 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudioDER: A Deduplication-Enhanced Reasoning Dataset for Post-Training Large Audio-Language Models
Jun 12, 2026Large Audio-Language Models (LALMs) have shown strong performance on a wide range of audio understanding tasks, yet they still struggle with complex audio reasoning. A practical way to improve such capabilities is post-training, whose effectiveness critically depends on the quality and diversity of training data. However, existing audio-language datasets often contain substantial redundancy, where many samples are highly similar in acoustic content and thus provide overlapping supervisory signals. Such redundancy not only increases annotation cost, but also limits corpus diversity and reduces the effectiveness of post-training. To address this issue, we propose a redundancy-aware data construction pipeline for building reasoning-oriented supervision for LALMs. Specifically, we first perform acoustic similarity-based deduplication across raw audio datasets to improve corpus diversity. We then integrate existing audio captions and question-answer pairs into a unified multiple-choice format. Based on these unified annotations, we leverage Qwen3-30B to generate chain-of-thought (CoT) rationales for reasoning-oriented supervision. Based on this pipeline, we construct AudioDER, a reasoning-oriented post-training dataset containing approximately 191k samples spanning sound, speech, and music. Each sample consists of an audio clip, a multiple-choice question, four answer candidates, an audio caption, and a CoT rationale. Extensive experiments show that post-training on AudioDER consistently improves the performance of Qwen2-Audio-7B-Instruct on multiple audio reasoning benchmarks, including MMAU-mini, MMSU, and MMAR. We hope AudioDER can serve as a valuable resource for advancing audio reasoning research and the development of more capable LALMs.
MAny: Merge Anything for Multimodal Continual Instruction Tuning
Apr 15, 2026Multimodal Continual Instruction Tuning (MCIT) is essential for sequential task adaptation of Multimodal Large Language Models (MLLMs) but is severely restricted by catastrophic forgetting. While existing literature focuses on the reasoning language backbone, in this work, we expose a critical yet neglected dual-forgetting phenomenon across both perception drift in Cross-modal Projection Space and reasoning collapse in Low-rank Parameter Space. To resolve this, we present \textbf{MAny} (\textbf{M}erge \textbf{Any}thing), a framework that merges task-specific knowledge through \textbf{C}ross-modal \textbf{P}rojection \textbf{M}erging (\textbf{CPM}) and \textbf{L}ow-rank \textbf{P}arameter \textbf{M}erging (\textbf{LPM}). Specifically, CPM recovers perceptual alignment by adaptively merging cross-modal visual representations via visual-prototype guidance, ensuring accurate feature recovery during inference. Simultaneously, LPM eliminates mutual interference among task-specific low-rank modules by recursively merging low-rank weight matrices. By leveraging recursive least squares, LPM provides a closed-form solution that mathematically guarantees an optimal fusion trajectory for reasoning stability. Notably, MAny operates as a training-free paradigm that achieves knowledge merging via efficient CPU-based algebraic operations, eliminating additional gradient-based optimization beyond initial tuning. Our extensive evaluations confirm the superior performance and robustness of MAny across multiple MLLMs and benchmarks. Specifically, on the UCIT benchmark, MAny achieves significant leads of up to 8.57\% and 2.85\% in final average accuracy over state-of-the-art methods across two different MLLMs, respectively.
Detect and Act: Automated Dynamic Optimizer through Meta-Black-Box Optimization
Jan 30, 2026Dynamic Optimization Problems (DOPs) are challenging to address due to their complex nature, i.e., dynamic environment variation. Evolutionary Computation methods are generally advantaged in solving DOPs since they resemble dynamic biological evolution. However, existing evolutionary dynamic optimization methods rely heavily on human-crafted adaptive strategy to detect environment variation in DOPs, and then adapt the searching strategy accordingly. These hand-crafted strategies may perform ineffectively at out-of-box scenarios. In this paper, we propose a reinforcement learning-assisted approach to enable automated variation detection and self-adaption in evolutionary algorithms. This is achieved by borrowing the bi-level learning-to-optimize idea from recent Meta-Black-Box Optimization works. We use a deep Q-network as optimization dynamics detector and searching strategy adapter: It is fed as input with current-step optimization state and then dictates desired control parameters to underlying evolutionary algorithms for next-step optimization. The learning objective is to maximize the expected performance gain across a problem distribution. Once trained, our approach could generalize toward unseen DOPs with automated environment variation detection and self-adaption. To facilitate comprehensive validation, we further construct an easy-to-difficult DOPs testbed with diverse synthetic instances. Extensive benchmark results demonstrate flexible searching behavior and superior performance of our approach in solving DOPs, compared to state-of-the-art baselines.
NTIRE 2025 Image Shadow Removal Challenge Report
Jun 18, 2025



This work examines the findings of the NTIRE 2025 Shadow Removal Challenge. A total of 306 participants have registered, with 17 teams successfully submitting their solutions during the final evaluation phase. Following the last two editions, this challenge had two evaluation tracks: one focusing on reconstruction fidelity and the other on visual perception through a user study. Both tracks were evaluated with images from the WSRD+ dataset, simulating interactions between self- and cast-shadows with a large number of diverse objects, textures, and materials.
NTIRE 2025 Challenge on HR Depth from Images of Specular and Transparent Surfaces
Jun 06, 2025This paper reports on the NTIRE 2025 challenge on HR Depth From images of Specular and Transparent surfaces, held in conjunction with the New Trends in Image Restoration and Enhancement (NTIRE) workshop at CVPR 2025. This challenge aims to advance the research on depth estimation, specifically to address two of the main open issues in the field: high-resolution and non-Lambertian surfaces. The challenge proposes two tracks on stereo and single-image depth estimation, attracting about 177 registered participants. In the final testing stage, 4 and 4 participating teams submitted their models and fact sheets for the two tracks.
NTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.
NTIRE 2025 Challenge on Event-Based Image Deblurring: Methods and Results
Apr 16, 2025This paper presents an overview of NTIRE 2025 the First Challenge on Event-Based Image Deblurring, detailing the proposed methodologies and corresponding results. The primary goal of the challenge is to design an event-based method that achieves high-quality image deblurring, with performance quantitatively assessed using Peak Signal-to-Noise Ratio (PSNR). Notably, there are no restrictions on computational complexity or model size. The task focuses on leveraging both events and images as inputs for single-image deblurring. A total of 199 participants registered, among whom 15 teams successfully submitted valid results, offering valuable insights into the current state of event-based image deblurring. We anticipate that this challenge will drive further advancements in event-based vision research.
AudioCIL: A Python Toolbox for Audio Class-Incremental Learning with Multiple Scenes
Dec 16, 2024Deep learning, with its robust aotomatic feature extraction capabilities, has demonstrated significant success in audio signal processing. Typically, these methods rely on static, pre-collected large-scale datasets for training, performing well on a fixed number of classes. However, the real world is characterized by constant change, with new audio classes emerging from streaming or temporary availability due to privacy. This dynamic nature of audio environments necessitates models that can incrementally learn new knowledge for new classes without discarding existing information. Introducing incremental learning to the field of audio signal processing, i.e., Audio Class-Incremental Learning (AuCIL), is a meaningful endeavor. We propose such a toolbox named AudioCIL to align audio signal processing algorithms with real-world scenarios and strengthen research in audio class-incremental learning.
Exploring structure diversity in atomic resolution microscopy with graph neural networks
Oct 23, 2024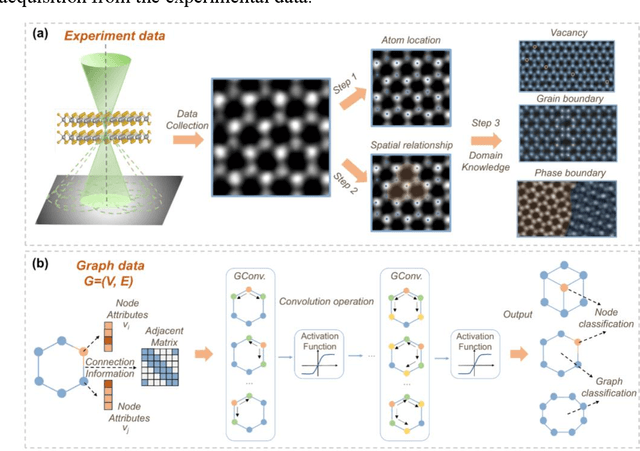
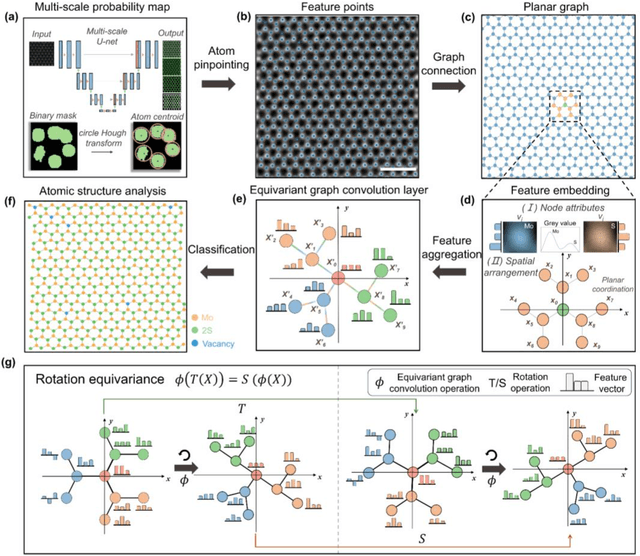
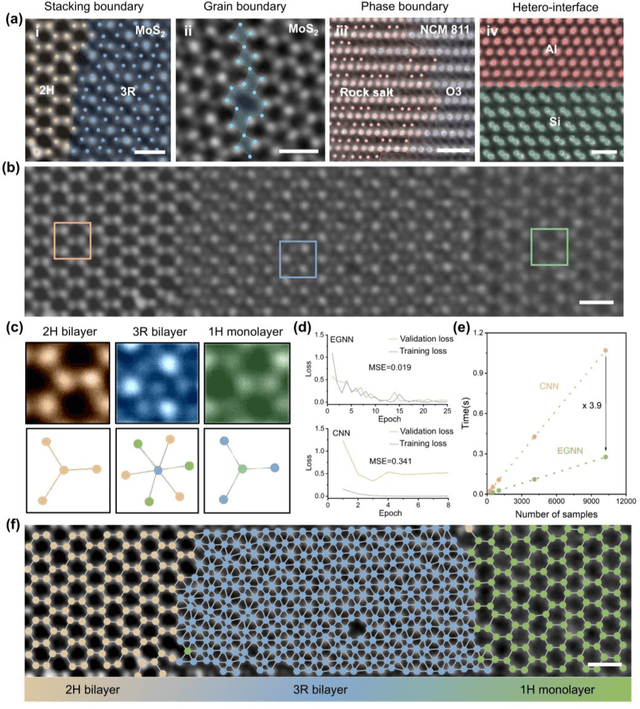
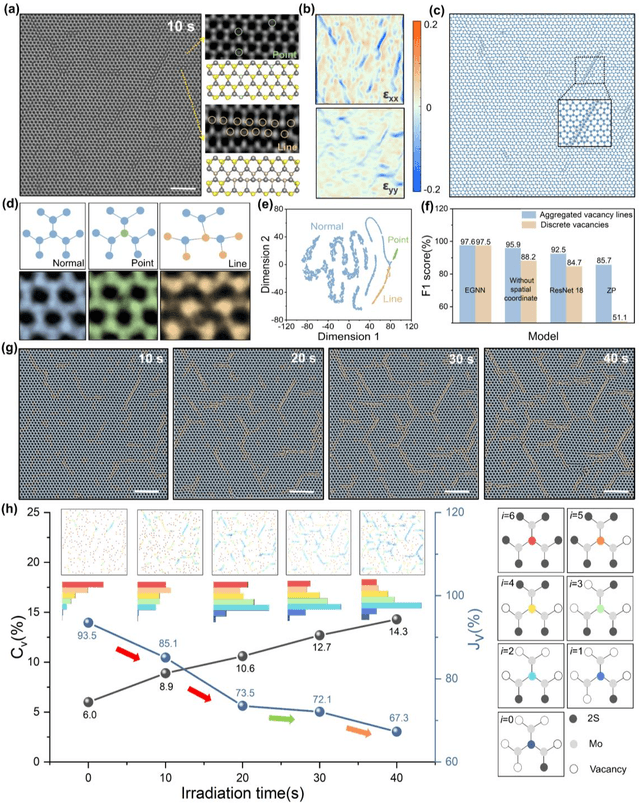
The emergence of deep learning (DL) has provided great opportunities for the high-throughput analysis of atomic-resolution micrographs. However, the DL models trained by image patches in fixed size generally lack efficiency and flexibility when processing micrographs containing diversified atomic configurations. Herein, inspired by the similarity between the atomic structures and graphs, we describe a few-shot learning framework based on an equivariant graph neural network (EGNN) to analyze a library of atomic structures (e.g., vacancies, phases, grain boundaries, doping, etc.), showing significantly promoted robustness and three orders of magnitude reduced computing parameters compared to the image-driven DL models, which is especially evident for those aggregated vacancy lines with flexible lattice distortion. Besides, the intuitiveness of graphs enables quantitative and straightforward extraction of the atomic-scale structural features in batches, thus statistically unveiling the self-assembly dynamics of vacancy lines under electron beam irradiation. A versatile model toolkit is established by integrating EGNN sub-models for single structure recognition to process images involving varied configurations in the form of a task chain, leading to the discovery of novel doping configurations with superior electrocatalytic properties for hydrogen evolution reactions. This work provides a powerful tool to explore structure diversity in a fast, accurate, and intelligent manner.
Hardware Architecture Design of Model-Based Image Reconstruction Towards Palm-size Photoacoustic Tomography
Aug 12, 2024



Photoacoustic (PA) imaging technology combines the advantages of optical imaging and ultrasound imaging, showing great potential in biomedical applications. Many preclinical studies and clinical applications urgently require fast, high-quality, low-cost and portable imaging system. Translating advanced image reconstruction algorithms into hardware implementations is highly desired. However, existing iterative PA image reconstructions, although exhibit higher accuracy than delay-and-sum algorithm, suffer from high computational cost. In this paper, we introduce a model-based hardware acceleration architecture based on superposed Wave (s-Wave) for palm-size PA tomography (palm-PAT), aiming at enhancing both the speed and performance of image reconstruction at a much lower system cost. To achieve this, we propose an innovative data reuse method that significantly reduces hardware storage resource consumption. We conducted experiments by FPGA implementation of the algorithm, using both phantoms and in vivo human finger data to verify the feasibility of the proposed method. The results demonstrate that our proposed architecture can substantially reduce system cost while maintaining high imaging performance. The hardware-accelerated implementation of the model-based algorithm achieves a speedup of up to approximately 270 times compared to the CPU, while the corresponding energy efficiency ratio is improved by more than 2700 times.