 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2025 Image Shadow Removal Challenge Report
Jun 18, 2025



This work examines the findings of the NTIRE 2025 Shadow Removal Challenge. A total of 306 participants have registered, with 17 teams successfully submitting their solutions during the final evaluation phase. Following the last two editions, this challenge had two evaluation tracks: one focusing on reconstruction fidelity and the other on visual perception through a user study. Both tracks were evaluated with images from the WSRD+ dataset, simulating interactions between self- and cast-shadows with a large number of diverse objects, textures, and materials.
EventMamba: Enhancing Spatio-Temporal Locality with State Space Models for Event-Based Video Reconstruction
Mar 27, 2025Leveraging its robust linear global modeling capability, Mamba has notably excelled in computer vision. Despite its success, existing Mamba-based vision models have overlooked the nuances of event-driven tasks, especially in video reconstruction. Event-based video reconstruction (EBVR) demands spatial translation invariance and close attention to local event relationships in the spatio-temporal domain. Unfortunately, conventional Mamba algorithms apply static window partitions and standard reshape scanning methods, leading to significant losses in local connectivity. To overcome these limitations, we introduce EventMamba--a specialized model designed for EBVR tasks. EventMamba innovates by incorporating random window offset (RWO) in the spatial domain, moving away from the restrictive fixed partitioning. Additionally, it features a new consistent traversal serialization approach in the spatio-temporal domain, which maintains the proximity of adjacent events both spatially and temporally. These enhancements enable EventMamba to retain Mamba's robust modeling capabilities while significantly preserving the spatio-temporal locality of event data. Comprehensive testing on multiple datasets shows that EventMamba markedly enhances video reconstruction, drastically improving computation speed while delivering superior visual quality compared to Transformer-based methods.
Uni-NaVid: A Video-based Vision-Language-Action Model for Unifying Embodied Navigation Tasks
Dec 09, 2024A practical navigation agent must be capable of handling a wide range of interaction demands, such as following instructions, searching objects, answering questions, tracking people, and more. Existing models for embodied navigation fall short of serving as practical generalists in the real world, as they are often constrained by specific task configurations or pre-defined maps with discretized waypoints. In this work, we present Uni-NaVid, the first video-based vision-language-action (VLA) model designed to unify diverse embodied navigation tasks and enable seamless navigation for mixed long-horizon tasks in unseen real-world environments. Uni-NaVid achieves this by harmonizing the input and output data configurations for all commonly used embodied navigation tasks and thereby integrating all tasks in one model. For training Uni-NaVid, we collect 3.6 million navigation data samples in total from four essential navigation sub-tasks and foster synergy in learning across them. Extensive experiments on comprehensive navigation benchmarks clearly demonstrate the advantages of unification modeling in Uni-NaVid and show it achieves state-of-the-art performance. Additionally, real-world experiments confirm the model's effectiveness and efficiency, shedding light on its strong generalizability.
MugenNet: A Novel Combined Convolution Neural Network and Transformer Network with its Application for Colonic Polyp Image Segmentation
Mar 31, 2024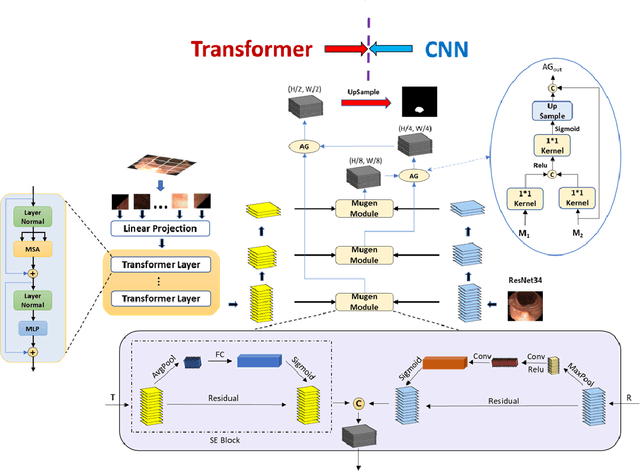
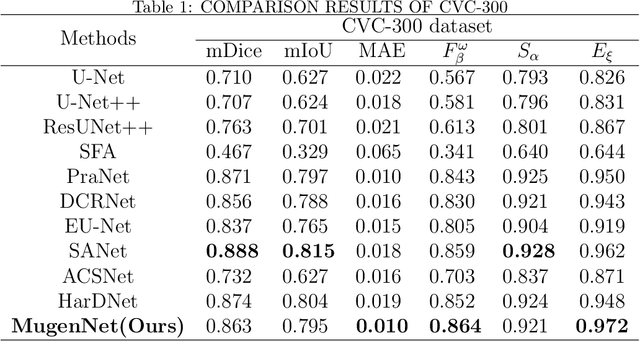
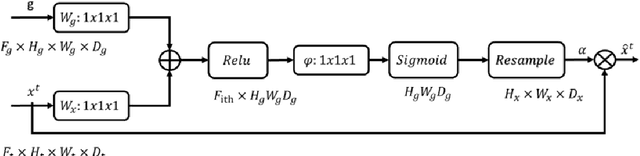
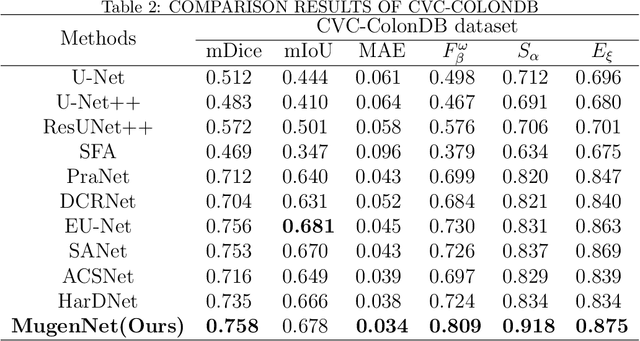
Biomedical image segmentation is a very important part in disease diagnosis. The term "colonic polyps" refers to polypoid lesions that occur on the surface of the colonic mucosa within the intestinal lumen. In clinical practice, early detection of polyps is conducted through colonoscopy examinations and biomedical image processing. Therefore, the accurate polyp image segmentation is of great significance in colonoscopy examinations. Convolutional Neural Network (CNN) is a common automatic segmentation method, but its main disadvantage is the long training time. Transformer utilizes a self-attention mechanism, which essentially assigns different importance weights to each piece of information, thus achieving high computational efficiency during segmentation. However, a potential drawback is the risk of information loss. In the study reported in this paper, based on the well-known hybridization principle, we proposed a method to combine CNN and Transformer to retain the strengths of both, and we applied this method to build a system called MugenNet for colonic polyp image segmentation. We conducted a comprehensive experiment to compare MugenNet with other CNN models on five publicly available datasets. The ablation experiment on MugentNet was conducted as well. The experimental results show that MugenNet achieves significantly higher processing speed and accuracy compared with CNN alone. The generalized implication with our work is a method to optimally combine two complimentary methods of machine learning.
NaVid: Video-based VLM Plans the Next Step for Vision-and-Language Navigation
Mar 01, 2024



Vision-and-Language Navigation (VLN) stands as a key research problem of Embodied AI, aiming at enabling agents to navigate in unseen environments following linguistic instructions. In this field, generalization is a long-standing challenge, either to out-of-distribution scenes or from Sim to Real. In this paper, we propose NaVid, a video-based large vision language model (VLM), to mitigate such a generalization gap. NaVid makes the first endeavour to showcase the capability of VLMs to achieve state-of-the-art level navigation performance without any maps, odometer and depth inputs. Following human instruction, NaVid only requires an on-the-fly video stream from a monocular RGB camera equipped on the robot to output the next-step action. Our formulation mimics how humans navigate and naturally gets rid of the problems introduced by odometer noises, and the Sim2Real gaps from map or depth inputs. Moreover, our video-based approach can effectively encode the historical observations of robots as spatio-temporal contexts for decision-making and instruction following. We train NaVid with 550k navigation samples collected from VLN-CE trajectories, including action-planning and instruction-reasoning samples, along with 665k large-scale web data. Extensive experiments show that NaVid achieves SOTA performance in simulation environments and the real world, demonstrating superior cross-dataset and Sim2Real transfer. We thus believe our proposed VLM approach plans the next step for not only the navigation agents but also this research field.
Generating Visually Realistic Adversarial Patch
Dec 05, 2023Deep neural networks (DNNs) are vulnerable to various types of adversarial examples, bringing huge threats to security-critical applications. Among these, adversarial patches have drawn increasing attention due to their good applicability to fool DNNs in the physical world. However, existing works often generate patches with meaningless noise or patterns, making it conspicuous to humans. To address this issue, we explore how to generate visually realistic adversarial patches to fool DNNs. Firstly, we analyze that a high-quality adversarial patch should be realistic, position irrelevant, and printable to be deployed in the physical world. Based on this analysis, we propose an effective attack called VRAP, to generate visually realistic adversarial patches. Specifically, VRAP constrains the patch in the neighborhood of a real image to ensure the visual reality, optimizes the patch at the poorest position for position irrelevance, and adopts Total Variance loss as well as gamma transformation to make the generated patch printable without losing information. Empirical evaluations on the ImageNet dataset demonstrate that the proposed VRAP exhibits outstanding attack performance in the digital world. Moreover, the generated adversarial patches can be disguised as the scrawl or logo in the physical world to fool the deep models without being detected, bringing significant threats to DNNs-enabled applications.
LFAA: Crafting Transferable Targeted Adversarial Examples with Low-Frequency Perturbations
Nov 01, 2023



Deep neural networks are susceptible to adversarial attacks, which pose a significant threat to their security and reliability in real-world applications. The most notable adversarial attacks are transfer-based attacks, where an adversary crafts an adversarial example to fool one model, which can also fool other models. While previous research has made progress in improving the transferability of untargeted adversarial examples, the generation of targeted adversarial examples that can transfer between models remains a challenging task. In this work, we present a novel approach to generate transferable targeted adversarial examples by exploiting the vulnerability of deep neural networks to perturbations on high-frequency components of images. We observe that replacing the high-frequency component of an image with that of another image can mislead deep models, motivating us to craft perturbations containing high-frequency information to achieve targeted attacks. To this end, we propose a method called Low-Frequency Adversarial Attack (\name), which trains a conditional generator to generate targeted adversarial perturbations that are then added to the low-frequency component of the image. Extensive experiments on ImageNet demonstrate that our proposed approach significantly outperforms state-of-the-art methods, improving targeted attack success rates by a margin from 3.2\% to 15.5\%.
Boosting Adversarial Transferability by Block Shuffle and Rotation
Aug 22, 2023Adversarial examples mislead deep neural networks with imperceptible perturbations and have brought significant threats to deep learning. An important aspect is their transferability, which refers to their ability to deceive other models, thus enabling attacks in the black-box setting. Though various methods have been proposed to boost transferability, the performance still falls short compared with white-box attacks. In this work, we observe that existing input transformation based attacks, one of the mainstream transfer-based attacks, result in different attention heatmaps on various models, which might limit the transferability. We also find that breaking the intrinsic relation of the image can disrupt the attention heatmap of the original image. Based on this finding, we propose a novel input transformation based attack called block shuffle and rotation (BSR). Specifically, BSR splits the input image into several blocks, then randomly shuffles and rotates these blocks to construct a set of new images for gradient calculation. Empirical evaluations on the ImageNet dataset demonstrate that BSR could achieve significantly better transferability than the existing input transformation based methods under single-model and ensemble-model settings. Combining BSR with the current input transformation method can further improve the transferability, which significantly outperforms the state-of-the-art methods.