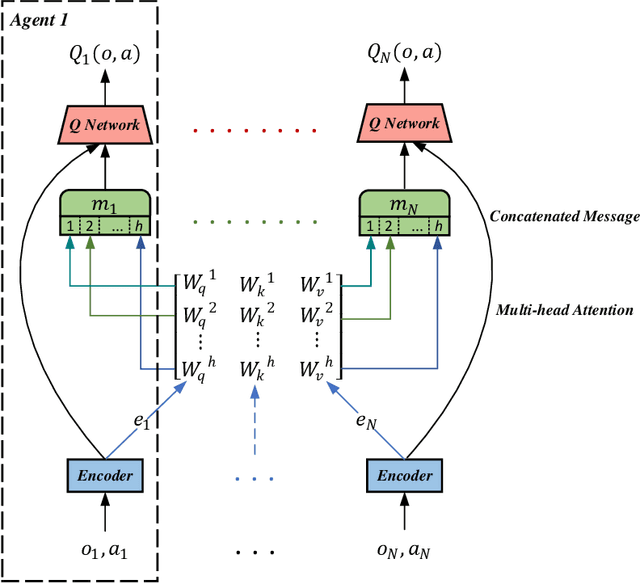
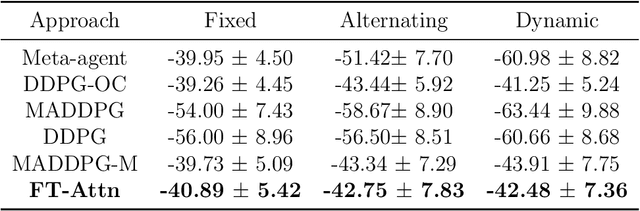
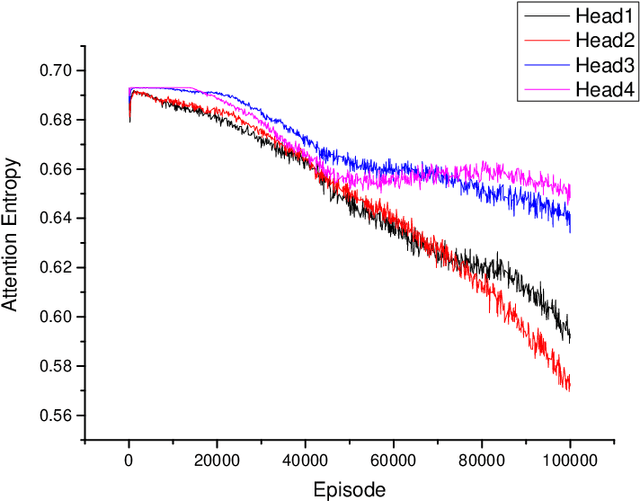
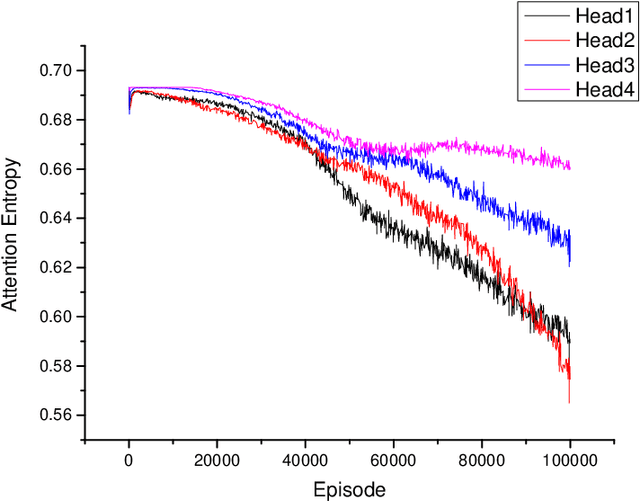
The aim of multi-agent reinforcement learning systems is to provide interacting agents with the ability to collaboratively learn and adapt to the behavior of other agents. In many real-world applications, the agents can only acquire a partial view of the world. However, in realistic settings, one or more agents that show arbitrarily faulty or malicious behavior may suffice to let the current coordination mechanisms fail. In this paper, we study a practical scenario considering the security issues in the presence of agents with arbitrarily faulty or malicious behavior. Under these circumstances, learning an optimal policy becomes particularly challenging, even in the unrealistic case that an agent's policy can be made conditional upon all other agents' observations. To overcome these difficulties, we present an Attention-based Fault-Tolerant (FT-Attn) algorithm which selects correct and relevant information for each agent at every time-step. The multi-head attention mechanism enables the agents to learn effective communication policies through experience concurrently to the action policies. Empirical results have shown that FT-Attn beats previous state-of-the-art methods in some complex environments and can adapt to various kinds of noisy environments without tuning the complexity of the algorithm. Furthermore, FT-Attn can effectively deal with the complex situation where an agent needs to reach multiple agents' correct observation at the same time.
Unsupervised Learning-based Depth Estimation aided Visual SLAM Approach
Jan 22, 2019

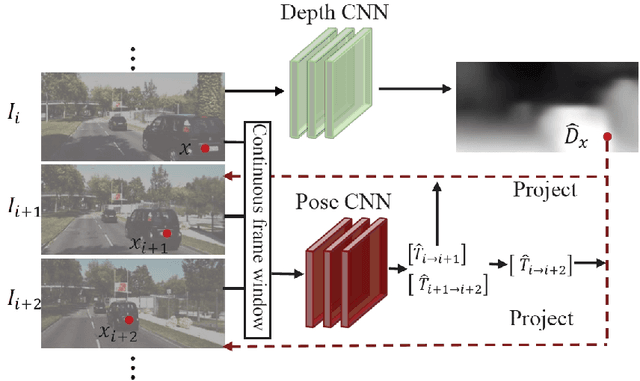
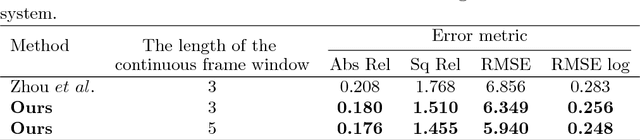
The RGB-D camera maintains a limited range for working and is hard to accurately measure the depth information in a far distance. Besides, the RGB-D camera will easily be influenced by strong lighting and other external factors, which will lead to a poor accuracy on the acquired environmental depth information. Recently, deep learning technologies have achieved great success in the visual SLAM area, which can directly learn high-level features from the visual inputs and improve the estimation accuracy of the depth information. Therefore, deep learning technologies maintain the potential to extend the source of the depth information and improve the performance of the SLAM system. However, the existing deep learning-based methods are mainly supervised and require a large amount of ground-truth depth data, which is hard to acquire because of the realistic constraints. In this paper, we first present an unsupervised learning framework, which not only uses image reconstruction for supervising but also exploits the pose estimation method to enhance the supervised signal and add training constraints for the task of monocular depth and camera motion estimation. Furthermore, we successfully exploit our unsupervised learning framework to assist the traditional ORB-SLAM system when the initialization module of ORB-SLAM method could not match enough features. Qualitative and quantitative experiments have shown that our unsupervised learning framework performs the depth estimation task comparable to the supervised methods and outperforms the previous state-of-the-art approach by $13.5\%$ on KITTI dataset. Besides, our unsupervised learning framework could significantly accelerate the initialization process of ORB-SLAM system and effectively improve the accuracy on environmental mapping in strong lighting and weak texture scenes.
Learning data augmentation policies using augmented random search
Nov 12, 2018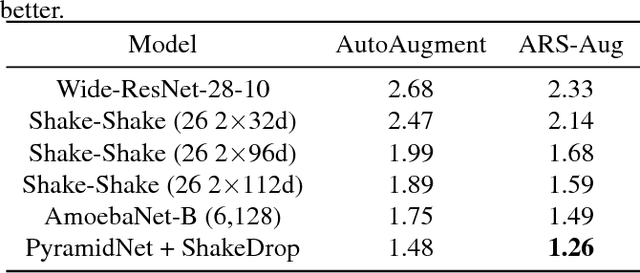


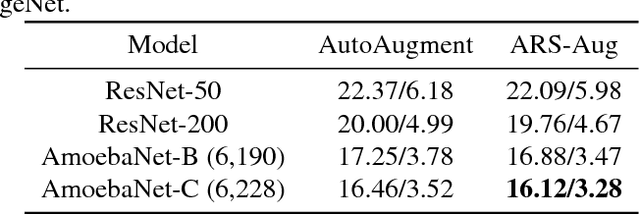
Previous attempts for data augmentation are designed manually, and the augmentation policies are dataset-specific. Recently, an automatic data augmentation approach, named AutoAugment, is proposed using reinforcement learning. AutoAugment searches for the augmentation polices in the discrete search space, which may lead to a sub-optimal solution. In this paper, we employ the Augmented Random Search method (ARS) to improve the performance of AutoAugment. Our key contribution is to change the discrete search space to continuous space, which will improve the searching performance and maintain the diversities between sub-policies. With the proposed method, state-of-the-art accuracies are achieved on CIFAR-10, CIFAR-100, and ImageNet (without additional data). Our code is available at https://github.com/gmy2013/ARS-Aug.