 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Pick: A Visuomotor Policy for Clustered Strawberry Picking
Sep 18, 2025Strawberries naturally grow in clusters, interwoven with leaves, stems, and other fruits, which frequently leads to occlusion. This inherent growth habit presents a significant challenge for robotic picking, as traditional percept-plan-control systems struggle to reach fruits amid the clutter. Effectively picking an occluded strawberry demands dexterous manipulation to carefully bypass or gently move the surrounding soft objects and precisely access the ideal picking point located at the stem just above the calyx. To address this challenge, we introduce a strawberry-picking robotic system that learns from human demonstrations. Our system features a 4-DoF SCARA arm paired with a human teleoperation interface for efficient data collection and leverages an End Pose Assisted Action Chunking Transformer (ACT) to develop a fine-grained visuomotor picking policy. Experiments under various occlusion scenarios demonstrate that our modified approach significantly outperforms the direct implementation of ACT, underscoring its potential for practical application in occluded strawberry picking.
MCPWorld: A Unified Benchmarking Testbed for API, GUI, and Hybrid Computer Use Agents
Jun 09, 2025(M)LLM-powered computer use agents (CUA) are emerging as a transformative technique to automate human-computer interaction. However, existing CUA benchmarks predominantly target GUI agents, whose evaluation methods are susceptible to UI changes and ignore function interactions exposed by application APIs, e.g., Model Context Protocol (MCP). To this end, we propose MCPWorld, the first automatic CUA testbed for API, GUI, and API-GUI hybrid agents. A key principle of MCPWorld is the use of "white-box apps", i.e., those with source code availability and can be revised/re-compiled as needed (e.g., adding MCP support), with two notable advantages: (1) It greatly broadens the design space of CUA, such as what and how the app features to be exposed/extracted as CUA-callable APIs. (2) It allows MCPWorld to programmatically verify task completion by directly monitoring application behavior through techniques like dynamic code instrumentation, offering robust, accurate CUA evaluation decoupled from specific agent implementations or UI states. Currently, MCPWorld includes 201 well curated and annotated user tasks, covering diversified use cases and difficulty levels. MCPWorld is also fully containerized with GPU acceleration support for flexible adoption on different OS/hardware environments. Our preliminary experiments, using a representative LLM-powered CUA framework, achieve 75.12% task completion accuracy, simultaneously providing initial evidence on the practical effectiveness of agent automation leveraging MCP. Overall, we anticipate MCPWorld to facilitate and standardize the benchmarking of next-generation computer use agents that can leverage rich external tools. Our code and dataset are publicly available at https://github.com/SAAgent/MCPWorld.
Strawberry Robotic Operation Interface: An Open-Source Device for Collecting Dexterous Manipulation Data in Robotic Strawberry Farming
Jan 28, 2025



The strawberry farming is labor-intensive, particularly in tasks requiring dexterous manipulation such as picking occluded strawberries. To address this challenge, we present the Strawberry Robotic Operation Interface (SROI), an open-source device designed for collecting dexterous manipulation data in robotic strawberry farming. The SROI features a handheld unit with a modular end effector, a stereo robotic camera, enabling the easy collection of demonstration data in field environments. A data post-processing pipeline is introduced to extract spatial trajectories and gripper states from the collected data. Additionally, we release an open-source dataset of strawberry picking demonstrations to facilitate research in dexterous robotic manipulation. The SROI represents a step toward automating complex strawberry farming tasks, reducing reliance on manual labor.
Efficient and Safe Trajectory Planning for Autonomous Agricultural Vehicle Headland Turning in Cluttered Orchard Environments
Jan 18, 2025



Autonomous agricultural vehicles (AAVs), including field robots and autonomous tractors, are becoming essential in modern farming by improving efficiency and reducing labor costs. A critical task in AAV operations is headland turning between crop rows. This task is challenging in orchards with limited headland space, irregular boundaries, operational constraints, and static obstacles. While traditional trajectory planning methods work well in arable farming, they often fail in cluttered orchard environments. This letter presents a novel trajectory planner that enhances the safety and efficiency of AAV headland maneuvers, leveraging advancements in autonomous driving. Our approach includes an efficient front-end algorithm and a high-performance back-end optimization. Applied to vehicles with various implements, it outperforms state-of-the-art methods in both standard and challenging orchard fields. This work bridges agricultural and autonomous driving technologies, facilitating a broader adoption of AAVs in complex orchards.
Asymmetric Graph Error Control with Low Complexity in Causal Bandits
Aug 20, 2024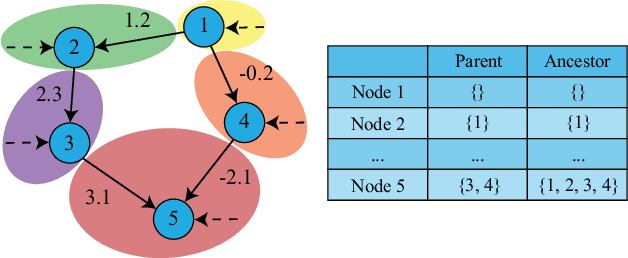
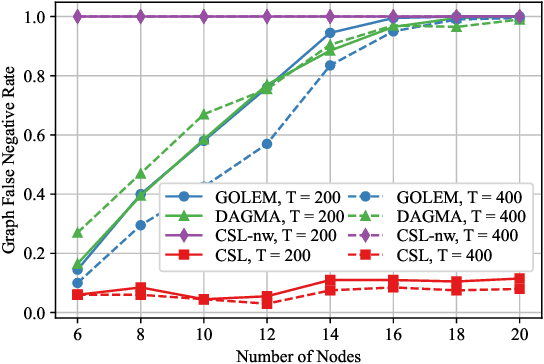
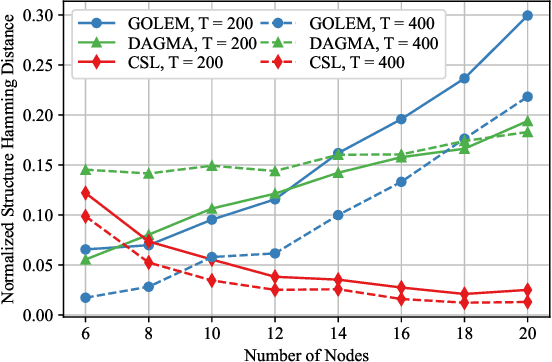
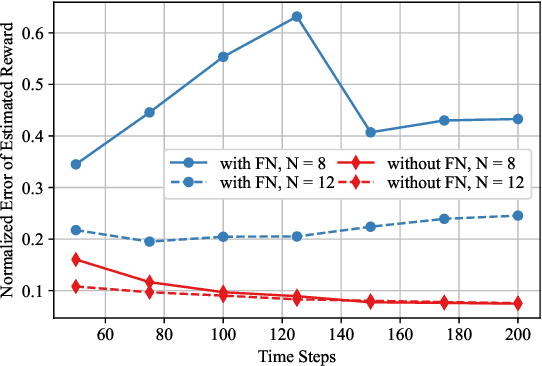
In this paper, the causal bandit problem is investigated, in which the objective is to select an optimal sequence of interventions on nodes in a causal graph. It is assumed that the graph is governed by linear structural equations; it is further assumed that both the causal topology and the distribution of interventions are unknown. By exploiting the causal relationships between the nodes whose signals contribute to the reward, interventions are optimized. First, based on the difference between the two types of graph identification errors (false positives and negatives), a causal graph learning method is proposed, which strongly reduces sample complexity relative to the prior art by learning sub-graphs. Under the assumption of Gaussian exogenous inputs and minimum-mean squared error weight estimation, a new uncertainty bound tailored to the causal bandit problem is derived. This uncertainty bound drives an upper confidence bound based intervention selection to optimize the reward. To cope with non-stationary bandits, a sub-graph change detection mechanism is proposed, with high sample efficiency. Numerical results compare the new methodology to existing schemes and show a substantial performance improvement in both stationary and non-stationary settings. Compared to existing approaches, the proposed scheme takes 67% fewer samples to learn the causal structure and achieves an average reward gain of 85%.
Advancing H&E-to-IHC Stain Translation in Breast Cancer: A Multi-Magnification and Attention-Based Approach
Aug 04, 2024
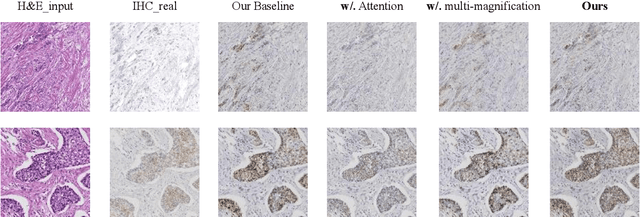


Breast cancer presents a significant healthcare challenge globally, demanding precise diagnostics and effective treatment strategies, where histopathological examination of Hematoxylin and Eosin (H&E) stained tissue sections plays a central role. Despite its importance, evaluating specific biomarkers like Human Epidermal Growth Factor Receptor 2 (HER2) for personalized treatment remains constrained by the resource-intensive nature of Immunohistochemistry (IHC). Recent strides in deep learning, particularly in image-to-image translation, offer promise in synthesizing IHC-HER2 slides from H\&E stained slides. However, existing methodologies encounter challenges, including managing multiple magnifications in pathology images and insufficient focus on crucial information during translation. To address these issues, we propose a novel model integrating attention mechanisms and multi-magnification information processing. Our model employs a multi-magnification processing strategy to extract and utilize information from various magnifications within pathology images, facilitating robust image translation. Additionally, an attention module within the generative network prioritizes critical information for image distribution translation while minimizing less pertinent details. Rigorous testing on a publicly available breast cancer dataset demonstrates superior performance compared to existing methods, establishing our model as a state-of-the-art solution in advancing pathology image translation from H&E to IHC staining.
MugenNet: A Novel Combined Convolution Neural Network and Transformer Network with its Application for Colonic Polyp Image Segmentation
Mar 31, 2024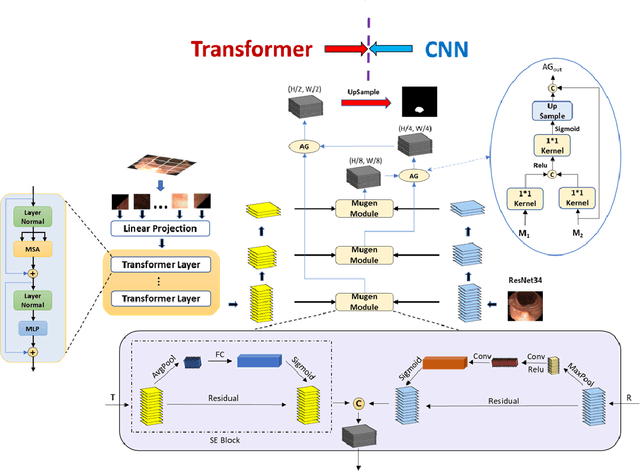
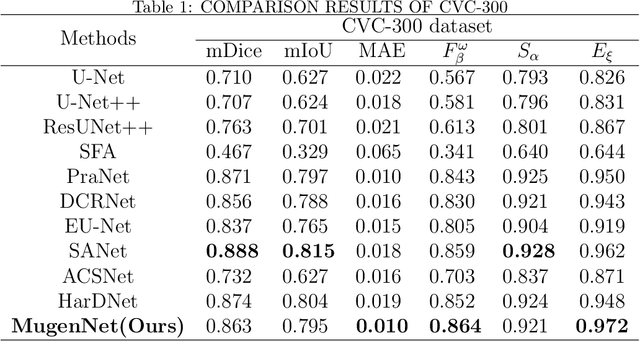
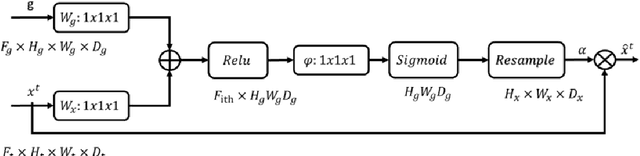
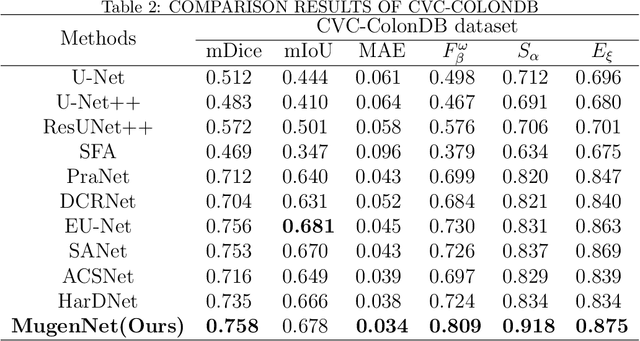
Biomedical image segmentation is a very important part in disease diagnosis. The term "colonic polyps" refers to polypoid lesions that occur on the surface of the colonic mucosa within the intestinal lumen. In clinical practice, early detection of polyps is conducted through colonoscopy examinations and biomedical image processing. Therefore, the accurate polyp image segmentation is of great significance in colonoscopy examinations. Convolutional Neural Network (CNN) is a common automatic segmentation method, but its main disadvantage is the long training time. Transformer utilizes a self-attention mechanism, which essentially assigns different importance weights to each piece of information, thus achieving high computational efficiency during segmentation. However, a potential drawback is the risk of information loss. In the study reported in this paper, based on the well-known hybridization principle, we proposed a method to combine CNN and Transformer to retain the strengths of both, and we applied this method to build a system called MugenNet for colonic polyp image segmentation. We conducted a comprehensive experiment to compare MugenNet with other CNN models on five publicly available datasets. The ablation experiment on MugentNet was conducted as well. The experimental results show that MugenNet achieves significantly higher processing speed and accuracy compared with CNN alone. The generalized implication with our work is a method to optimally combine two complimentary methods of machine learning.
MNN: Mixed Nearest-Neighbors for Self-Supervised Learning
Nov 13, 2023



In contrastive self-supervised learning, positive samples are typically drawn from the same image but in different augmented views, resulting in a relatively limited source of positive samples. An effective way to alleviate this problem is to incorporate the relationship between samples, which involves including the top-K nearest neighbors of positive samples. However, the problem of false neighbors (i.e., neighbors that do not belong to the same category as the positive sample) is an objective but often overlooked challenge due to the query of neighbor samples without supervision information. In this paper, we present a simple self-supervised learning framework called Mixed Nearest-Neighbors for Self-Supervised Learning (MNN). MNN optimizes the influence of neighbor samples on the semantics of positive samples through an intuitive weighting approach and image mixture operations. The results demonstrate that MNN exhibits exceptional generalization performance and training efficiency on four benchmark datasets.
Optimization-Based Motion Planning for Autonomous Agricultural Vehicles Turning in Constrained Headlands
Aug 02, 2023



Headland maneuvering is a crucial aspect of unmanned field operations for autonomous agricultural vehicles (AAVs). While motion planning for headland turning in open fields has been extensively studied and integrated into commercial auto-guidance systems, the existing methods primarily address scenarios with ample headland space and thus may not work in more constrained headland geometries. Commercial orchards often contain narrow and irregularly shaped headlands, which may include static obstacles,rendering the task of planning a smooth and collision-free turning trajectory difficult. To address this challenge, we propose an optimization-based motion planning algorithm for headland turning under geometrical constraints imposed by field geometry and obstacles.
MSVQ: Self-Supervised Learning with Multiple Sample Views and Queues
May 09, 2023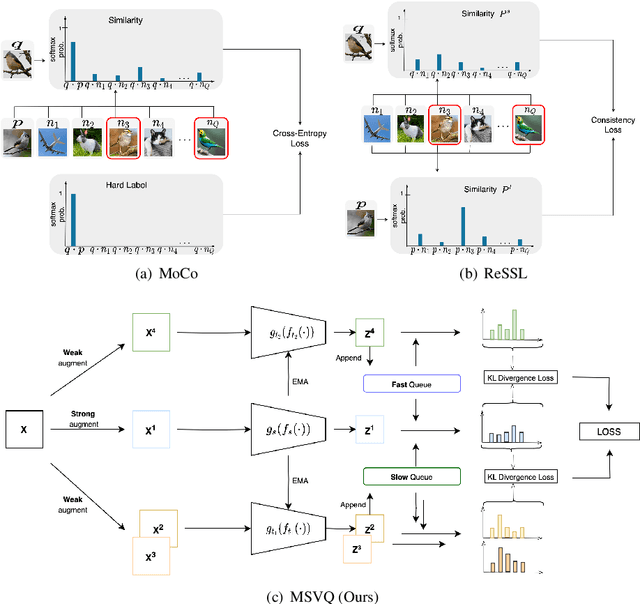
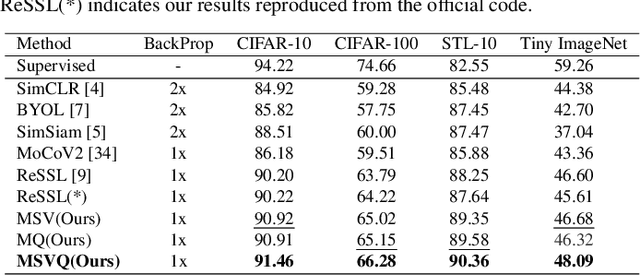
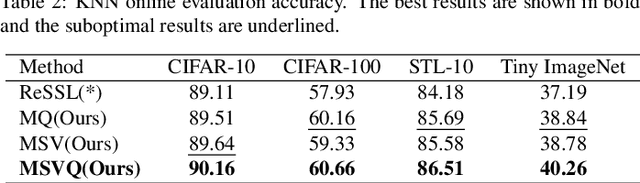
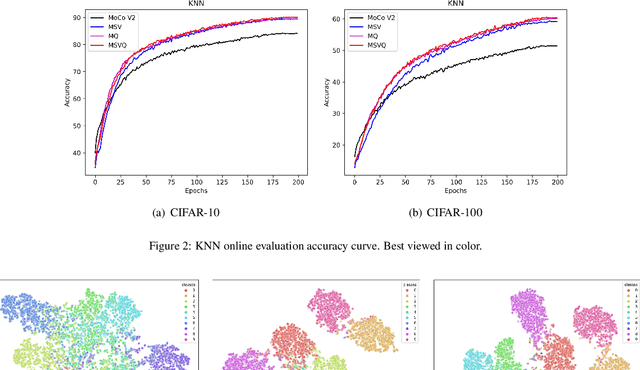
Self-supervised methods based on contrastive learning have achieved great success in unsupervised visual representation learning. However, most methods under this framework suffer from the problem of false negative samples. Inspired by mean shift for self-supervised learning, we propose a new simple framework, namely Multiple Sample Views and Queues (MSVQ). We jointly construct a soft label on-the-fly by introducing two complementary and symmetric ways: multiple augmented positive views and two momentum encoders forming various semantic features of negative samples. Two teacher networks perform similarity relationship calculations with negative samples and then transfer this knowledge to the student. Let the student mimic the similar relationship between the samples, thus giving the student a more flexible ability to identify false negative samples in the dataset. The classification results on four benchmark image datasets demonstrate the high effectiveness and efficiency of our approach compared to some classical methods. Source code and pretrained models are available at $\href{https://github.com/pc-cp/MSVQ}{this~http~URL}$.