 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDORA: Dynamic Online Reinforcement Agent for Token Merging in Vision Transformers
May 12, 2026Vision Transformers (ViTs) incur significant computational overhead due to the quadratic complexity of self-attention relative to the token sequence length. While existing token reduction methods mitigate this issue, they predominantly rely on fixed heuristic metrics, predefined ratios, or static offline masks, which lack the adaptability to capture input-dependent redundancy during inference. In this paper, we propose DORA (Dynamic Online Reinforcement Agent), the first reinforcement learning (RL)-driven online inference framework for dynamic token merging in ViTs. We formulate the merging process as a sequential Markov Decision Process (MDP), where a lightweight RL agent determines the merging strategy for each Transformer block based on the current feature state and layer-specific context. To balance computational efficiency and feature fidelity, the agent is optimized via a dense reward function incorporating a non-linear distillation-based penalty. We implement an asymmetric Actor-Critic architecture that utilizes a high-capacity Critic for stable offline training while retaining a minimal Actor head for low-computation online inference. Evaluations across multiple ViT scales (Tiny to Large) demonstrate that DORA improves the accuracy-efficiency Pareto front compared to current baselines. Under strict negligible accuracy-drop constraints (<= 0.05%), DORA achieves up to a 12.66% token merging rate, and delivers up to a 569.7% relative improvement over the most efficient baseline. On ImageNet-1K, under aligned accuracy constraints, DORA achieves up to a 76% relative improvement in computational savings compared to state-of-the-art methods. Furthermore, on out-of-distribution (OOD) benchmarks such as ImageNet-A and ImageNet-C, DORA attains a relative efficiency advantage of over 430%.
SLaB: Sparse-Lowrank-Binary Decomposition for Efficient Large Language Models
Apr 06, 2026The rapid growth of large language models (LLMs) presents significant deployment challenges due to their massive computational and memory demands. While model compression, such as network pruning, offers potential solutions, most existing methods often fail to maintain good performance at high compression ratios. To address this, we propose SLaB, a novel framework that decomposes each linear layer weight into three complementary components: a sparse matrix, a low-rank matrix, and a binary matrix. SLaB eliminates the need for retraining and leverages activation-aware pruning scores to guide the decomposition process. Experiments on Llama-family models demonstrate that SLaB achieves state-of-the-art performance, reducing perplexity by up to 36% compared to existing methods at 50% compression and improving accuracy by up to 8.98% over the baseline on zero-shot tasks.
SASQ: Static Activation Scaling for Quantization-Aware Training in Large Language Models
Dec 16, 2025Large language models (LLMs) excel at natural language tasks but face deployment challenges due to their growing size outpacing GPU memory advancements. Model quantization mitigates this issue by lowering weight and activation precision, but existing solutions face fundamental trade-offs: dynamic quantization incurs high computational overhead and poses deployment challenges on edge devices, while static quantization sacrifices accuracy. Existing approaches of quantization-aware training (QAT) further suffer from weight training costs. We propose SASQ: a lightweight QAT framework specifically tailored for activation quantization factors. SASQ exclusively optimizes only the quantization factors (without changing pre-trained weights), enabling static inference with high accuracy while maintaining deployment efficiency. SASQ adaptively truncates some outliers, thereby reducing the difficulty of quantization while preserving the distributional characteristics of the activations. SASQ not only surpasses existing SOTA quantization schemes but also outperforms the corresponding FP16 models. On LLaMA2-7B, it achieves 5.2% lower perplexity than QuaRot and 4.7% lower perplexity than the FP16 model on WikiText2.
SBS: Enhancing Parameter-Efficiency of Neural Representations for Neural Networks via Spectral Bias Suppression
Sep 09, 2025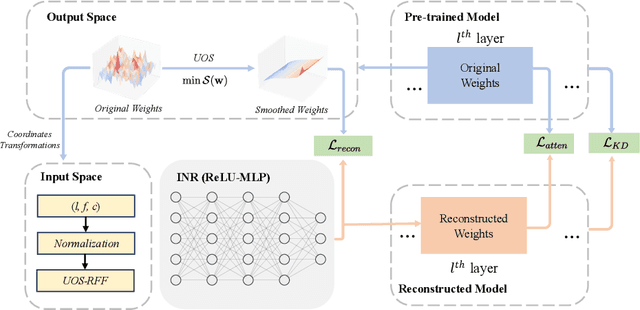
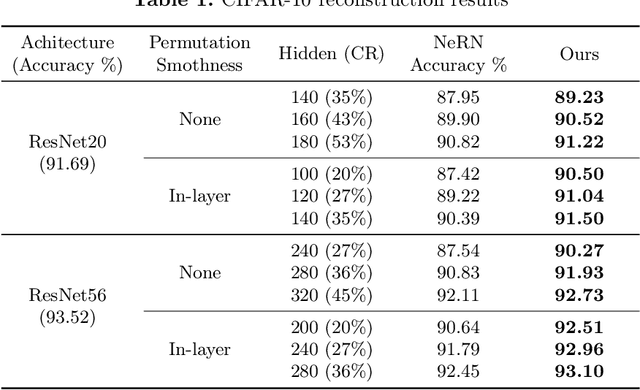
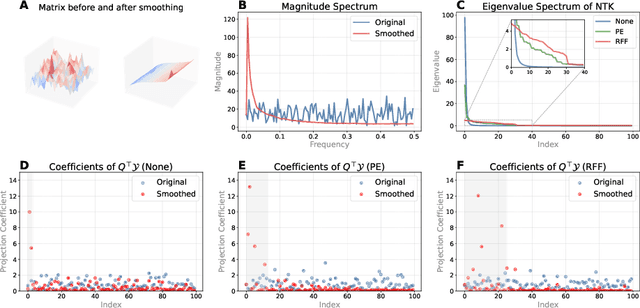
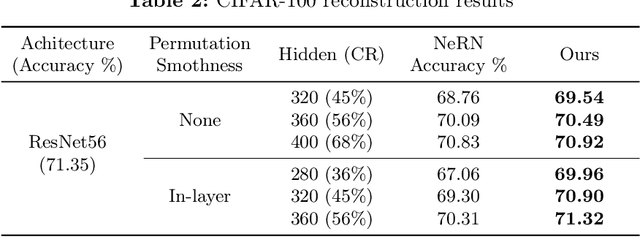
Implicit neural representations have recently been extended to represent convolutional neural network weights via neural representation for neural networks, offering promising parameter compression benefits. However, standard multi-layer perceptrons used in neural representation for neural networks exhibit a pronounced spectral bias, hampering their ability to reconstruct high-frequency details effectively. In this paper, we propose SBS, a parameter-efficient enhancement to neural representation for neural networks that suppresses spectral bias using two techniques: (1) a unidirectional ordering-based smoothing that improves kernel smoothness in the output space, and (2) unidirectional ordering-based smoothing aware random fourier features that adaptively modulate the frequency bandwidth of input encodings based on layer-wise parameter count. Extensive evaluations on various ResNet models with datasets CIFAR-10, CIFAR-100, and ImageNet, demonstrate that SBS achieves significantly better reconstruction accuracy with less parameters compared to SOTA.
Graph Attention-Based Symmetry Constraint Extraction for Analog Circuits
Dec 22, 2023



In recent years, analog circuits have received extensive attention and are widely used in many emerging applications. The high demand for analog circuits necessitates shorter circuit design cycles. To achieve the desired performance and specifications, various geometrical symmetry constraints must be carefully considered during the analog layout process. However, the manual labeling of these constraints by experienced analog engineers is a laborious and time-consuming process. To handle the costly runtime issue, we propose a graph-based learning framework to automatically extract symmetric constraints in analog circuit layout. The proposed framework leverages the connection characteristics of circuits and the devices'information to learn the general rules of symmetric constraints, which effectively facilitates the extraction of device-level constraints on circuit netlists. The experimental results demonstrate that compared to state-of-the-art symmetric constraint detection approaches, our framework achieves higher accuracy and lower false positive rate.
AiDAC: A Low-Cost In-Memory Computing Architecture with All-Analog Multi-Bit Compute and Interconnect
Dec 21, 2023



Analog in-memory computing (AiMC) is an emerging technology that shows fantastic performance superiority for neural network acceleration. However, as the computational bit-width and scale increase, high-precision data conversion and long-distance data routing will result in unacceptable energy and latency overheads in the AiMC system. In this work, we focus on the potential of in-charge computing and in-time interconnection and show an innovative AiMC architecture, named AiDAC, with three key contributions: (1) AiDAC enhances multibit computing efficiency and reduces data conversion times by grouping capacitors technology; (2) AiDAC first adopts row drivers and column time accumulators to achieve large-scale AiMC arrays integration while minimizing the energy cost of data movements. (3) AiDAC is the first work to support large-scale all-analog multibit vector-matrix multiplication (VMM) operations. The evaluation shows that AiDAC maintains high-precision calculation (less than 0.79% total computing error) while also possessing excellent performance features, such as high parallelism (up to 26.2TOPS), low latency (<20ns/VMM), and high energy efficiency (123.8TOPS/W), for 8bits VMM with 1024 input channels.
NicePIM: Design Space Exploration for Processing-In-Memory DNN Accelerators with 3D-Stacked-DRAM
May 30, 2023



With the widespread use of deep neural networks(DNNs) in intelligent systems, DNN accelerators with high performance and energy efficiency are greatly demanded. As one of the feasible processing-in-memory(PIM) architectures, 3D-stacked-DRAM-based PIM(DRAM-PIM) architecture enables large-capacity memory and low-cost memory access, which is a promising solution for DNN accelerators with better performance and energy efficiency. However, the low-cost characteristics of stacked DRAM and the distributed manner of memory access and data storing require us to rebalance the hardware design and DNN mapping. In this paper, we propose NicePIM to efficiently explore the design space of hardware architecture and DNN mapping of DRAM-PIM accelerators, which consists of three key components: PIM-Tuner, PIM-Mapper and Data-Scheduler. PIM-Tuner optimizes the hardware configurations leveraging a DNN model for classifying area-compliant architectures and a deep kernel learning model for identifying better hardware parameters. PIM-Mapper explores a variety of DNN mapping configurations, including parallelism between branches of DNN, DNN layer partitioning, DRAM capacity allocation and data layout pattern in DRAM to generate high-hardware-utilization DNN mapping schemes for various hardware configurations. The Data-Scheduler employs an integer-linear-programming-based data scheduling algorithm to alleviate the inter-PIM-node communication overhead of data-sharing brought by DNN layer partitioning. Experimental results demonstrate that NicePIM can optimize hardware configurations for DRAM-PIM systems effectively and can generate high-quality DNN mapping schemes with latency and energy cost reduced by 37% and 28% on average respectively compared to the baseline method.