 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParetoPilot: Zero-Surrogate Offline Multi-Objective Optimization via Infer-Perturb-Guide Diffusion
Jun 03, 2026Offline multi-objective optimization (Offline MOO) aims to discover novel Pareto-optimal designs based on static datasets without expensive environment interactions. While recent generative methods have achieved notable success, they predominantly rely on external surrogate models. This dependency introduces significant computational overhead, suffers from deceptive evaluations, and deviates from the prevailing paradigm of jointly training mainstream generative models with conditions. To address these bottlenecks, we propose ParetoPilot, a novel zero-surrogate diffusion framework for offline MOO. ParetoPilot fully leverages the conditional priors inherently embedded within pre-trained diffusion models. At its core, the framework introduces the Infer-Perturb-Guide (IPG) engine, which is seamlessly interleaved within the unconditional denoising steps of the reverse generation process. First, it implicitly infers the instantaneous objective direction by matching conditional and unconditional noise predictions. Next, it mathematically orthogonalizes a parallel gravity field for strict convergence and an edgeness-aware repulsive force for mutual diversity, creating a dynamically annealed perturbation vector. Finally, this perturbed target seamlessly steers the generation process via standard Classifier-Free Guidance (CFG). Extensive experiments across 51 tasks demonstrate that ParetoPilot outperforms 14 state-of-the-art surrogate-based and inverse generative baselines. By eliminating auxiliary proxy training, our approach preserves data privacy while achieving hypervolume improvement and robust Pareto front coverage.
MAny: Merge Anything for Multimodal Continual Instruction Tuning
Apr 15, 2026Multimodal Continual Instruction Tuning (MCIT) is essential for sequential task adaptation of Multimodal Large Language Models (MLLMs) but is severely restricted by catastrophic forgetting. While existing literature focuses on the reasoning language backbone, in this work, we expose a critical yet neglected dual-forgetting phenomenon across both perception drift in Cross-modal Projection Space and reasoning collapse in Low-rank Parameter Space. To resolve this, we present \textbf{MAny} (\textbf{M}erge \textbf{Any}thing), a framework that merges task-specific knowledge through \textbf{C}ross-modal \textbf{P}rojection \textbf{M}erging (\textbf{CPM}) and \textbf{L}ow-rank \textbf{P}arameter \textbf{M}erging (\textbf{LPM}). Specifically, CPM recovers perceptual alignment by adaptively merging cross-modal visual representations via visual-prototype guidance, ensuring accurate feature recovery during inference. Simultaneously, LPM eliminates mutual interference among task-specific low-rank modules by recursively merging low-rank weight matrices. By leveraging recursive least squares, LPM provides a closed-form solution that mathematically guarantees an optimal fusion trajectory for reasoning stability. Notably, MAny operates as a training-free paradigm that achieves knowledge merging via efficient CPU-based algebraic operations, eliminating additional gradient-based optimization beyond initial tuning. Our extensive evaluations confirm the superior performance and robustness of MAny across multiple MLLMs and benchmarks. Specifically, on the UCIT benchmark, MAny achieves significant leads of up to 8.57\% and 2.85\% in final average accuracy over state-of-the-art methods across two different MLLMs, respectively.
Beyond Scores: Diagnostic LLM Evaluation via Fine-Grained Abilities
Apr 14, 2026Current evaluations of large language models aggregate performance across diverse tasks into single scores. This obscures fine-grained ability variation, limiting targeted model improvement and ability-guided selection for specific tasks. Motivated by this gap, we propose a cognitive diagnostic framework that estimates model abilities across multiple fine-grained dimensions. For mathematics, we construct a 35-dimensional ability taxonomy grounded in cognitive theory and domain knowledge. The framework employs multidimensional Item Response Theory with an item-ability association matrix to estimate fine-grained ability levels, which in turn enable prediction of performance on unseen items (questions of benchmark). Evaluated on 41 models, our approach demonstrates strong criterion validity, consistent ability estimates across benchmarks, and accurate prediction of unseen items with AUC ranging from 0.80 to 0.89 within benchmarks and from 0.77 to 0.86 across benchmarks, substantially exceeding trivial baselines. The framework generalizes across scientific domains, producing consistent diagnostic performance in physics (27 dimensions), chemistry (58 dimensions), and computer science (12 dimensions). This work establishes a principled framework for fine-grained assessment of abilities, with potential applications in targeted training, ability-guided model selection, and ability-aware benchmark design.
NTIRE 2026 The Second Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 12, 2026This paper presents an overview of the NTIRE 2026 Second Challenge on Day and Night Raindrop Removal for Dual-Focused Images. Building upon the success of the first edition, this challenge attracted a wide range of impressive solutions, all developed and evaluated on our real-world Raindrop Clarity dataset~\cite{jin2024raindrop}. For this edition, we adjust the dataset with 14,139 images for training, 407 images for validation, and 593 images for testing. The primary goal of this challenge is to establish a strong and practical benchmark for the removal of raindrops under various illumination and focus conditions. In total, 168 teams have registered for the competition, and 17 teams submitted valid final solutions and fact sheets for the testing phase. The submitted methods achieved strong performance on the Raindrop Clarity dataset, demonstrating the growing progress in this challenging task.
Ranking Constraints via Topological Dual-Directional Search in Evolutionary Multi-Objective Optimization
Apr 06, 2026Existing evolutionary algorithms for Constrained Multi-objective Optimization Problems (CMOPs) typically treat all constraints uniformly, overlooking their distinct geometric relationships with the true Constrained Pareto Front (CPF). In reality, constraints play different roles: some directly shape the final CPF, some create infeasible obstacles, while others are irrelevant. To exploit this insight, we propose a novel algorithm named RCCMO, which sequentially performs unconstrained exploration, single-constraint exploitation, and full-constraint refinement. The core innovation of RCCMO lies in a constraint prioritization method derived from these geometric insights, seamlessly coupled with a unique dual-directional search mechanism. Specifically, RCCMO first prioritizes constraints that constitute the final CPF, approaching them from the evolutionary direction (optimizing objectives) to locate the CPF directly shaped by single-constraint boundaries. Subsequently, for constraints that merely hinder the population's progress, RCCMO searches from the anti-evolutionary direction (targeting the infeasible boundaries where hindering constraints intersect with the CPF) to effectively discover how these constraints obstruct and form the final CPF. Meanwhile, irrelevant constraints are intentionally bypassed. Furthermore, a series of specialized mechanisms are proposed to accelerate the algorithm's execution, reduce heuristic misjudgments, and dynamically adjust search directions in real time. Extensive experiments on 5 benchmark test suites and 29 real-world CMOPs demonstrate that RCCMO significantly outperforms seven state-of-the-art algorithms.
Decoupling Constraint from Two Direction in Evolutionary Constrained Multi-objective Optimization
Dec 30, 2025Real-world Constrained Multi-objective Optimization Problems (CMOPs) often contain multiple constraints, and understanding and utilizing the coupling between these constraints is crucial for solving CMOPs. However, existing Constrained Multi-objective Evolutionary Algorithms (CMOEAs) typically ignore these couplings and treat all constraints as a single aggregate, which lacks interpretability regarding the specific geometric roles of constraints. To address this limitation, we first analyze how different constraints interact and show that the final Constrained Pareto Front (CPF) depends not only on the Pareto fronts of individual constraints but also on the boundaries of infeasible regions. This insight implies that CMOPs with different coupling types must be solved from different search directions. Accordingly, we propose a novel algorithm named Decoupling Constraint from Two Directions (DCF2D). This method periodically detects constraint couplings and spawns an auxiliary population for each relevant constraint with an appropriate search direction. Extensive experiments on seven challenging CMOP benchmark suites and on a collection of real-world CMOPs demonstrate that DCF2D outperforms five state-of-the-art CMOEAs, including existing decoupling-based methods.
Propose and Rectify: A Forensics-Driven MLLM Framework for Image Manipulation Localization
Aug 25, 2025The increasing sophistication of image manipulation techniques demands robust forensic solutions that can both reliably detect alterations and precisely localize tampered regions. Recent Multimodal Large Language Models (MLLMs) show promise by leveraging world knowledge and semantic understanding for context-aware detection, yet they struggle with perceiving subtle, low-level forensic artifacts crucial for accurate manipulation localization. This paper presents a novel Propose-Rectify framework that effectively bridges semantic reasoning with forensic-specific analysis. In the proposal stage, our approach utilizes a forensic-adapted LLaVA model to generate initial manipulation analysis and preliminary localization of suspicious regions based on semantic understanding and contextual reasoning. In the rectification stage, we introduce a Forensics Rectification Module that systematically validates and refines these initial proposals through multi-scale forensic feature analysis, integrating technical evidence from several specialized filters. Additionally, we present an Enhanced Segmentation Module that incorporates critical forensic cues into SAM's encoded image embeddings, thereby overcoming inherent semantic biases to achieve precise delineation of manipulated regions. By synergistically combining advanced multimodal reasoning with established forensic methodologies, our framework ensures that initial semantic proposals are systematically validated and enhanced through concrete technical evidence, resulting in comprehensive detection accuracy and localization precision. Extensive experimental validation demonstrates state-of-the-art performance across diverse datasets with exceptional robustness and generalization capabilities.
Pay More Attention to the Robustness of Prompt for Instruction Data Mining
Mar 31, 2025Instruction tuning has emerged as a paramount method for tailoring the behaviors of LLMs. Recent work has unveiled the potential for LLMs to achieve high performance through fine-tuning with a limited quantity of high-quality instruction data. Building upon this approach, we further explore the impact of prompt's robustness on the selection of high-quality instruction data. This paper proposes a pioneering framework of high-quality online instruction data mining for instruction tuning, focusing on the impact of prompt's robustness on the data mining process. Our notable innovation, is to generate the adversarial instruction data by conducting the attack for the prompt of online instruction data. Then, we introduce an Adversarial Instruction-Following Difficulty metric to measure how much help the adversarial instruction data can provide to the generation of the corresponding response. Apart from it, we propose a novel Adversarial Instruction Output Embedding Consistency approach to select high-quality online instruction data. We conduct extensive experiments on two benchmark datasets to assess the performance. The experimental results serve to underscore the effectiveness of our proposed two methods. Moreover, the results underscore the critical practical significance of considering prompt's robustness.
Enhancing Decision-Making for LLM Agents via Step-Level Q-Value Models
Sep 14, 2024



Agents significantly enhance the capabilities of standalone Large Language Models (LLMs) by perceiving environments, making decisions, and executing actions. However, LLM agents still face challenges in tasks that require multiple decision-making steps. Estimating the value of actions in specific tasks is difficult when intermediate actions are neither appropriately rewarded nor penalized. In this paper, we propose leveraging a task-relevant Q-value model to guide action selection. Specifically, we first collect decision-making trajectories annotated with step-level Q values via Monte Carlo Tree Search (MCTS) and construct preference data. We then use another LLM to fit these preferences through step-level Direct Policy Optimization (DPO), which serves as the Q-value model. During inference, at each decision-making step, LLM agents select the action with the highest Q value before interacting with the environment. We apply our method to various open-source and API-based LLM agents, demonstrating that Q-value models significantly improve their performance. Notably, the performance of the agent built with Phi-3-mini-4k-instruct improved by 103% on WebShop and 75% on HotPotQA when enhanced with Q-value models, even surpassing GPT-4o-mini. Additionally, Q-value models offer several advantages, such as generalization to different LLM agents and seamless integration with existing prompting strategies.
Online Self-Preferring Language Models
May 23, 2024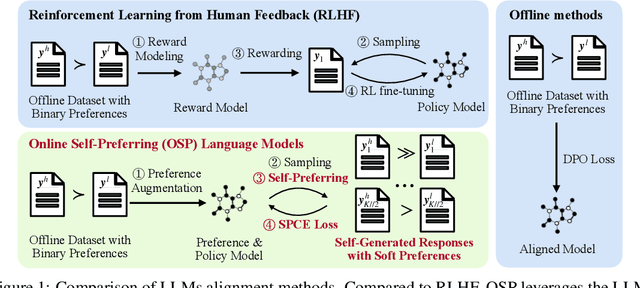
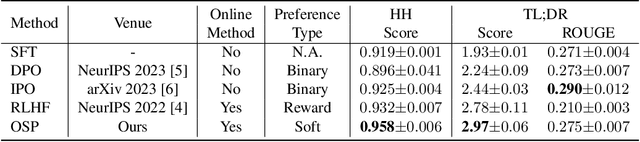
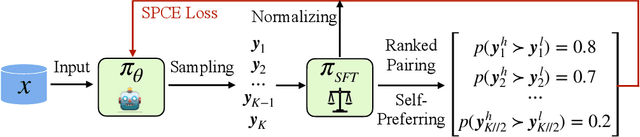
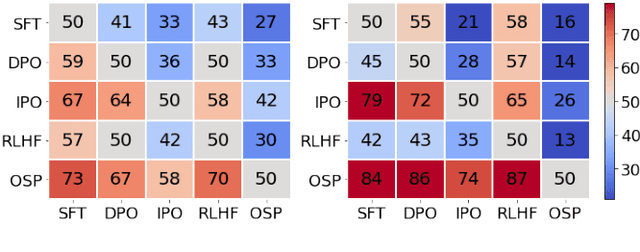
Aligning with human preference datasets has been critical to the success of large language models (LLMs). Reinforcement learning from human feedback (RLHF) employs a costly reward model to provide feedback for on-policy sampling responses. Recently, offline methods that directly fit responses with binary preferences in the dataset have emerged as alternatives. However, existing methods do not explicitly model preference strength information, which is crucial for distinguishing different response pairs. To overcome this limitation, we propose Online Self-Preferring (OSP) language models to learn from self-generated response pairs and self-judged preference strengths. For each prompt and corresponding self-generated responses, we introduce a ranked pairing method to construct multiple response pairs with preference strength information. We then propose the soft-preference cross-entropy loss to leverage such information. Empirically, we demonstrate that leveraging preference strength is crucial for avoiding overfitting and enhancing alignment performance. OSP achieves state-of-the-art alignment performance across various metrics in two widely used human preference datasets. OSP is parameter-efficient and more robust than the dominant online method, RLHF when limited offline data are available and generalizing to out-of-domain tasks. Moreover, OSP language models established by LLMs with proficiency in self-preferring can efficiently self-improve without external supervision.