 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSVQ: Self-Supervised Learning with Multiple Sample Views and Queues
Paper and Code
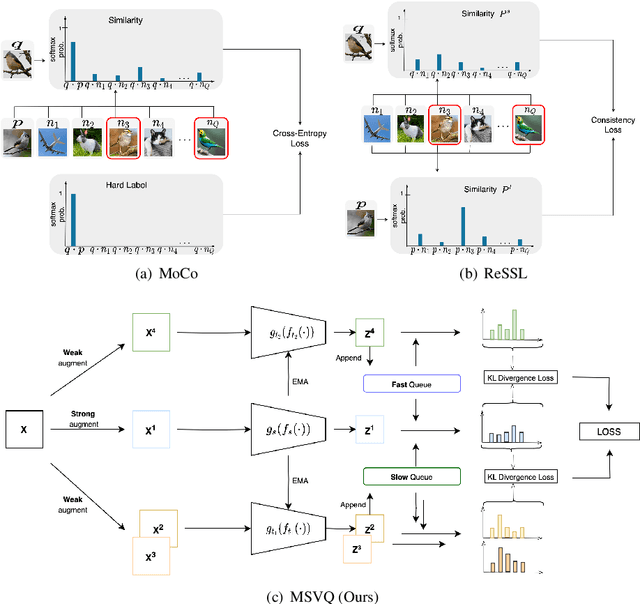
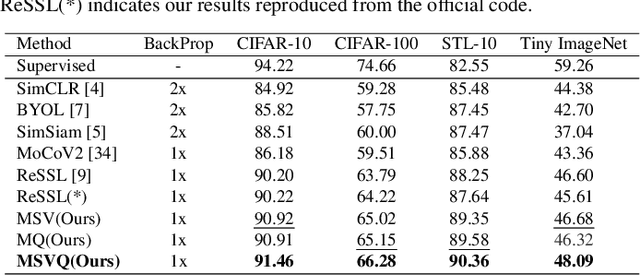
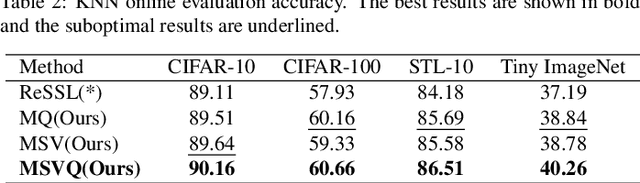
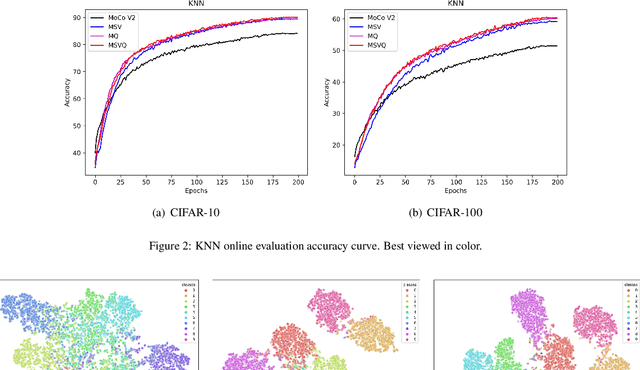
Self-supervised methods based on contrastive learning have achieved great success in unsupervised visual representation learning. However, most methods under this framework suffer from the problem of false negative samples. Inspired by mean shift for self-supervised learning, we propose a new simple framework, namely Multiple Sample Views and Queues (MSVQ). We jointly construct a soft label on-the-fly by introducing two complementary and symmetric ways: multiple augmented positive views and two momentum encoders forming various semantic features of negative samples. Two teacher networks perform similarity relationship calculations with negative samples and then transfer this knowledge to the student. Let the student mimic the similar relationship between the samples, thus giving the student a more flexible ability to identify false negative samples in the dataset. The classification results on four benchmark image datasets demonstrate the high effectiveness and efficiency of our approach compared to some classical methods. Source code and pretrained models are available at $\href{https://github.com/pc-cp/MSVQ}{this~http~URL}$.