 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperLoad: A Cross-Modality Enhanced Large Language Model-Based Framework for Green Data Center Cooling Load Prediction
Dec 22, 2025The rapid growth of artificial intelligence is exponentially escalating computational demand, inflating data center energy use and carbon emissions, and spurring rapid deployment of green data centers to relieve resource and environmental stress. Achieving sub-minute orchestration of renewables, storage, and loads, while minimizing PUE and lifecycle carbon intensity, hinges on accurate load forecasting. However, existing methods struggle to address small-sample scenarios caused by cold start, load distortion, multi-source data fragmentation, and distribution shifts in green data centers. We introduce HyperLoad, a cross-modality framework that exploits pre-trained large language models (LLMs) to overcome data scarcity. In the Cross-Modality Knowledge Alignment phase, textual priors and time-series data are mapped to a common latent space, maximizing the utility of prior knowledge. In the Multi-Scale Feature Modeling phase, domain-aligned priors are injected through adaptive prefix-tuning, enabling rapid scenario adaptation, while an Enhanced Global Interaction Attention mechanism captures cross-device temporal dependencies. The public DCData dataset is released for benchmarking. Under both data sufficient and data scarce settings, HyperLoad consistently surpasses state-of-the-art (SOTA) baselines, demonstrating its practicality for sustainable green data center management.
Bridging VLM and KMP: Enabling Fine-grained robotic manipulation via Semantic Keypoints Representation
Mar 04, 2025
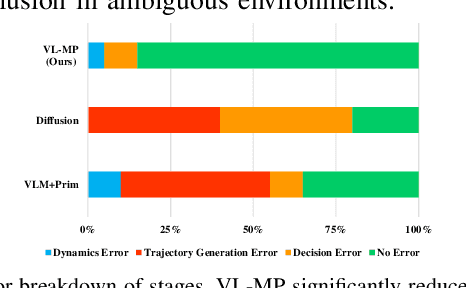
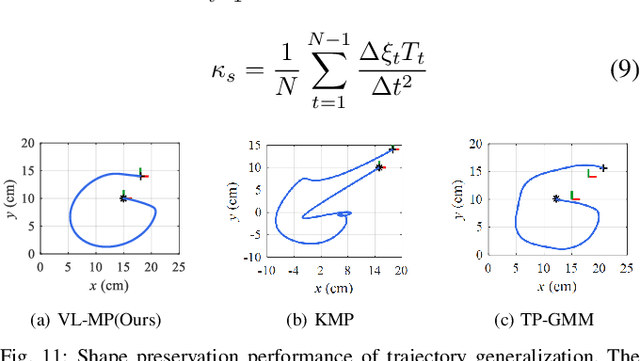
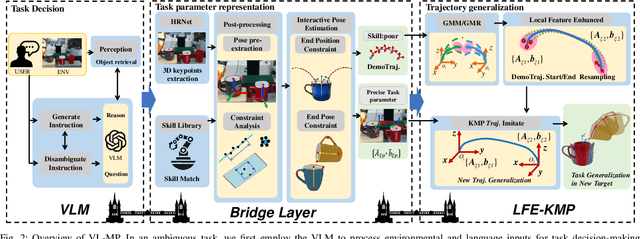
From early Movement Primitive (MP) techniques to modern Vision-Language Models (VLMs), autonomous manipulation has remained a pivotal topic in robotics. As two extremes, VLM-based methods emphasize zero-shot and adaptive manipulation but struggle with fine-grained planning. In contrast, MP-based approaches excel in precise trajectory generalization but lack decision-making ability. To leverage the strengths of the two frameworks, we propose VL-MP, which integrates VLM with Kernelized Movement Primitives (KMP) via a low-distortion decision information transfer bridge, enabling fine-grained robotic manipulation under ambiguous situations. One key of VL-MP is the accurate representation of task decision parameters through semantic keypoints constraints, leading to more precise task parameter generation. Additionally, we introduce a local trajectory feature-enhanced KMP to support VL-MP, thereby achieving shape preservation for complex trajectories. Extensive experiments conducted in complex real-world environments validate the effectiveness of VL-MP for adaptive and fine-grained manipulation.
Graph-Based Cross-Domain Knowledge Distillation for Cross-Dataset Text-to-Image Person Retrieval
Jan 25, 2025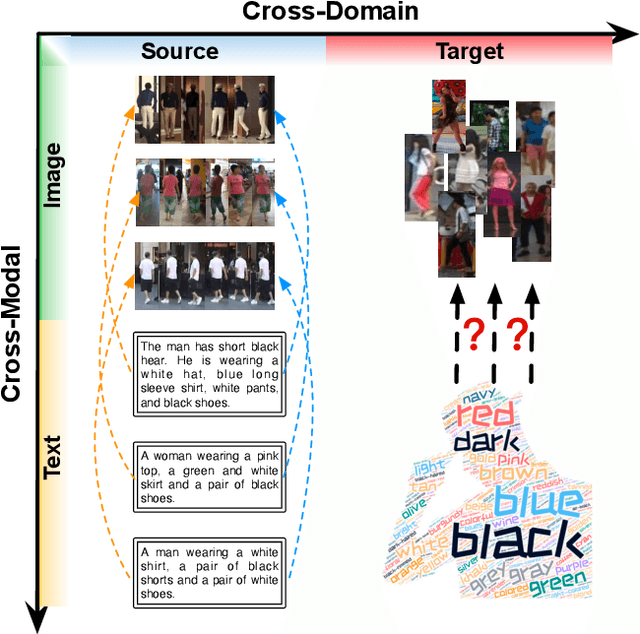
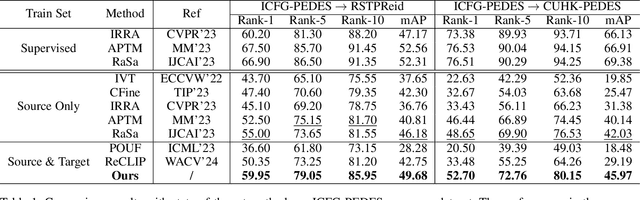
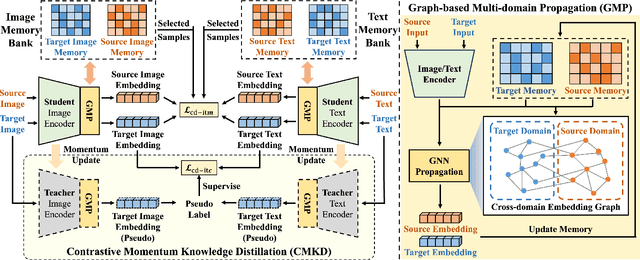
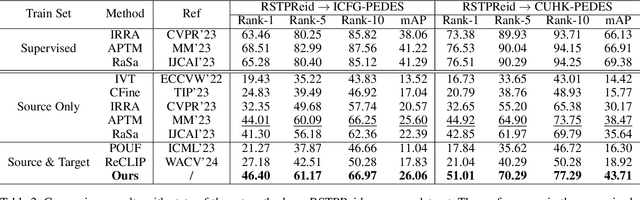
Video surveillance systems are crucial components for ensuring public safety and management in smart city. As a fundamental task in video surveillance, text-to-image person retrieval aims to retrieve the target person from an image gallery that best matches the given text description. Most existing text-to-image person retrieval methods are trained in a supervised manner that requires sufficient labeled data in the target domain. However, it is common in practice that only unlabeled data is available in the target domain due to the difficulty and cost of data annotation, which limits the generalization of existing methods in practical application scenarios. To address this issue, we propose a novel unsupervised domain adaptation method, termed Graph-Based Cross-Domain Knowledge Distillation (GCKD), to learn the cross-modal feature representation for text-to-image person retrieval in a cross-dataset scenario. The proposed GCKD method consists of two main components. Firstly, a graph-based multi-modal propagation module is designed to bridge the cross-domain correlation among the visual and textual samples. Secondly, a contrastive momentum knowledge distillation module is proposed to learn the cross-modal feature representation using the online knowledge distillation strategy. By jointly optimizing the two modules, the proposed method is able to achieve efficient performance for cross-dataset text-to-image person retrieval. acExtensive experiments on three publicly available text-to-image person retrieval datasets demonstrate the effectiveness of the proposed GCKD method, which consistently outperforms the state-of-the-art baselines.
Hypergraph-Guided Disentangled Spectrum Transformer Networks for Near-Infrared Facial Expression Recognition
Dec 10, 2023



With the strong robusticity on illumination variations, near-infrared (NIR) can be an effective and essential complement to visible (VIS) facial expression recognition in low lighting or complete darkness conditions. However, facial expression recognition (FER) from NIR images presents more challenging problem than traditional FER due to the limitations imposed by the data scale and the difficulty of extracting discriminative features from incomplete visible lighting contents. In this paper, we give the first attempt to deep NIR facial expression recognition and proposed a novel method called near-infrared facial expression transformer (NFER-Former). Specifically, to make full use of the abundant label information in the field of VIS, we introduce a Self-Attention Orthogonal Decomposition mechanism that disentangles the expression information and spectrum information from the input image, so that the expression features can be extracted without the interference of spectrum variation. We also propose a Hypergraph-Guided Feature Embedding method that models some key facial behaviors and learns the structure of the complex correlations between them, thereby alleviating the interference of inter-class similarity. Additionally, we have constructed a large NIR-VIS Facial Expression dataset that includes 360 subjects to better validate the efficiency of NFER-Former. Extensive experiments and ablation studies show that NFER-Former significantly improves the performance of NIR FER and achieves state-of-the-art results on the only two available NIR FER datasets, Oulu-CASIA and Large-HFE.
Multi-Energy Guided Image Translation with Stochastic Differential Equations for Near-Infrared Facial Expression Recognition
Dec 10, 2023
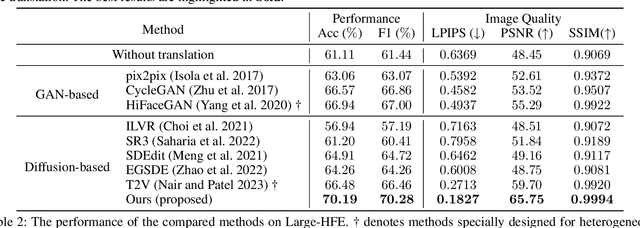

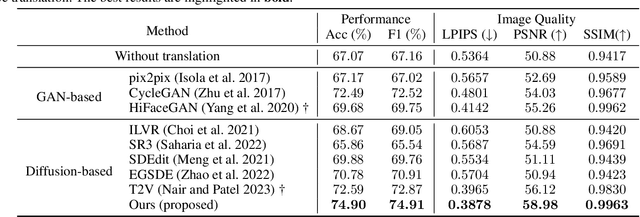
Illumination variation has been a long-term challenge in real-world facial expression recognition(FER). Under uncontrolled or non-visible light conditions, Near-infrared (NIR) can provide a simple and alternative solution to obtain high-quality images and supplement the geometric and texture details that are missing in the visible domain. Due to the lack of existing large-scale NIR facial expression datasets, directly extending VIS FER methods to the NIR spectrum may be ineffective. Additionally, previous heterogeneous image synthesis methods are restricted by low controllability without prior task knowledge. To tackle these issues, we present the first approach, called for NIR-FER Stochastic Differential Equations (NFER-SDE), that transforms face expression appearance between heterogeneous modalities to the overfitting problem on small-scale NIR data. NFER-SDE is able to take the whole VIS source image as input and, together with domain-specific knowledge, guide the preservation of modality-invariant information in the high-frequency content of the image. Extensive experiments and ablation studies show that NFER-SDE significantly improves the performance of NIR FER and achieves state-of-the-art results on the only two available NIR FER datasets, Oulu-CASIA and Large-HFE.
MVP: Meta Visual Prompt Tuning for Few-Shot Remote Sensing Image Scene Classification
Sep 17, 2023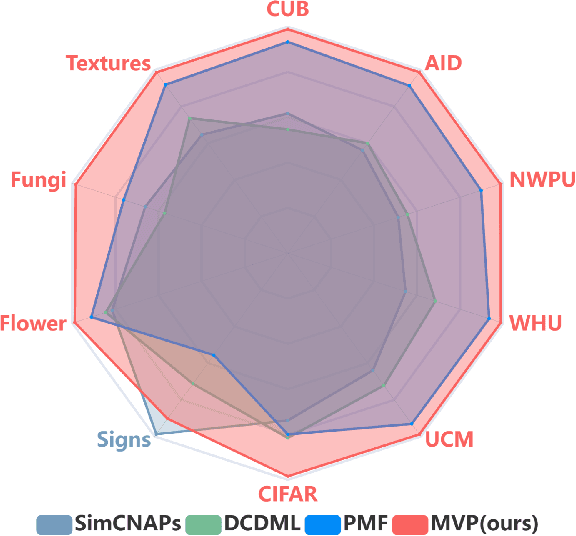
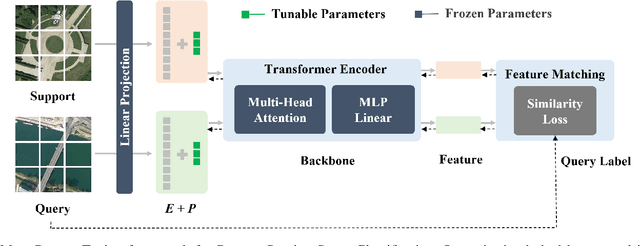
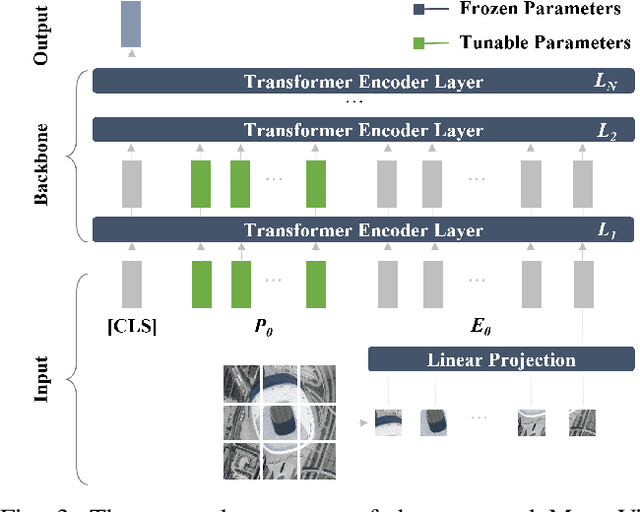
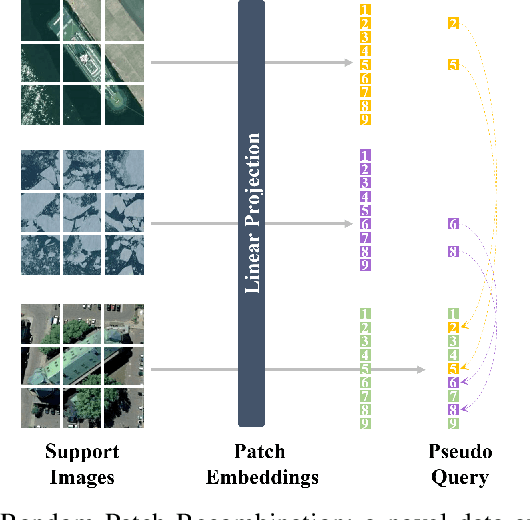
Vision Transformer (ViT) models have recently emerged as powerful and versatile models for various visual tasks. Recently, a work called PMF has achieved promising results in few-shot image classification by utilizing pre-trained vision transformer models. However, PMF employs full fine-tuning for learning the downstream tasks, leading to significant overfitting and storage issues, especially in the remote sensing domain. In order to tackle these issues, we turn to the recently proposed parameter-efficient tuning methods, such as VPT, which updates only the newly added prompt parameters while keeping the pre-trained backbone frozen. Inspired by VPT, we propose the Meta Visual Prompt Tuning (MVP) method. Specifically, we integrate the VPT method into the meta-learning framework and tailor it to the remote sensing domain, resulting in an efficient framework for Few-Shot Remote Sensing Scene Classification (FS-RSSC). Furthermore, we introduce a novel data augmentation strategy based on patch embedding recombination to enhance the representation and diversity of scenes for classification purposes. Experiment results on the FS-RSSC benchmark demonstrate the superior performance of the proposed MVP over existing methods in various settings, such as various-way-various-shot, various-way-one-shot, and cross-domain adaptation.
PVP: Pre-trained Visual Parameter-Efficient Tuning
Apr 26, 2023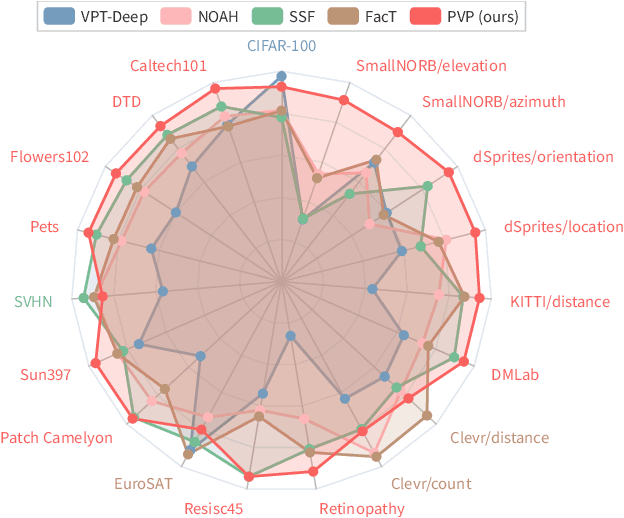
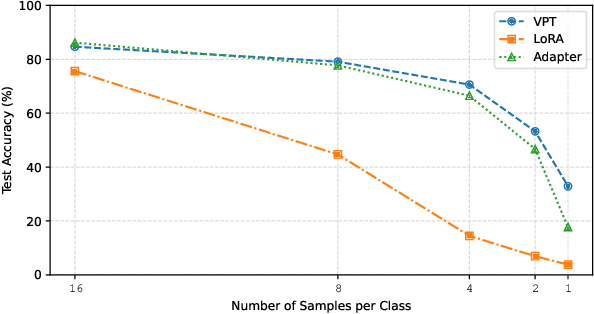
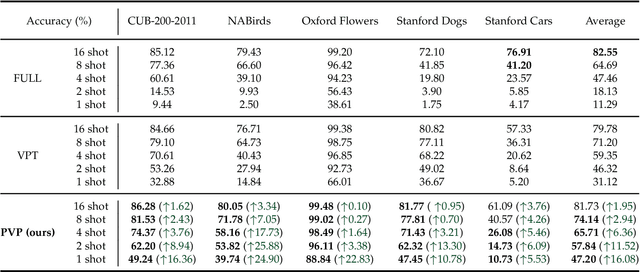
Large-scale pre-trained transformers have demonstrated remarkable success in various computer vision tasks. However, it is still highly challenging to fully fine-tune these models for downstream tasks due to their high computational and storage costs. Recently, Parameter-Efficient Tuning (PETuning) techniques, e.g., Visual Prompt Tuning (VPT) and Low-Rank Adaptation (LoRA), have significantly reduced the computation and storage cost by inserting lightweight prompt modules into the pre-trained models and tuning these prompt modules with a small number of trainable parameters, while keeping the transformer backbone frozen. Although only a few parameters need to be adjusted, most PETuning methods still require a significant amount of downstream task training data to achieve good results. The performance is inadequate on low-data regimes, especially when there are only one or two examples per class. To this end, we first empirically identify the poor performance is mainly due to the inappropriate way of initializing prompt modules, which has also been verified in the pre-trained language models. Next, we propose a Pre-trained Visual Parameter-efficient (PVP) Tuning framework, which pre-trains the parameter-efficient tuning modules first and then leverages the pre-trained modules along with the pre-trained transformer backbone to perform parameter-efficient tuning on downstream tasks. Experiment results on five Fine-Grained Visual Classification (FGVC) and VTAB-1k datasets demonstrate that our proposed method significantly outperforms state-of-the-art PETuning methods.
Network Enhancement: a general method to denoise weighted biological networks
Jun 01, 2018



Networks are ubiquitous in biology where they encode connectivity patterns at all scales of organization, from molecular to the biome. However, biological networks are noisy due to the limitations of measurement technology and inherent natural variation, which can hamper discovery of network patterns and dynamics. We propose Network Enhancement (NE), a method for improving the signal-to-noise ratio of undirected, weighted networks. NE uses a doubly stochastic matrix operator that induces sparsity and provides a closed-form solution that increases spectral eigengap of the input network. As a result, NE removes weak edges, enhances real connections, and leads to better downstream performance. Experiments show that NE improves gene function prediction by denoising tissue-specific interaction networks, alleviates interpretation of noisy Hi-C contact maps from the human genome, and boosts fine-grained identification accuracy of species. Our results indicate that NE is widely applicable for denoising biological networks.
SIMLR: A Tool for Large-Scale Genomic Analyses by Multi-Kernel Learning
Jan 18, 2018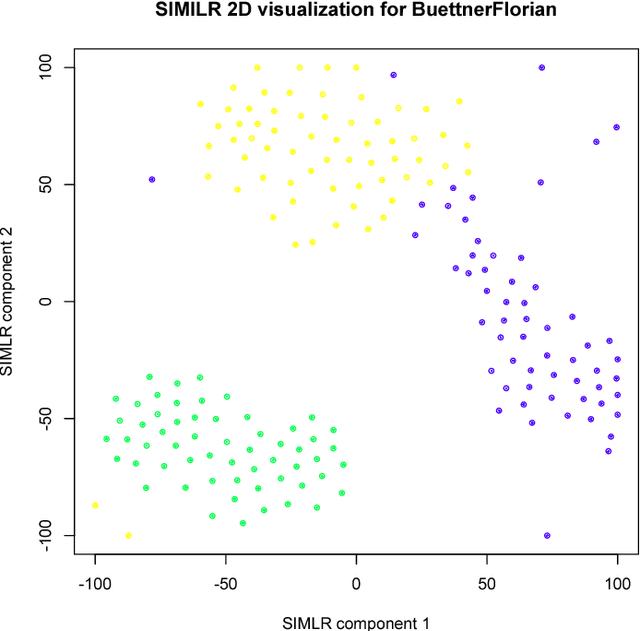

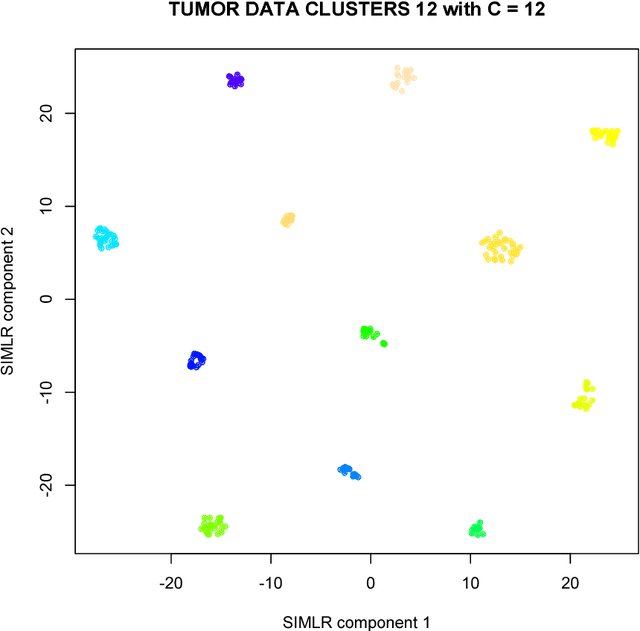
We here present SIMLR (Single-cell Interpretation via Multi-kernel LeaRning), an open-source tool that implements a novel framework to learn a sample-to-sample similarity measure from expression data observed for heterogenous samples. SIMLR can be effectively used to perform tasks such as dimension reduction, clustering, and visualization of heterogeneous populations of samples. SIMLR was benchmarked against state-of-the-art methods for these three tasks on several public datasets, showing it to be scalable and capable of greatly improving clustering performance, as well as providing valuable insights by making the data more interpretable via better a visualization. Availability and Implementation SIMLR is available on GitHub in both R and MATLAB implementations. Furthermore, it is also available as an R package on http://bioconductor.org.