 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-Based mmWave Radar Point Cloud Enhancement Driven by Range Images
Mar 04, 2025Millimeter-wave (mmWave) radar has attracted significant attention in robotics and autonomous driving. However, despite the perception stability in harsh environments, the point cloud generated by mmWave radar is relatively sparse while containing significant noise, which limits its further development. Traditional mmWave radar enhancement approaches often struggle to leverage the effectiveness of diffusion models in super-resolution, largely due to the unnatural range-azimuth heatmap (RAH) or bird's eye view (BEV) representation. To overcome this limitation, we propose a novel method that pioneers the application of fusing range images with image diffusion models, achieving accurate and dense mmWave radar point clouds that are similar to LiDAR. Benefitting from the projection that aligns with human observation, the range image representation of mmWave radar is close to natural images, allowing the knowledge from pre-trained image diffusion models to be effectively transferred, significantly improving the overall performance. Extensive evaluations on both public datasets and self-constructed datasets demonstrate that our approach provides substantial improvements, establishing a new state-of-the-art performance in generating truly three-dimensional LiDAR-like point clouds via mmWave radar.
Bridging VLM and KMP: Enabling Fine-grained robotic manipulation via Semantic Keypoints Representation
Mar 04, 2025
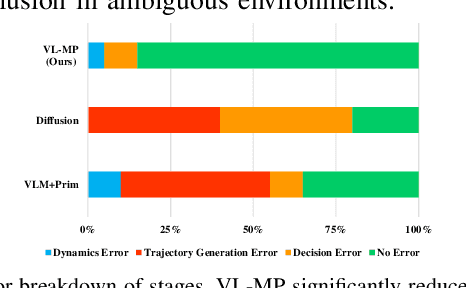
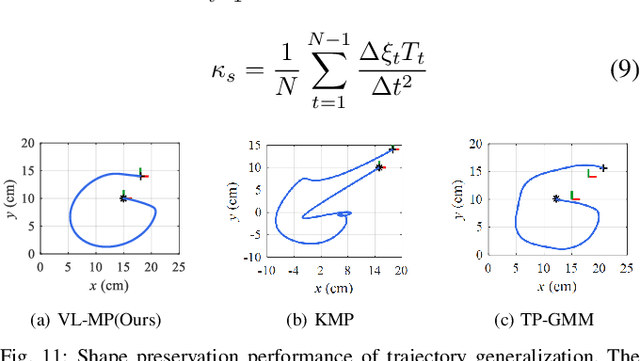
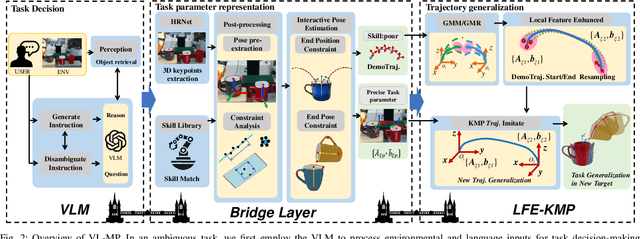
From early Movement Primitive (MP) techniques to modern Vision-Language Models (VLMs), autonomous manipulation has remained a pivotal topic in robotics. As two extremes, VLM-based methods emphasize zero-shot and adaptive manipulation but struggle with fine-grained planning. In contrast, MP-based approaches excel in precise trajectory generalization but lack decision-making ability. To leverage the strengths of the two frameworks, we propose VL-MP, which integrates VLM with Kernelized Movement Primitives (KMP) via a low-distortion decision information transfer bridge, enabling fine-grained robotic manipulation under ambiguous situations. One key of VL-MP is the accurate representation of task decision parameters through semantic keypoints constraints, leading to more precise task parameter generation. Additionally, we introduce a local trajectory feature-enhanced KMP to support VL-MP, thereby achieving shape preservation for complex trajectories. Extensive experiments conducted in complex real-world environments validate the effectiveness of VL-MP for adaptive and fine-grained manipulation.
Morpho-Aware Global Attention for Image Matting
Nov 15, 2024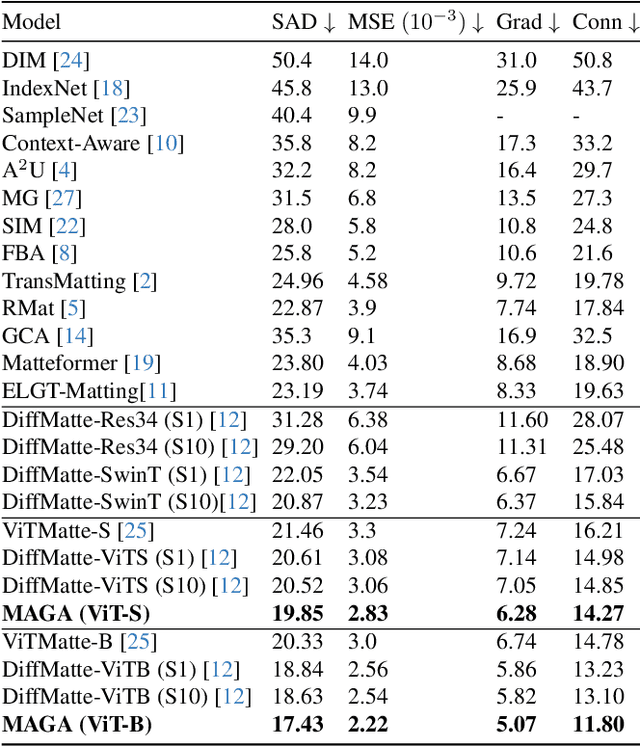
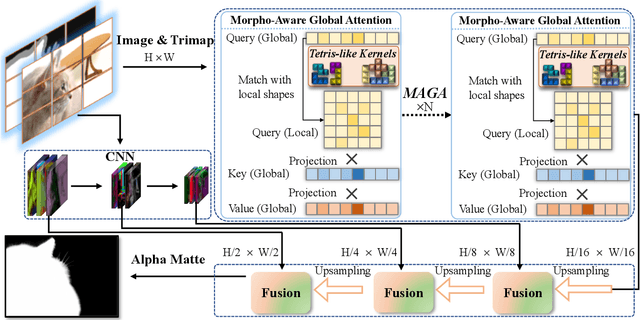
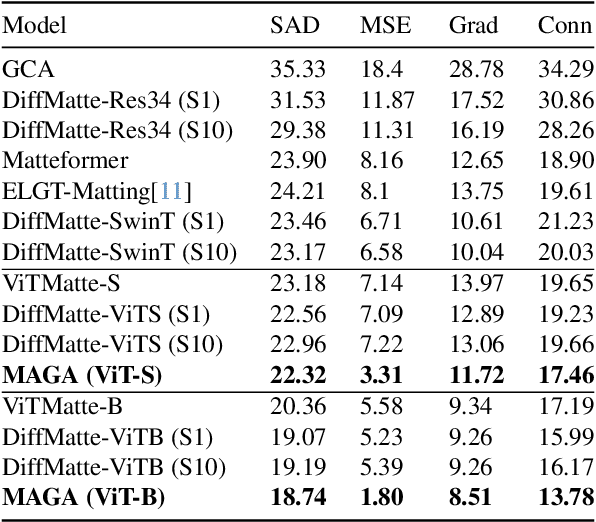
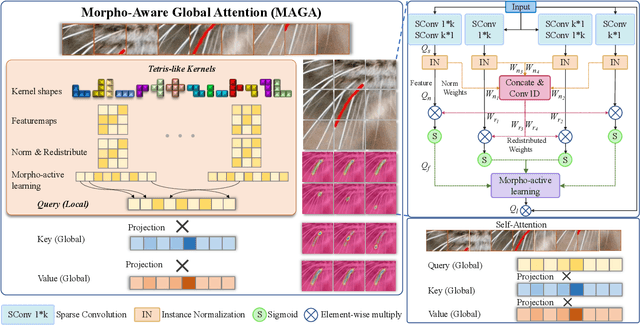
Vision Transformers (ViTs) and Convolutional Neural Networks (CNNs) face inherent challenges in image matting, particularly in preserving fine structural details. ViTs, with their global receptive field enabled by the self-attention mechanism, often lose local details such as hair strands. Conversely, CNNs, constrained by their local receptive field, rely on deeper layers to approximate global context but struggle to retain fine structures at greater depths. To overcome these limitations, we propose a novel Morpho-Aware Global Attention (MAGA) mechanism, designed to effectively capture the morphology of fine structures. MAGA employs Tetris-like convolutional patterns to align the local shapes of fine structures, ensuring optimal local correspondence while maintaining sensitivity to morphological details. The extracted local morphology information is used as query embeddings, which are projected onto global key embeddings to emphasize local details in a broader context. Subsequently, by projecting onto value embeddings, MAGA seamlessly integrates these emphasized morphological details into a unified global structure. This approach enables MAGA to simultaneously focus on local morphology and unify these details into a coherent whole, effectively preserving fine structures. Extensive experiments show that our MAGA-based ViT achieves significant performance gains, outperforming state-of-the-art methods across two benchmarks with average improvements of 4.3% in SAD and 39.5% in MSE.
Tri-axial Self-Attention for Concurrent Activity Recognition
Dec 06, 2018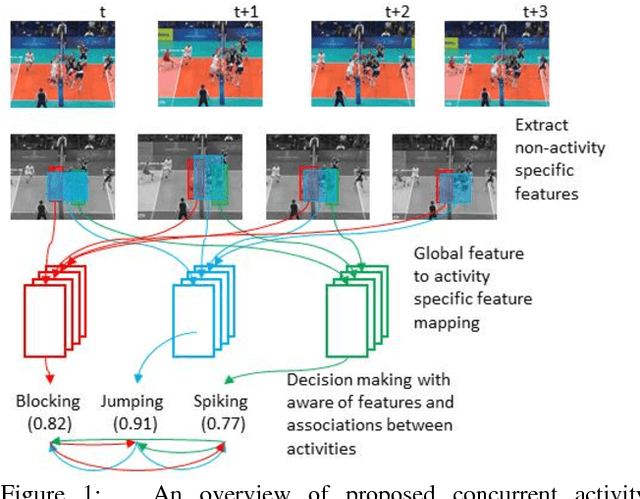
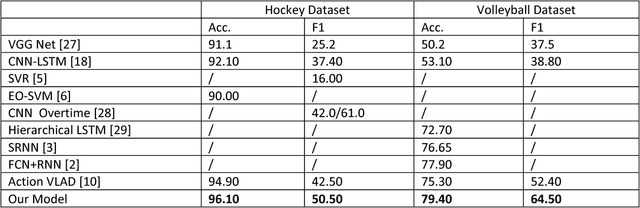
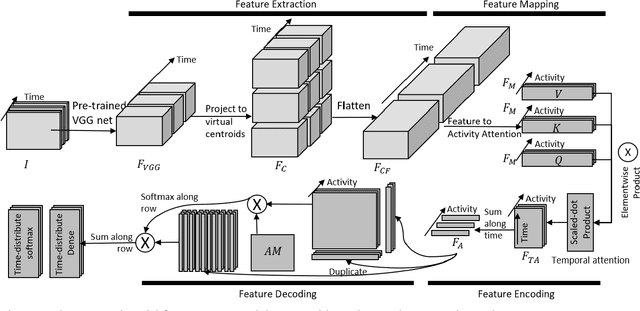
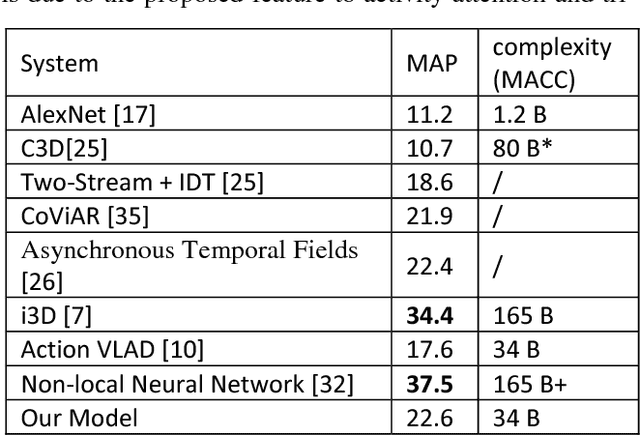
We present a system for concurrent activity recognition. To extract features associated with different activities, we propose a feature-to-activity attention that maps the extracted global features to sub-features associated with individual activities. To model the temporal associations of individual activities, we propose a transformer-network encoder that models independent temporal associations for each activity. To make the concurrent activity prediction aware of the potential associations between activities, we propose self-attention with an association mask. Our system achieved state-of-the-art or comparable performance on three commonly used concurrent activity detection datasets. Our visualizations demonstrate that our system is able to locate the important spatial-temporal features for final decision making. We also showed that our system can be applied to general multilabel classification problems.