 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
Optimistic Model Rollouts for Pessimistic Offline Policy Optimization
Jan 11, 2024



Model-based offline reinforcement learning (RL) has made remarkable progress, offering a promising avenue for improving generalization with synthetic model rollouts. Existing works primarily focus on incorporating pessimism for policy optimization, usually via constructing a Pessimistic Markov Decision Process (P-MDP). However, the P-MDP discourages the policies from learning in out-of-distribution (OOD) regions beyond the support of offline datasets, which can under-utilize the generalization ability of dynamics models. In contrast, we propose constructing an Optimistic MDP (O-MDP). We initially observed the potential benefits of optimism brought by encouraging more OOD rollouts. Motivated by this observation, we present ORPO, a simple yet effective model-based offline RL framework. ORPO generates Optimistic model Rollouts for Pessimistic offline policy Optimization. Specifically, we train an optimistic rollout policy in the O-MDP to sample more OOD model rollouts. Then we relabel the sampled state-action pairs with penalized rewards and optimize the output policy in the P-MDP. Theoretically, we demonstrate that the performance of policies trained with ORPO can be lower-bounded in linear MDPs. Experimental results show that our framework significantly outperforms P-MDP baselines by a margin of 30%, achieving state-of-the-art performance on the widely-used benchmark. Moreover, ORPO exhibits notable advantages in problems that require generalization.
MVP: Meta Visual Prompt Tuning for Few-Shot Remote Sensing Image Scene Classification
Sep 17, 2023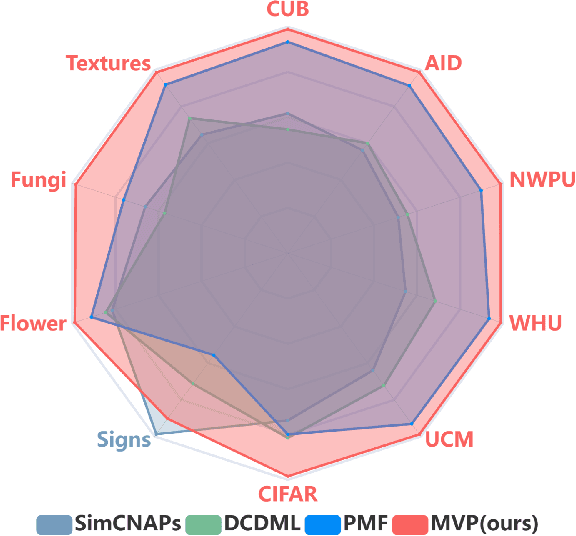
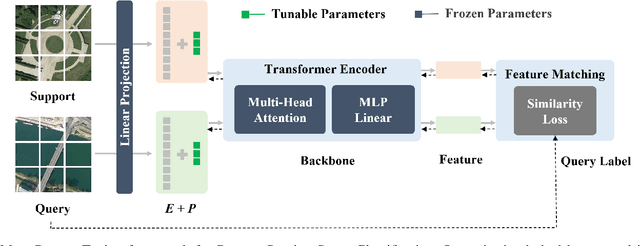
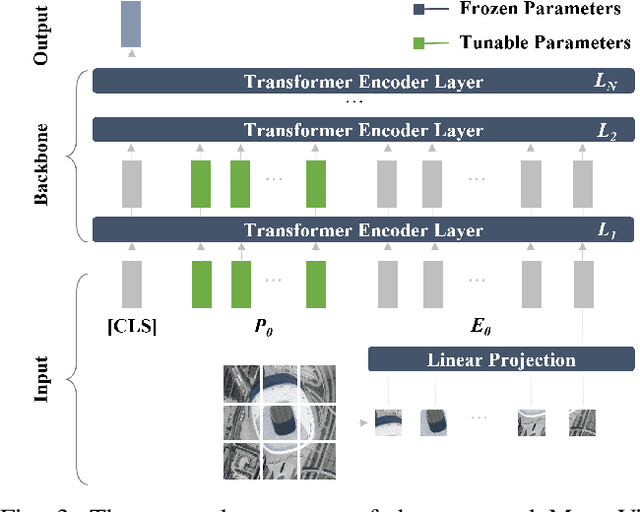
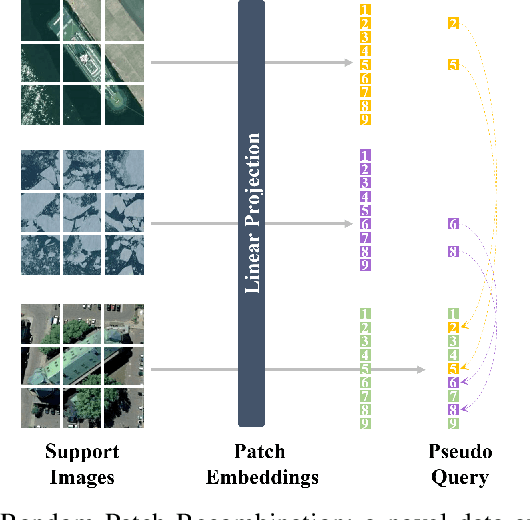
Vision Transformer (ViT) models have recently emerged as powerful and versatile models for various visual tasks. Recently, a work called PMF has achieved promising results in few-shot image classification by utilizing pre-trained vision transformer models. However, PMF employs full fine-tuning for learning the downstream tasks, leading to significant overfitting and storage issues, especially in the remote sensing domain. In order to tackle these issues, we turn to the recently proposed parameter-efficient tuning methods, such as VPT, which updates only the newly added prompt parameters while keeping the pre-trained backbone frozen. Inspired by VPT, we propose the Meta Visual Prompt Tuning (MVP) method. Specifically, we integrate the VPT method into the meta-learning framework and tailor it to the remote sensing domain, resulting in an efficient framework for Few-Shot Remote Sensing Scene Classification (FS-RSSC). Furthermore, we introduce a novel data augmentation strategy based on patch embedding recombination to enhance the representation and diversity of scenes for classification purposes. Experiment results on the FS-RSSC benchmark demonstrate the superior performance of the proposed MVP over existing methods in various settings, such as various-way-various-shot, various-way-one-shot, and cross-domain adaptation.
Nuclear Norm Maximization Based Curiosity-Driven Learning
May 28, 2022
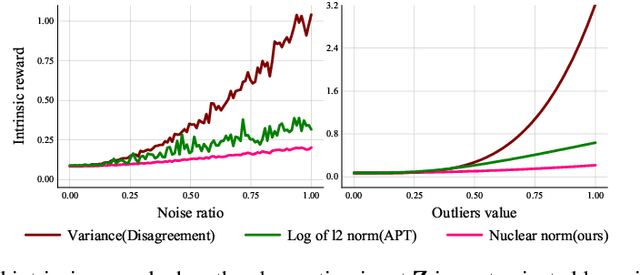
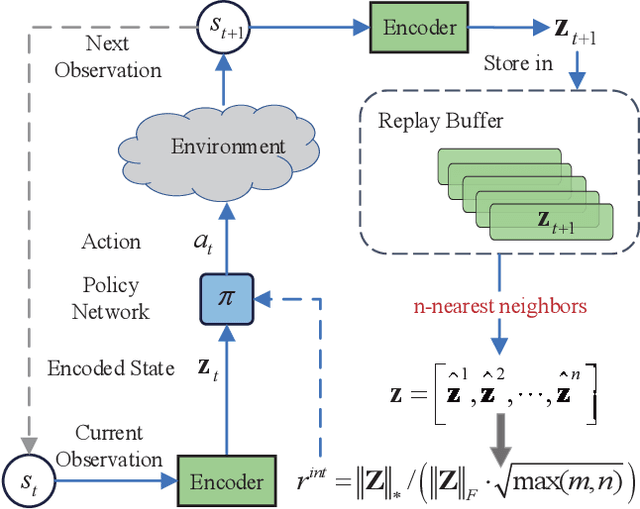
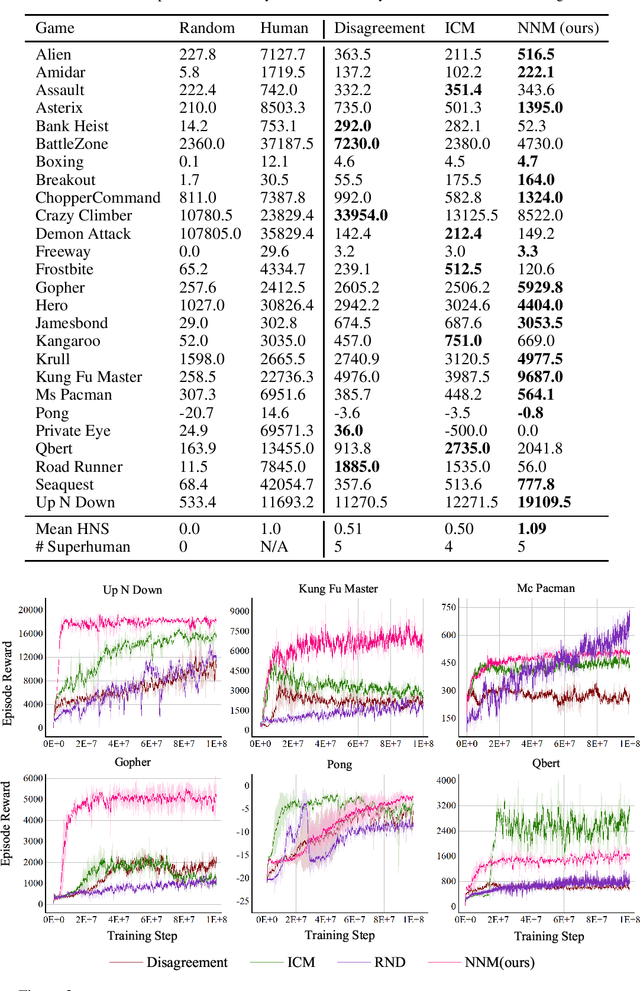
To handle the sparsity of the extrinsic rewards in reinforcement learning, researchers have proposed intrinsic reward which enables the agent to learn the skills that might come in handy for pursuing the rewards in the future, such as encouraging the agent to visit novel states. However, the intrinsic reward can be noisy due to the undesirable environment's stochasticity and directly applying the noisy value predictions to supervise the policy is detrimental to improve the learning performance and efficiency. Moreover, many previous studies employ $\ell^2$ norm or variance to measure the exploration novelty, which will amplify the noise due to the square operation. In this paper, we address aforementioned challenges by proposing a novel curiosity leveraging the nuclear norm maximization (NNM), which can quantify the novelty of exploring the environment more accurately while providing high-tolerance to the noise and outliers. We conduct extensive experiments across a variety of benchmark environments and the results suggest that NNM can provide state-of-the-art performance compared with previous curiosity methods. On 26 Atari games subset, when trained with only intrinsic reward, NNM achieves a human-normalized score of 1.09, which doubles that of competitive intrinsic rewards-based approaches. Our code will be released publicly to enhance the reproducibility.
A Fixed Version of Quadratic Program in Gradient Episodic Memory
Jul 07, 2021Gradient Episodic Memory is indeed a novel method for continual learning, which solves new problems quickly without forgetting previously acquired knowledge. However, in the process of studying the paper, we found there were some problems in the proof of the dual problem of Quadratic Program, so here we give our fixed version for this problem.
KnowSR: Knowledge Sharing among Homogeneous Agents in Multi-agent Reinforcement Learning
May 25, 2021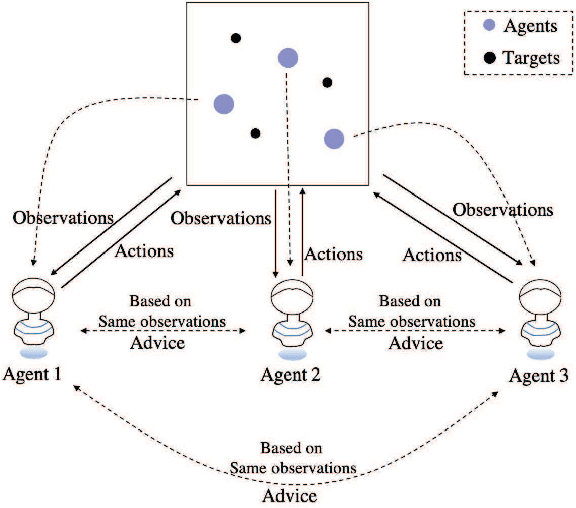
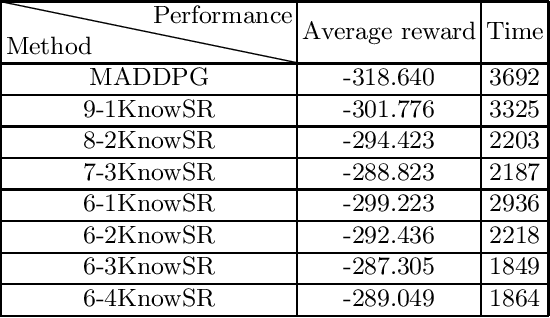
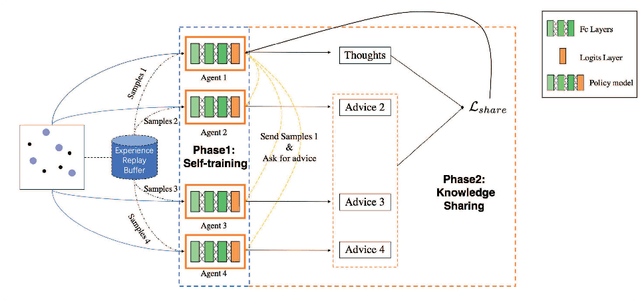

Recently, deep reinforcement learning (RL) algorithms have made great progress in multi-agent domain. However, due to characteristics of RL, training for complex tasks would be resource-intensive and time-consuming. To meet this challenge, mutual learning strategy between homogeneous agents is essential, which is under-explored in previous studies, because most existing methods do not consider to use the knowledge of agent models. In this paper, we present an adaptation method of the majority of multi-agent reinforcement learning (MARL) algorithms called KnowSR which takes advantage of the differences in learning between agents. We employ the idea of knowledge distillation (KD) to share knowledge among agents to shorten the training phase. To empirically demonstrate the robustness and effectiveness of KnowSR, we performed extensive experiments on state-of-the-art MARL algorithms in collaborative and competitive scenarios. The results demonstrate that KnowSR outperforms recently reported methodologies, emphasizing the importance of the proposed knowledge sharing for MARL.
KnowRU: Knowledge Reusing via Knowledge Distillation in Multi-agent Reinforcement Learning
Mar 27, 2021
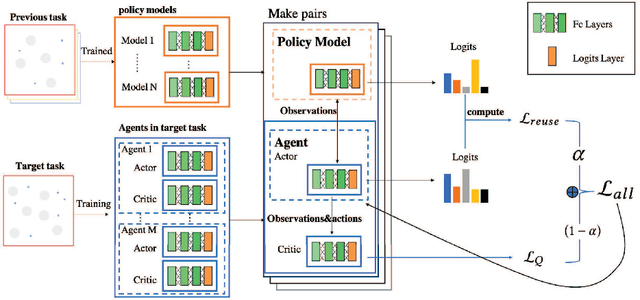


Recently, deep Reinforcement Learning (RL) algorithms have achieved dramatically progress in the multi-agent area. However, training the increasingly complex tasks would be time-consuming and resources-exhausting. To alleviate this problem, efficient leveraging the historical experience is essential, which is under-explored in previous studies as most of the exiting methods may fail to achieve this goal in a continuously variational system due to their complicated design and environmental dynamics. In this paper, we propose a method, named "KnowRU" for knowledge reusing which can be easily deployed in the majority of the multi-agent reinforcement learning algorithms without complicated hand-coded design. We employ the knowledge distillation paradigm to transfer the knowledge among agents with the goal to accelerate the training phase for new tasks, while improving the asymptotic performance of agents. To empirically demonstrate the robustness and effectiveness of KnowRU, we perform extensive experiments on state-of-the-art multi-agent reinforcement learning (MARL) algorithms on collaborative and competitive scenarios. The results show that KnowRU can outperform the recently reported methods, which emphasizes the importance of the proposed knowledge reusing for MARL.
FedH2L: Federated Learning with Model and Statistical Heterogeneity
Jan 27, 2021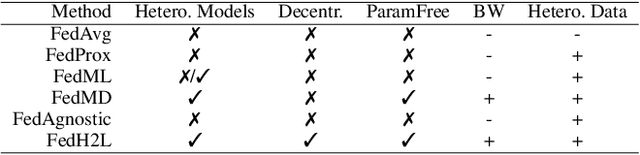
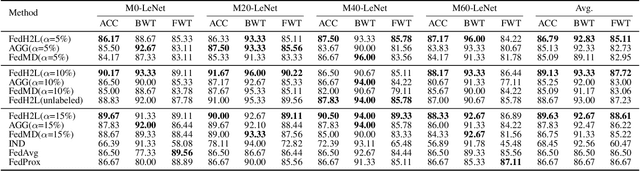
Federated learning (FL) enables distributed participants to collectively learn a strong global model without sacrificing their individual data privacy. Mainstream FL approaches require each participant to share a common network architecture and further assume that data are are sampled IID across participants. However, in real-world deployments participants may require heterogeneous network architectures; and the data distribution is almost certainly non-uniform across participants. To address these issues we introduce FedH2L, which is agnostic to both the model architecture and robust to different data distributions across participants. In contrast to approaches sharing parameters or gradients, FedH2L relies on mutual distillation, exchanging only posteriors on a shared seed set between participants in a decentralized manner. This makes it extremely bandwidth efficient, model agnostic, and crucially produces models capable of performing well on the whole data distribution when learning from heterogeneous silos.
Online Meta-Critic Learning for Off-Policy Actor-Critic Methods
Mar 11, 2020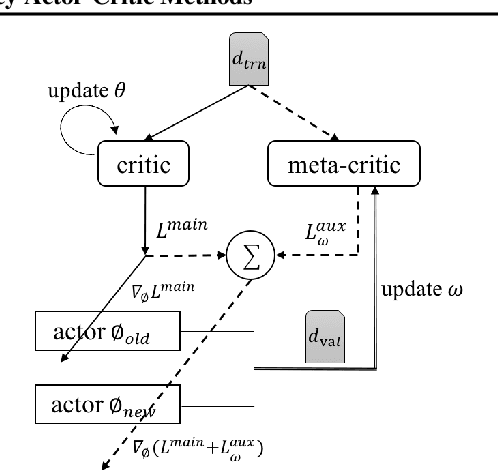
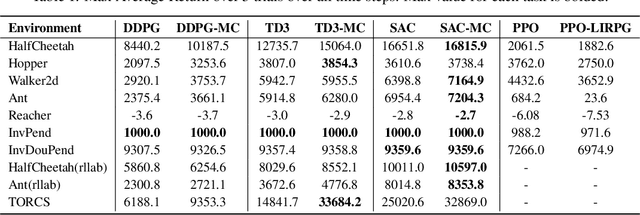
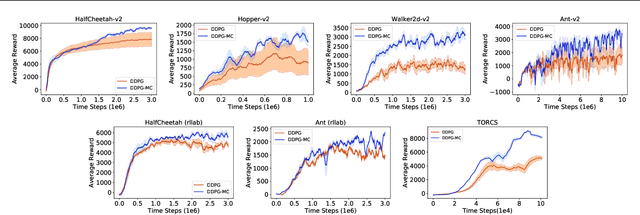

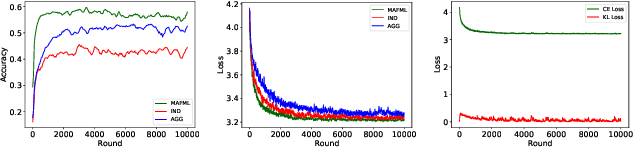
Off-Policy Actor-Critic (Off-PAC) methods have proven successful in a variety of continuous control tasks. Normally, the critic's action-value function is updated using temporal-difference, and the critic in turn provides a loss for the actor that trains it to take actions with higher expected return. In this paper, we introduce a novel and flexible meta-critic that observes the learning process and meta-learns an additional loss for the actor that accelerates and improves actor-critic learning. Compared to the vanilla critic, the meta-critic network is explicitly trained to accelerate the learning process; and compared to existing meta-learning algorithms, meta-critic is rapidly learned online for a single task, rather than slowly over a family of tasks. Crucially, our meta-critic framework is designed for off-policy based learners, which currently provide state-of-the-art reinforcement learning sample efficiency. We demonstrate that online meta-critic learning leads to improvements in avariety of continuous control environments when combined with contemporary Off-PAC methods DDPG, TD3 and the state-of-the-art SAC.