 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLP-Net:An efficient lightweight network for segmentation of skin lesions
Jan 04, 2024Prompt treatment for melanoma is crucial. To assist physicians in identifying lesion areas precisely in a quick manner, we propose a novel skin lesion segmentation technique namely SLP-Net, an ultra-lightweight segmentation network based on the spiking neural P(SNP) systems type mechanism. Most existing convolutional neural networks achieve high segmentation accuracy while neglecting the high hardware cost. SLP-Net, on the contrary, has a very small number of parameters and a high computation speed. We design a lightweight multi-scale feature extractor without the usual encoder-decoder structure. Rather than a decoder, a feature adaptation module is designed to replace it and implement multi-scale information decoding. Experiments at the ISIC2018 challenge demonstrate that the proposed model has the highest Acc and DSC among the state-of-the-art methods, while experiments on the PH2 dataset also demonstrate a favorable generalization ability. Finally, we compare the computational complexity as well as the computational speed of the models in experiments, where SLP-Net has the highest overall superiority
MNN: Mixed Nearest-Neighbors for Self-Supervised Learning
Nov 13, 2023



In contrastive self-supervised learning, positive samples are typically drawn from the same image but in different augmented views, resulting in a relatively limited source of positive samples. An effective way to alleviate this problem is to incorporate the relationship between samples, which involves including the top-K nearest neighbors of positive samples. However, the problem of false neighbors (i.e., neighbors that do not belong to the same category as the positive sample) is an objective but often overlooked challenge due to the query of neighbor samples without supervision information. In this paper, we present a simple self-supervised learning framework called Mixed Nearest-Neighbors for Self-Supervised Learning (MNN). MNN optimizes the influence of neighbor samples on the semantics of positive samples through an intuitive weighting approach and image mixture operations. The results demonstrate that MNN exhibits exceptional generalization performance and training efficiency on four benchmark datasets.
Rethinking Samples Selection for Contrastive Learning: Mining of Potential Samples
Nov 01, 2023



Contrastive learning predicts whether two images belong to the same category by training a model to make their feature representations as close or as far away as possible. In this paper, we rethink how to mine samples in contrastive learning, unlike other methods, our approach is more comprehensive, taking into account both positive and negative samples, and mining potential samples from two aspects: First, for positive samples, we consider both the augmented sample views obtained by data augmentation and the mined sample views through data mining. Then, we weight and combine them using both soft and hard weighting strategies. Second, considering the existence of uninformative negative samples and false negative samples in the negative samples, we analyze the negative samples from the gradient perspective and finally mine negative samples that are neither too hard nor too easy as potential negative samples, i.e., those negative samples that are close to positive samples. The experiments show the obvious advantages of our method compared with some traditional self-supervised methods. Our method achieves 88.57%, 61.10%, and 36.69% top-1 accuracy on CIFAR10, CIFAR100, and TinyImagenet, respectively.
Multi-network Contrastive Learning Based on Global and Local Representations
Jun 28, 2023The popularity of self-supervised learning has made it possible to train models without relying on labeled data, which saves expensive annotation costs. However, most existing self-supervised contrastive learning methods often overlook the combination of global and local feature information. This paper proposes a multi-network contrastive learning framework based on global and local representations. We introduce global and local feature information for self-supervised contrastive learning through multiple networks. The model learns feature information at different scales of an image by contrasting the embedding pairs generated by multiple networks. The framework also expands the number of samples used for contrast and improves the training efficiency of the model. Linear evaluation results on three benchmark datasets show that our method outperforms several existing classical self-supervised learning methods.
MSVQ: Self-Supervised Learning with Multiple Sample Views and Queues
May 09, 2023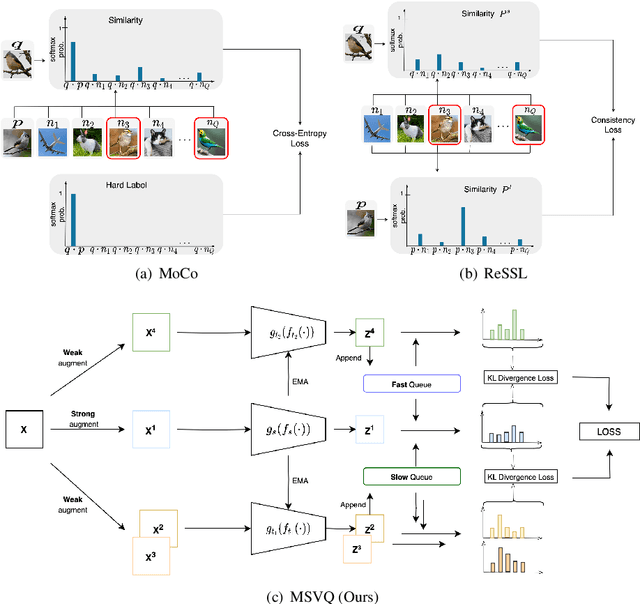
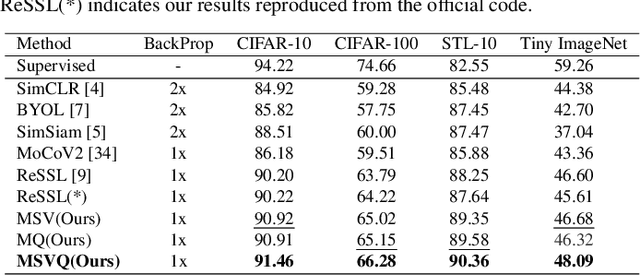
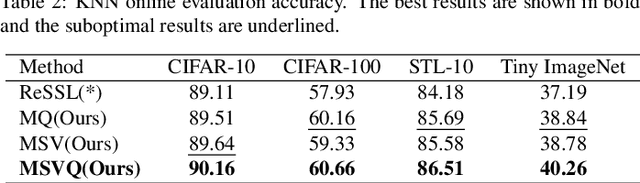
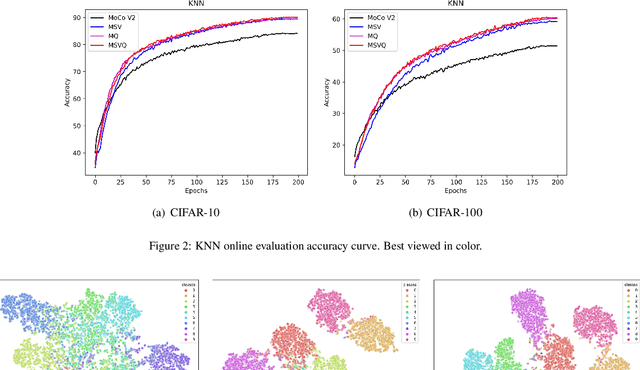
Self-supervised methods based on contrastive learning have achieved great success in unsupervised visual representation learning. However, most methods under this framework suffer from the problem of false negative samples. Inspired by mean shift for self-supervised learning, we propose a new simple framework, namely Multiple Sample Views and Queues (MSVQ). We jointly construct a soft label on-the-fly by introducing two complementary and symmetric ways: multiple augmented positive views and two momentum encoders forming various semantic features of negative samples. Two teacher networks perform similarity relationship calculations with negative samples and then transfer this knowledge to the student. Let the student mimic the similar relationship between the samples, thus giving the student a more flexible ability to identify false negative samples in the dataset. The classification results on four benchmark image datasets demonstrate the high effectiveness and efficiency of our approach compared to some classical methods. Source code and pretrained models are available at $\href{https://github.com/pc-cp/MSVQ}{this~http~URL}$.
Synthetic Hard Negative Samples for Contrastive Learning
Apr 17, 2023



Contrastive learning has emerged as an essential approach for self-supervised learning in visual representation learning. The central objective of contrastive learning is to maximize the similarities between two augmented versions of an image (positive pairs), while minimizing the similarities between different images (negative pairs). Recent studies have demonstrated that harder negative samples, i.e., those that are more difficult to differentiate from the anchor sample, perform a more crucial function in contrastive learning. This paper proposes a novel feature-level method, namely sampling synthetic hard negative samples for contrastive learning (SSCL), to exploit harder negative samples more effectively. Specifically, 1) we generate more and harder negative samples by mixing negative samples, and then sample them by controlling the contrast of anchor sample with the other negative samples; 2) considering the possibility of false negative samples, we further debias the negative samples. Our proposed method improves the classification performance on different image datasets and can be readily integrated into existing methods.