 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimistic Model Rollouts for Pessimistic Offline Policy Optimization
Jan 11, 2024



Model-based offline reinforcement learning (RL) has made remarkable progress, offering a promising avenue for improving generalization with synthetic model rollouts. Existing works primarily focus on incorporating pessimism for policy optimization, usually via constructing a Pessimistic Markov Decision Process (P-MDP). However, the P-MDP discourages the policies from learning in out-of-distribution (OOD) regions beyond the support of offline datasets, which can under-utilize the generalization ability of dynamics models. In contrast, we propose constructing an Optimistic MDP (O-MDP). We initially observed the potential benefits of optimism brought by encouraging more OOD rollouts. Motivated by this observation, we present ORPO, a simple yet effective model-based offline RL framework. ORPO generates Optimistic model Rollouts for Pessimistic offline policy Optimization. Specifically, we train an optimistic rollout policy in the O-MDP to sample more OOD model rollouts. Then we relabel the sampled state-action pairs with penalized rewards and optimize the output policy in the P-MDP. Theoretically, we demonstrate that the performance of policies trained with ORPO can be lower-bounded in linear MDPs. Experimental results show that our framework significantly outperforms P-MDP baselines by a margin of 30%, achieving state-of-the-art performance on the widely-used benchmark. Moreover, ORPO exhibits notable advantages in problems that require generalization.
Real-time Short Video Recommendation on Mobile Devices
Aug 20, 2022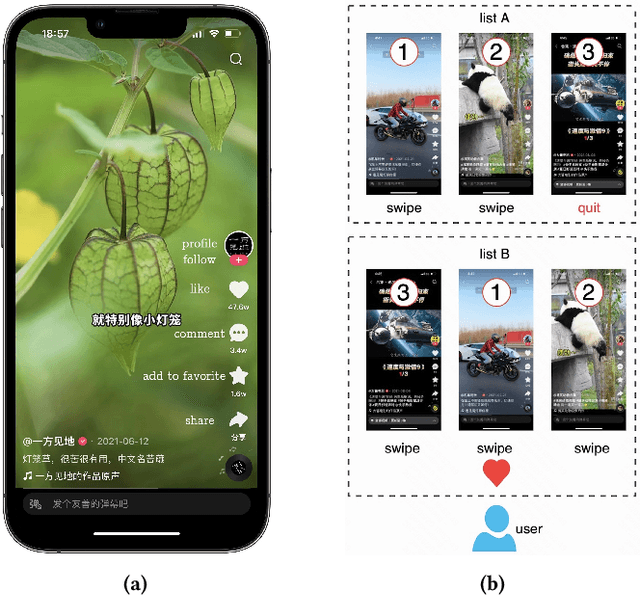
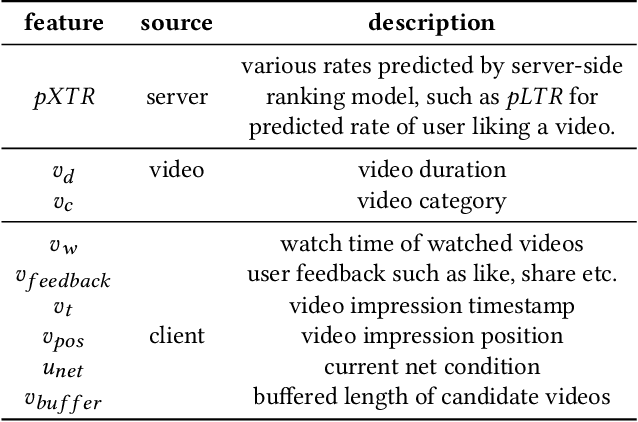
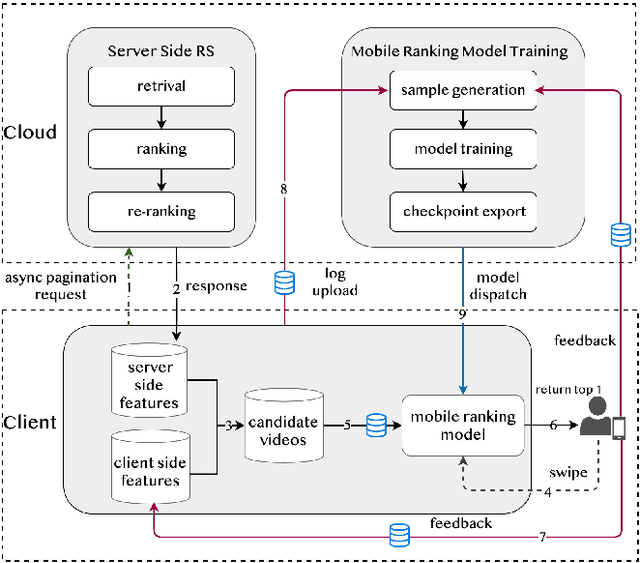
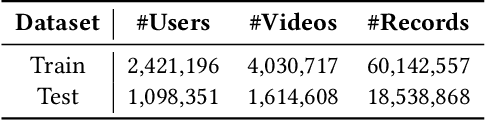
Short video applications have attracted billions of users in recent years, fulfilling their various needs with diverse content. Users usually watch short videos on many topics on mobile devices in a short period of time, and give explicit or implicit feedback very quickly to the short videos they watch. The recommender system needs to perceive users' preferences in real-time in order to satisfy their changing interests. Traditionally, recommender systems deployed at server side return a ranked list of videos for each request from client. Thus it cannot adjust the recommendation results according to the user's real-time feedback before the next request. Due to client-server transmitting latency, it is also unable to make immediate use of users' real-time feedback. However, as users continue to watch videos and feedback, the changing context leads the ranking of the server-side recommendation system inaccurate. In this paper, we propose to deploy a short video recommendation framework on mobile devices to solve these problems. Specifically, we design and deploy a tiny on-device ranking model to enable real-time re-ranking of server-side recommendation results. We improve its prediction accuracy by exploiting users' real-time feedback of watched videos and client-specific real-time features. With more accurate predictions, we further consider interactions among candidate videos, and propose a context-aware re-ranking method based on adaptive beam search. The framework has been deployed on Kuaishou, a billion-user scale short video application, and improved effective view, like and follow by 1.28\%, 8.22\% and 13.6\% respectively.