 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinutes to Seconds: Speeded-up DDPM-based Image Inpainting with Coarse-to-Fine Sampling
Jul 08, 2024



For image inpainting, the existing Denoising Diffusion Probabilistic Model (DDPM) based method i.e. RePaint can produce high-quality images for any inpainting form. It utilizes a pre-trained DDPM as a prior and generates inpainting results by conditioning on the reverse diffusion process, namely denoising process. However, this process is significantly time-consuming. In this paper, we propose an efficient DDPM-based image inpainting method which includes three speed-up strategies. First, we utilize a pre-trained Light-Weight Diffusion Model (LWDM) to reduce the number of parameters. Second, we introduce a skip-step sampling scheme of Denoising Diffusion Implicit Models (DDIM) for the denoising process. Finally, we propose Coarse-to-Fine Sampling (CFS), which speeds up inference by reducing image resolution in the coarse stage and decreasing denoising timesteps in the refinement stage. We conduct extensive experiments on both faces and general-purpose image inpainting tasks, and our method achieves competitive performance with approximately 60 times speedup.
Iterative Learning for Joint Image Denoising and Motion Artifact Correction of 3D Brain MRI
Mar 13, 2024



Image noise and motion artifacts greatly affect the quality of brain MRI and negatively influence downstream medical image analysis. Previous studies often focus on 2D methods that process each volumetric MR image slice-by-slice, thus losing important 3D anatomical information. Additionally, these studies generally treat image denoising and artifact correction as two standalone tasks, without considering their potential relationship, especially on low-quality images where severe noise and motion artifacts occur simultaneously. To address these issues, we propose a Joint image Denoising and motion Artifact Correction (JDAC) framework via iterative learning to handle noisy MRIs with motion artifacts, consisting of an adaptive denoising model and an anti-artifact model. In the adaptive denoising model, we first design a novel noise level estimation strategy, and then adaptively reduce the noise through a U-Net backbone with feature normalization conditioning on the estimated noise variance. The anti-artifact model employs another U-Net for eliminating motion artifacts, incorporating a novel gradient-based loss function designed to maintain the integrity of brain anatomy during the motion correction process. These two models are iteratively employed for joint image denoising and artifact correction through an iterative learning framework. An early stopping strategy depending on noise level estimation is applied to accelerate the iteration process. The denoising model is trained with 9,544 T1-weighted MRIs with manually added Gaussian noise as supervision. The anti-artifact model is trained on 552 T1-weighted MRIs with motion artifacts and paired motion-free images. Experimental results on a public dataset and a clinical study suggest the effectiveness of JDAC in both tasks of denoising and motion artifact correction, compared with several state-of-the-art methods.
Disentangled Latent Energy-Based Style Translation: An Image-Level Structural MRI Harmonization Framework
Feb 10, 2024



Brain magnetic resonance imaging (MRI) has been extensively employed across clinical and research fields, but often exhibits sensitivity to site effects arising from nonbiological variations such as differences in field strength and scanner vendors. Numerous retrospective MRI harmonization techniques have demonstrated encouraging outcomes in reducing the site effects at image level. However, existing methods generally suffer from high computational requirements and limited generalizability, restricting their applicability to unseen MRIs. In this paper, we design a novel disentangled latent energy-based style translation (DLEST) framework for unpaired image-level MRI harmonization, consisting of (1) site-invariant image generation (SIG), (2) site-specific style translation (SST), and (3) site-specific MRI synthesis (SMS). Specifically, the SIG employs a latent autoencoder to encode MRIs into a low-dimensional latent space and reconstruct MRIs from latent codes. The SST utilizes an energy-based model to comprehend the global latent distribution of a target domain and translate source latent codes toward the target domain, while SMS enables MRI synthesis with a target-specific style. By disentangling image generation and style translation in latent space, the DLEST can achieve efficient style translation. Our model was trained on T1-weighted MRIs from a public dataset (with 3,984 subjects across 58 acquisition sites/settings) and validated on an independent dataset (with 9 traveling subjects scanned in 11 sites/settings) in 4 tasks: (1) histogram and clustering comparison, (2) site classification, (3) brain tissue segmentation, and (4) site-specific MRI synthesis. Qualitative and quantitative results demonstrate the superiority of our method over several state-of-the-arts.
Brain Anatomy Prior Modeling to Forecast Clinical Progression of Cognitive Impairment with Structural MRI
Jun 26, 2023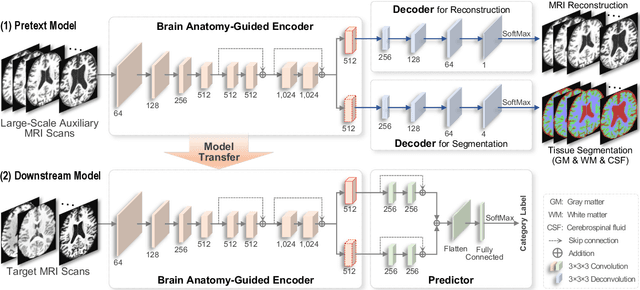

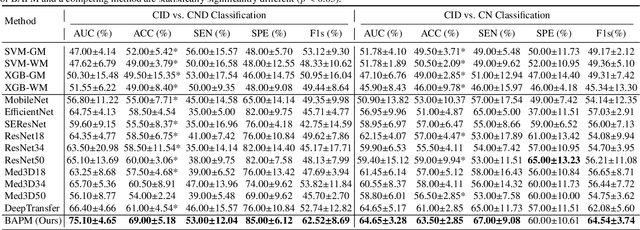
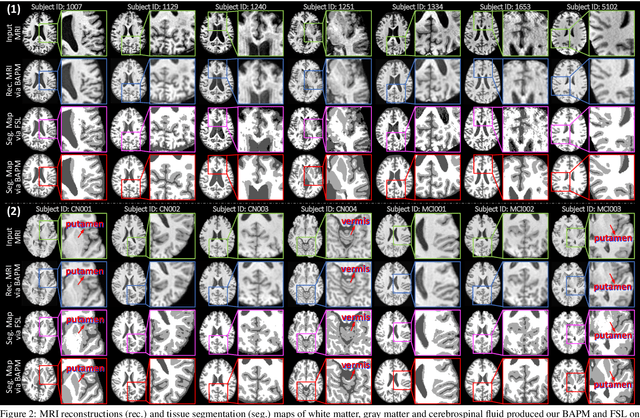
Brain structural MRI has been widely used to assess the future progression of cognitive impairment (CI). Previous learning-based studies usually suffer from the issue of small-sized labeled training data, while there exist a huge amount of structural MRIs in large-scale public databases. Intuitively, brain anatomical structures derived from these public MRIs (even without task-specific label information) can be used to boost CI progression trajectory prediction. However, previous studies seldom take advantage of such brain anatomy prior. To this end, this paper proposes a brain anatomy prior modeling (BAPM) framework to forecast the clinical progression of cognitive impairment with small-sized target MRIs by exploring anatomical brain structures. Specifically, the BAPM consists of a pretext model and a downstream model, with a shared brain anatomy-guided encoder to model brain anatomy prior explicitly. Besides the encoder, the pretext model also contains two decoders for two auxiliary tasks (i.e., MRI reconstruction and brain tissue segmentation), while the downstream model relies on a predictor for classification. The brain anatomy-guided encoder is pre-trained with the pretext model on 9,344 auxiliary MRIs without diagnostic labels for anatomy prior modeling. With this encoder frozen, the downstream model is then fine-tuned on limited target MRIs for prediction. We validate the BAPM on two CI-related studies with T1-weighted MRIs from 448 subjects. Experimental results suggest the effectiveness of BAPM in (1) four CI progression prediction tasks, (2) MR image reconstruction, and (3) brain tissue segmentation, compared with several state-of-the-art methods.
XFL: A High Performace, Lightweighted Federated Learning Framework
Feb 10, 2023



This paper introduces XFL, an industrial-grade federated learning project. XFL supports training AI models collaboratively on multiple devices, while utilizes homomorphic encryption, differential privacy, secure multi-party computation and other security technologies ensuring no leakage of data. XFL provides an abundant algorithms library, integrating a large number of pre-built, secure and outstanding federated learning algorithms, covering both the horizontally and vertically federated learning scenarios. Numerical experiments have shown the prominent performace of these algorithms. XFL builds a concise configuration interfaces with presettings for all federation algorithms, and supports the rapid deployment via docker containers.Therefore, we believe XFL is the most user-friendly and easy-to-develop federated learning framework. XFL is open-sourced, and both the code and documents are available at https://github.com/paritybit-ai/XFL.
SuperScaler: Supporting Flexible DNN Parallelization via a Unified Abstraction
Jan 21, 2023



With the growing model size, deep neural networks (DNN) are increasingly trained over massive GPU accelerators, which demands a proper parallelization plan that transforms a DNN model into fine-grained tasks and then schedules them to GPUs for execution. Due to the large search space, the contemporary parallelization plan generators often rely on empirical rules that couple transformation and scheduling, and fall short in exploring more flexible schedules that yield better memory usage and compute efficiency. This tension can be exacerbated by the emerging models with increasing complexity in their structure and model size. SuperScaler is a system that facilitates the design and generation of highly flexible parallelization plans. It formulates the plan design and generation into three sequential phases explicitly: model transformation, space-time scheduling, and data dependency preserving. Such a principled approach decouples multiple seemingly intertwined factors and enables the composition of highly flexible parallelization plans. As a result, SuperScaler can not only generate empirical parallelization plans, but also construct new plans that achieve up to 3.5X speedup compared to state-of-the-art solutions like DeepSpeed, Megatron and Alpa, for emerging DNN models like Swin-Transformer and AlphaFold2, as well as well-optimized models like GPT-3.
Hybrid Representation Learning for Cognitive Diagnosis in Late-Life Depression Over 5 Years with Structural MRI
Dec 24, 2022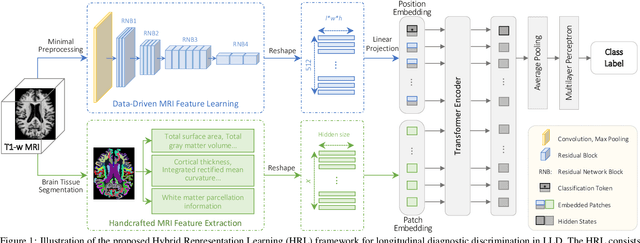
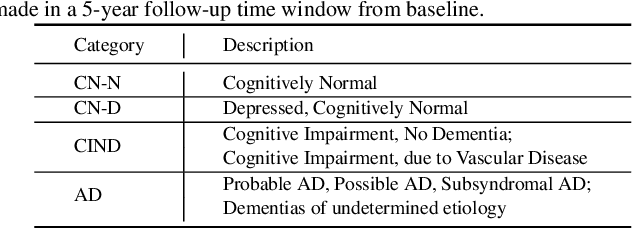
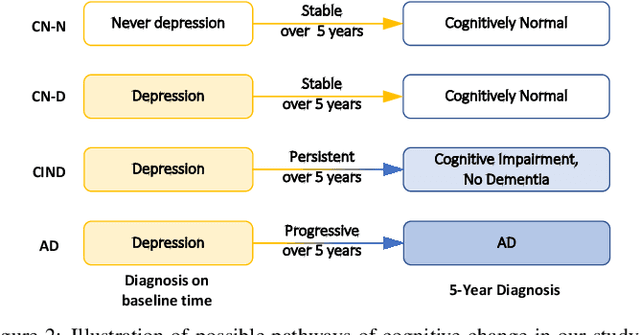
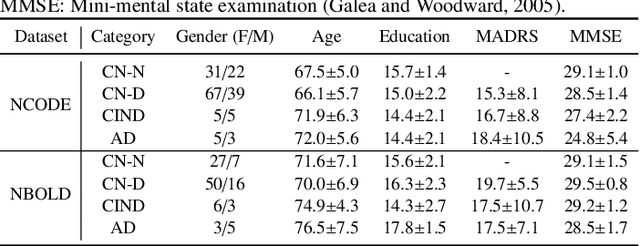
Late-life depression (LLD) is a highly prevalent mood disorder occurring in older adults and is frequently accompanied by cognitive impairment (CI). Studies have shown that LLD may increase the risk of Alzheimer's disease (AD). However, the heterogeneity of presentation of geriatric depression suggests that multiple biological mechanisms may underlie it. Current biological research on LLD progression incorporates machine learning that combines neuroimaging data with clinical observations. There are few studies on incident cognitive diagnostic outcomes in LLD based on structural MRI (sMRI). In this paper, we describe the development of a hybrid representation learning (HRL) framework for predicting cognitive diagnosis over 5 years based on T1-weighted sMRI data. Specifically, we first extract prediction-oriented MRI features via a deep neural network, and then integrate them with handcrafted MRI features via a Transformer encoder for cognitive diagnosis prediction. Two tasks are investigated in this work, including (1) identifying cognitively normal subjects with LLD and never-depressed older healthy subjects, and (2) identifying LLD subjects who developed CI (or even AD) and those who stayed cognitively normal over five years. To the best of our knowledge, this is among the first attempts to study the complex heterogeneous progression of LLD based on task-oriented and handcrafted MRI features. We validate the proposed HRL on 294 subjects with T1-weighted MRIs from two clinically harmonized studies. Experimental results suggest that the HRL outperforms several classical machine learning and state-of-the-art deep learning methods in LLD identification and prediction tasks.
Privacy-Preserving Self-Taught Federated Learning for Heterogeneous Data
Feb 11, 2021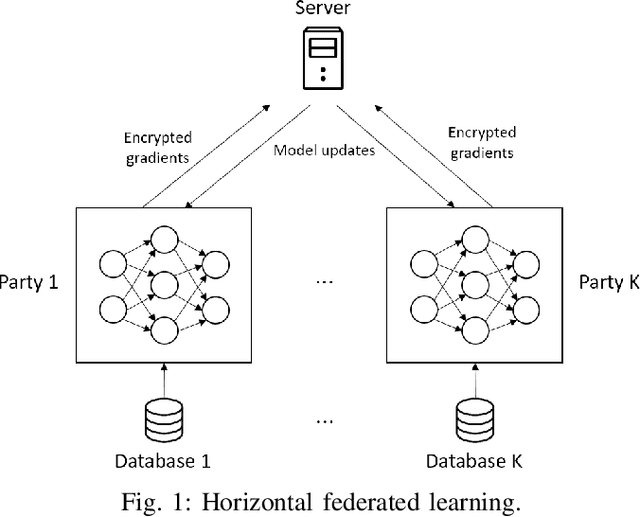
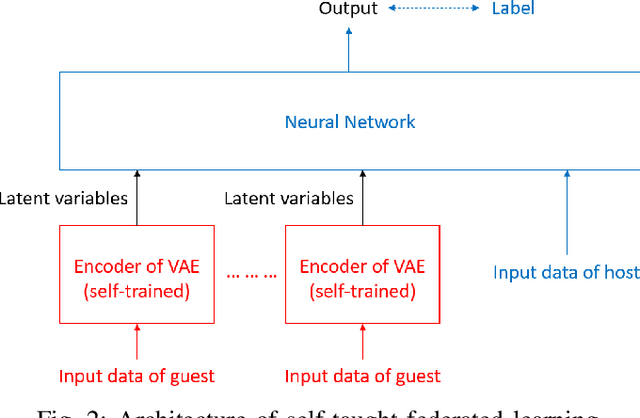
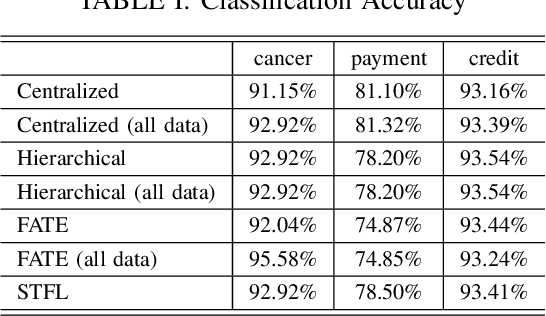
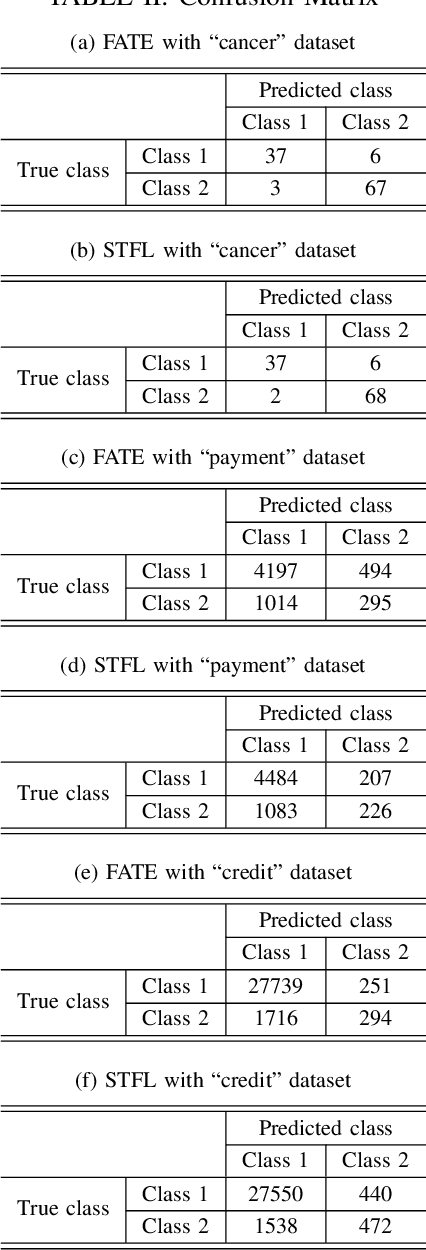
Many application scenarios call for training a machine learning model among multiple participants. Federated learning (FL) was proposed to enable joint training of a deep learning model using the local data in each party without revealing the data to others. Among various types of FL methods, vertical FL is a category to handle data sources with the same ID space and different feature spaces. However, existing vertical FL methods suffer from limitations such as restrictive neural network structure, slow training speed, and often lack the ability to take advantage of data with unmatched IDs. In this work, we propose an FL method called self-taught federated learning to address the aforementioned issues, which uses unsupervised feature extraction techniques for distributed supervised deep learning tasks. In this method, only latent variables are transmitted to other parties for model training, while privacy is preserved by storing the data and parameters of activations, weights, and biases locally. Extensive experiments are performed to evaluate and demonstrate the validity and efficiency of the proposed method.
OpEvo: An Evolutionary Method for Tensor Operator Optimization
Jun 10, 2020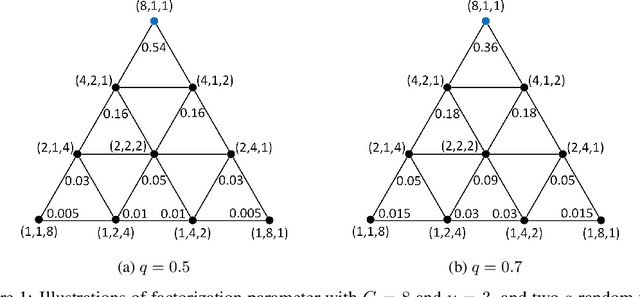
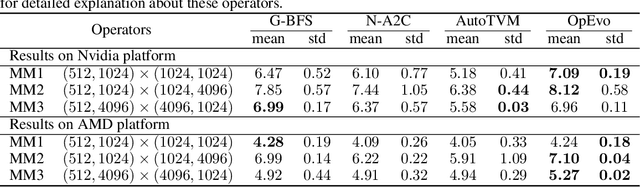
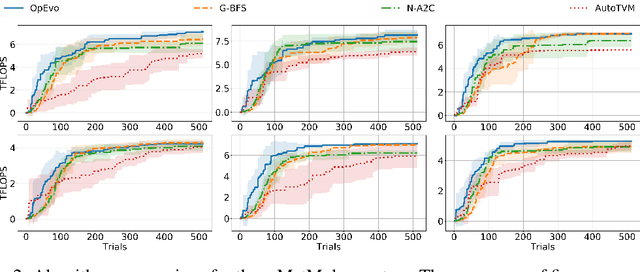
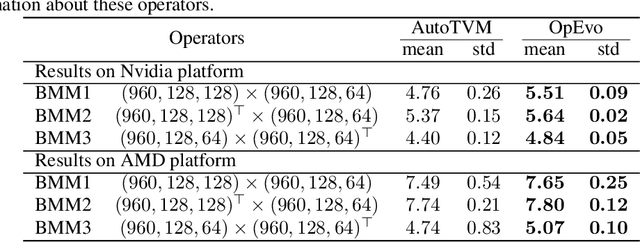
Training and inference efficiency of deep neural networks highly rely on the performance of tensor operators on hardware platforms. Manually optimized tensor operators have limitations in terms of supporting new operators or supporting new hardware platforms. Therefore, automatically optimizing device code configurations of tensor operators is getting increasingly attractive. However, current methods for tensor operator optimization usually suffer from poor sample-efficiency due to the combinatorial search space. In this work, we propose a novel evolutionary method, OpEvo, which efficiently explores the search spaces of tensor operators by introducing a topology-aware mutation operation based on q-random walk distribution to leverage the topological structures over the search spaces. Our comprehensive experiment results show that OpEvo can find the best configuration with the least number of trials and the lowest variance compared with state-of-the-art methods. All code of this work is available online.
RPC Considered Harmful: Fast Distributed Deep Learning on RDMA
May 22, 2018
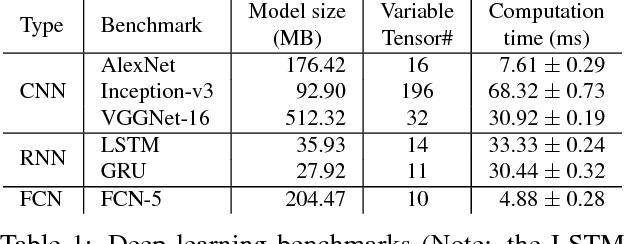
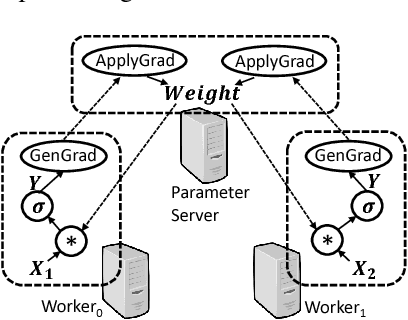

Deep learning emerges as an important new resource-intensive workload and has been successfully applied in computer vision, speech, natural language processing, and so on. Distributed deep learning is becoming a necessity to cope with growing data and model sizes. Its computation is typically characterized by a simple tensor data abstraction to model multi-dimensional matrices, a data-flow graph to model computation, and iterative executions with relatively frequent synchronizations, thereby making it substantially different from Map/Reduce style distributed big data computation. RPC, commonly used as the communication primitive, has been adopted by popular deep learning frameworks such as TensorFlow, which uses gRPC. We show that RPC is sub-optimal for distributed deep learning computation, especially on an RDMA-capable network. The tensor abstraction and data-flow graph, coupled with an RDMA network, offers the opportunity to reduce the unnecessary overhead (e.g., memory copy) without sacrificing programmability and generality. In particular, from a data access point of view, a remote machine is abstracted just as a "device" on an RDMA channel, with a simple memory interface for allocating, reading, and writing memory regions. Our graph analyzer looks at both the data flow graph and the tensors to optimize memory allocation and remote data access using this interface. The result is up to 25 times speedup in representative deep learning benchmarks against the standard gRPC in TensorFlow and up to 169% improvement even against an RPC implementation optimized for RDMA, leading to faster convergence in the training process.