 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEventMamba: Enhancing Spatio-Temporal Locality with State Space Models for Event-Based Video Reconstruction
Mar 27, 2025Leveraging its robust linear global modeling capability, Mamba has notably excelled in computer vision. Despite its success, existing Mamba-based vision models have overlooked the nuances of event-driven tasks, especially in video reconstruction. Event-based video reconstruction (EBVR) demands spatial translation invariance and close attention to local event relationships in the spatio-temporal domain. Unfortunately, conventional Mamba algorithms apply static window partitions and standard reshape scanning methods, leading to significant losses in local connectivity. To overcome these limitations, we introduce EventMamba--a specialized model designed for EBVR tasks. EventMamba innovates by incorporating random window offset (RWO) in the spatial domain, moving away from the restrictive fixed partitioning. Additionally, it features a new consistent traversal serialization approach in the spatio-temporal domain, which maintains the proximity of adjacent events both spatially and temporally. These enhancements enable EventMamba to retain Mamba's robust modeling capabilities while significantly preserving the spatio-temporal locality of event data. Comprehensive testing on multiple datasets shows that EventMamba markedly enhances video reconstruction, drastically improving computation speed while delivering superior visual quality compared to Transformer-based methods.
Morpho-Aware Global Attention for Image Matting
Nov 15, 2024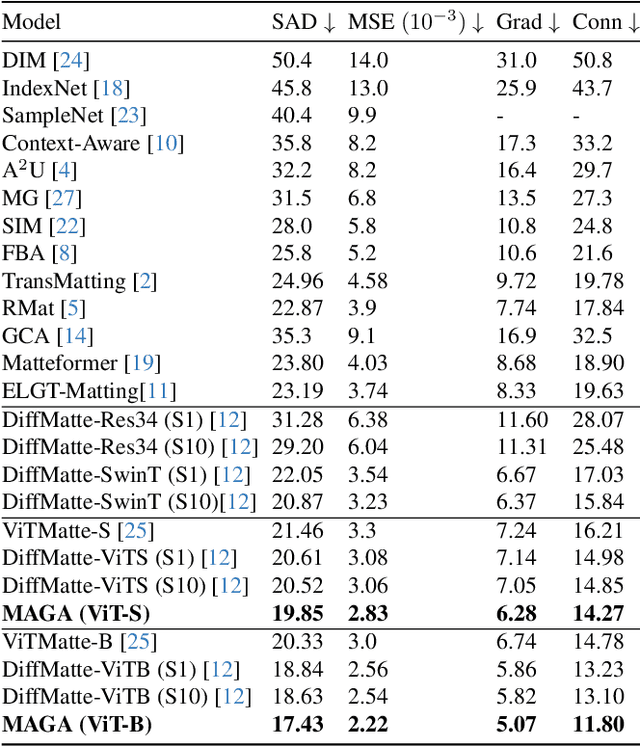
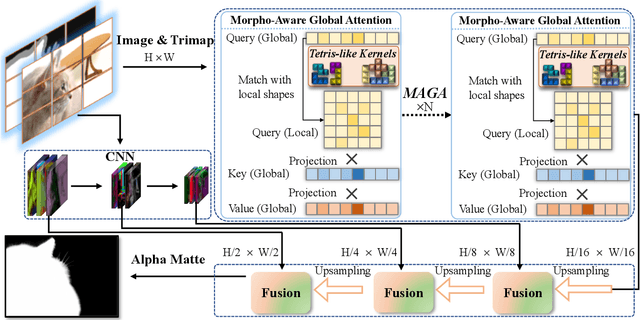
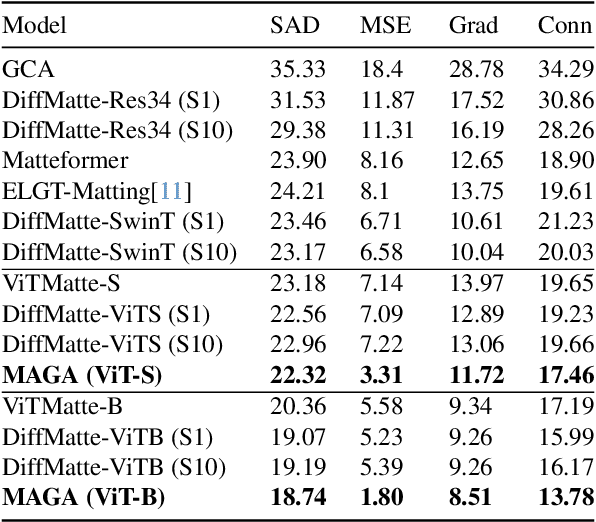
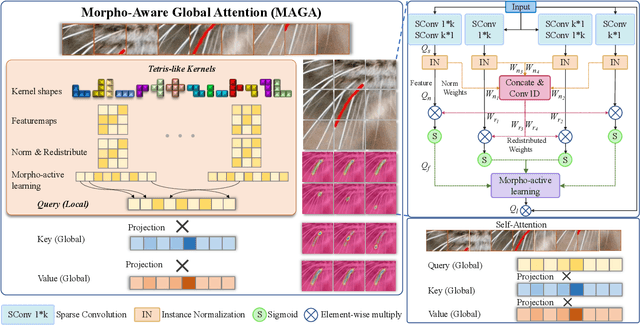
Vision Transformers (ViTs) and Convolutional Neural Networks (CNNs) face inherent challenges in image matting, particularly in preserving fine structural details. ViTs, with their global receptive field enabled by the self-attention mechanism, often lose local details such as hair strands. Conversely, CNNs, constrained by their local receptive field, rely on deeper layers to approximate global context but struggle to retain fine structures at greater depths. To overcome these limitations, we propose a novel Morpho-Aware Global Attention (MAGA) mechanism, designed to effectively capture the morphology of fine structures. MAGA employs Tetris-like convolutional patterns to align the local shapes of fine structures, ensuring optimal local correspondence while maintaining sensitivity to morphological details. The extracted local morphology information is used as query embeddings, which are projected onto global key embeddings to emphasize local details in a broader context. Subsequently, by projecting onto value embeddings, MAGA seamlessly integrates these emphasized morphological details into a unified global structure. This approach enables MAGA to simultaneously focus on local morphology and unify these details into a coherent whole, effectively preserving fine structures. Extensive experiments show that our MAGA-based ViT achieves significant performance gains, outperforming state-of-the-art methods across two benchmarks with average improvements of 4.3% in SAD and 39.5% in MSE.
Discovering Intrinsic Spatial-Temporal Logic Rules to Explain Human Actions
Jun 21, 2023


We propose a logic-informed knowledge-driven modeling framework for human movements by analyzing their trajectories. Our approach is inspired by the fact that human actions are usually driven by their intentions or desires, and are influenced by environmental factors such as the spatial relationships with surrounding objects. In this paper, we introduce a set of spatial-temporal logic rules as knowledge to explain human actions. These rules will be automatically discovered from observational data. To learn the model parameters and the rule content, we design an expectation-maximization (EM) algorithm, which treats the rule content as latent variables. The EM algorithm alternates between the E-step and M-step: in the E-step, the posterior distribution over the latent rule content is evaluated; in the M-step, the rule generator and model parameters are jointly optimized by maximizing the current expected log-likelihood. Our model may have a wide range of applications in areas such as sports analytics, robotics, and autonomous cars, where understanding human movements are essential. We demonstrate the model's superior interpretability and prediction performance on pedestrian and NBA basketball player datasets, both achieving promising results.