 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorpho-Aware Global Attention for Image Matting
Paper and Code
Nov 15, 2024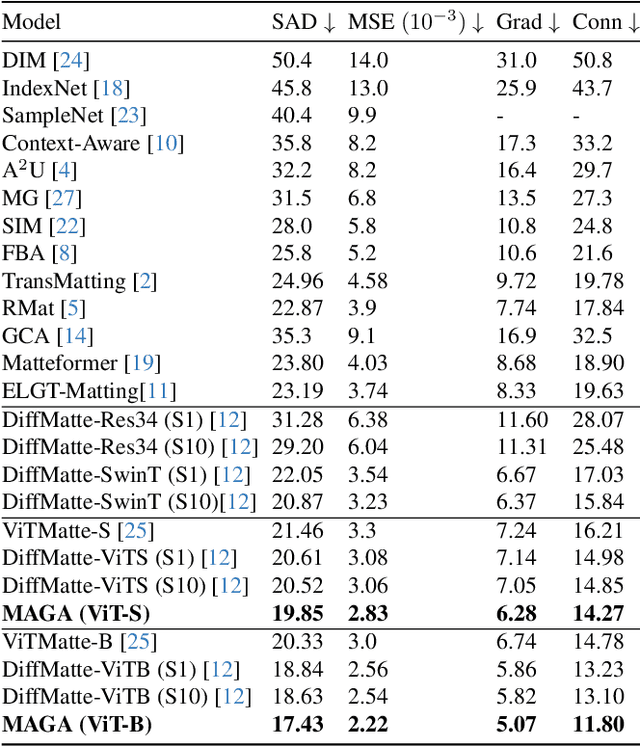
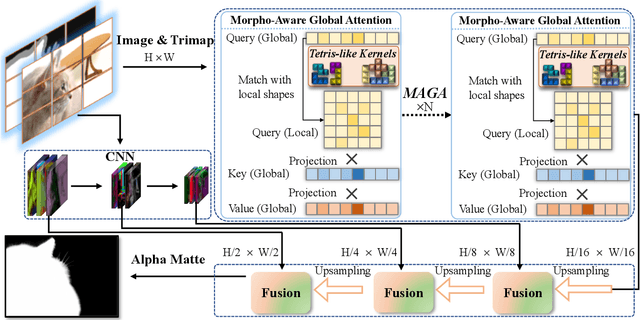
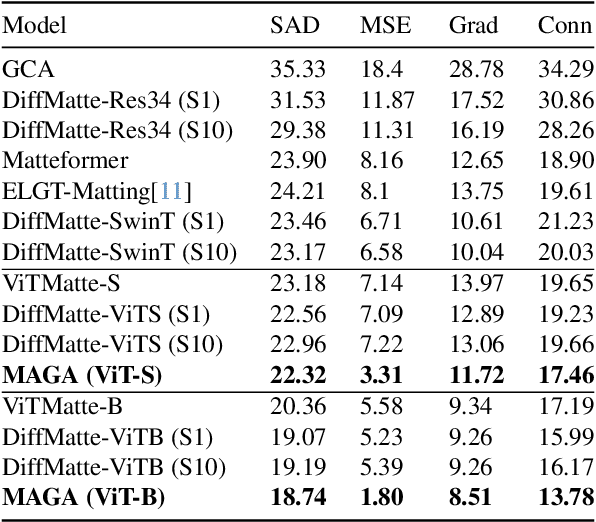
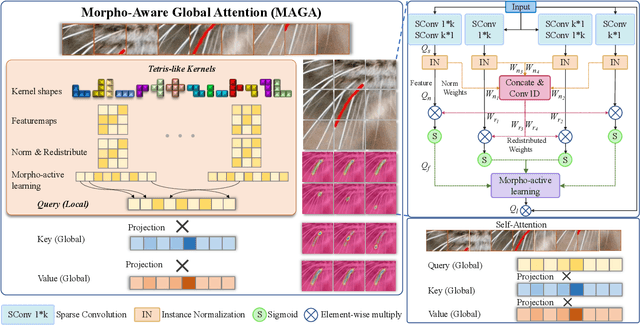
Vision Transformers (ViTs) and Convolutional Neural Networks (CNNs) face inherent challenges in image matting, particularly in preserving fine structural details. ViTs, with their global receptive field enabled by the self-attention mechanism, often lose local details such as hair strands. Conversely, CNNs, constrained by their local receptive field, rely on deeper layers to approximate global context but struggle to retain fine structures at greater depths. To overcome these limitations, we propose a novel Morpho-Aware Global Attention (MAGA) mechanism, designed to effectively capture the morphology of fine structures. MAGA employs Tetris-like convolutional patterns to align the local shapes of fine structures, ensuring optimal local correspondence while maintaining sensitivity to morphological details. The extracted local morphology information is used as query embeddings, which are projected onto global key embeddings to emphasize local details in a broader context. Subsequently, by projecting onto value embeddings, MAGA seamlessly integrates these emphasized morphological details into a unified global structure. This approach enables MAGA to simultaneously focus on local morphology and unify these details into a coherent whole, effectively preserving fine structures. Extensive experiments show that our MAGA-based ViT achieves significant performance gains, outperforming state-of-the-art methods across two benchmarks with average improvements of 4.3% in SAD and 39.5% in MSE.