 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-based Fault-tolerant Approach for Multi-agent Reinforcement Learning Systems
Paper and Code
Oct 05, 2019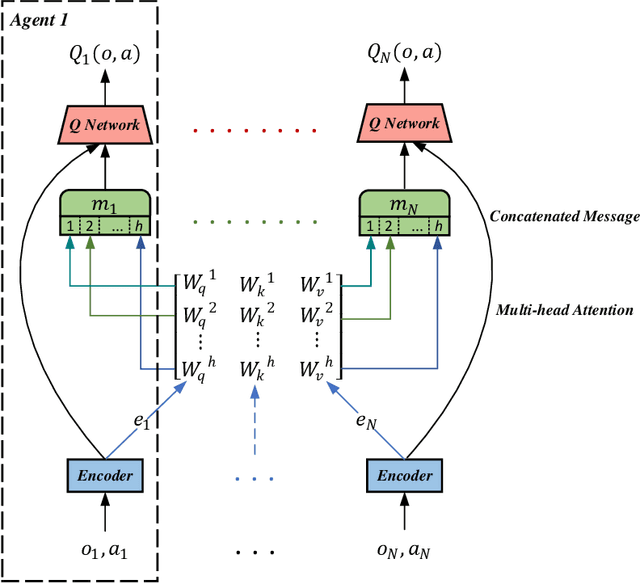
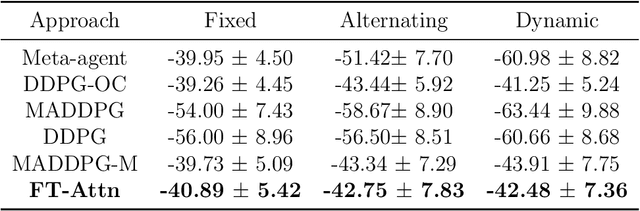
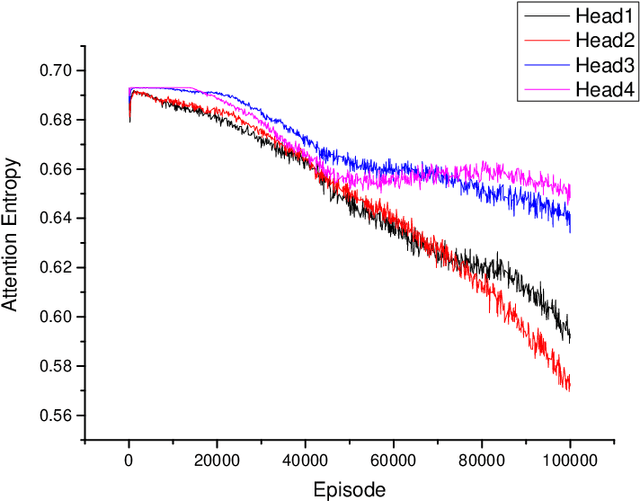
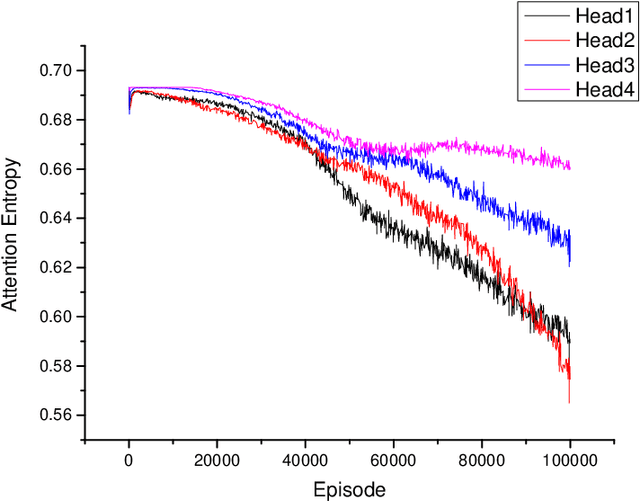
The aim of multi-agent reinforcement learning systems is to provide interacting agents with the ability to collaboratively learn and adapt to the behavior of other agents. In many real-world applications, the agents can only acquire a partial view of the world. However, in realistic settings, one or more agents that show arbitrarily faulty or malicious behavior may suffice to let the current coordination mechanisms fail. In this paper, we study a practical scenario considering the security issues in the presence of agents with arbitrarily faulty or malicious behavior. Under these circumstances, learning an optimal policy becomes particularly challenging, even in the unrealistic case that an agent's policy can be made conditional upon all other agents' observations. To overcome these difficulties, we present an Attention-based Fault-Tolerant (FT-Attn) algorithm which selects correct and relevant information for each agent at every time-step. The multi-head attention mechanism enables the agents to learn effective communication policies through experience concurrently to the action policies. Empirical results have shown that FT-Attn beats previous state-of-the-art methods in some complex environments and can adapt to various kinds of noisy environments without tuning the complexity of the algorithm. Furthermore, FT-Attn can effectively deal with the complex situation where an agent needs to reach multiple agents' correct observation at the same time.