 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Proof Generation for Rust Code via Self-Evolution
Oct 21, 2024



Ensuring correctness is crucial for code generation. Formal verification offers a definitive assurance of correctness, but demands substantial human effort in proof construction and hence raises a pressing need for automation. The primary obstacle lies in the severe lack of data - there is much less proof than code for LLMs to train upon. In this paper, we introduce SAFE, a novel framework that overcomes the lack of human-written proof to enable automated proof generation of Rust code. SAFE establishes a self-evolving cycle where data synthesis and fine-tuning collaborate to enhance the model capability, leveraging the definitive power of a symbolic verifier in telling correct proof from incorrect ones. SAFE also re-purposes the large number of synthesized incorrect proofs to train the self-debugging capability of the fine-tuned models, empowering them to fix incorrect proofs based on the verifier's feedback. SAFE demonstrates superior efficiency and precision compared to GPT-4o. Through tens of thousands of synthesized proofs and the self-debugging mechanism, we improve the capability of open-source models, initially unacquainted with formal verification, to automatically write proof for Rust code. This advancement leads to a significant improvement in performance, achieving a 70.50% accuracy rate in a benchmark crafted by human experts, a significant leap over GPT-4o's performance of 24.46%.
SparDA: Accelerating Dynamic Sparse Deep Neural Networks via Sparse-Dense Transformation
Jan 26, 2023



Due to its high cost-effectiveness, sparsity has become the most important approach for building efficient deep-learning models. However, commodity accelerators are built mainly for efficient dense computation, creating a huge gap for general sparse computation to leverage. Existing solutions have to use time-consuming compiling to improve the efficiency of sparse kernels in an ahead-of-time manner and thus are limited to static sparsity. A wide range of dynamic sparsity opportunities is missed because their sparsity patterns are only known at runtime. This limits the future of building more biological brain-like neural networks that should be dynamically and sparsely activated. In this paper, we bridge the gap between sparse computation and commodity accelerators by proposing a system, called Spider, for efficiently executing deep learning models with dynamic sparsity. We identify an important property called permutation invariant that applies to most deep-learning computations. The property enables Spider (1) to extract dynamic sparsity patterns of tensors that are only known at runtime with little overhead; and (2) to transform the dynamic sparse computation into an equivalent dense computation which has been extremely optimized on commodity accelerators. Extensive evaluation on diverse models shows Spider can extract and transform dynamic sparsity with negligible overhead but brings up to 9.4x speedup over state-of-art solutions.
SuperScaler: Supporting Flexible DNN Parallelization via a Unified Abstraction
Jan 21, 2023



With the growing model size, deep neural networks (DNN) are increasingly trained over massive GPU accelerators, which demands a proper parallelization plan that transforms a DNN model into fine-grained tasks and then schedules them to GPUs for execution. Due to the large search space, the contemporary parallelization plan generators often rely on empirical rules that couple transformation and scheduling, and fall short in exploring more flexible schedules that yield better memory usage and compute efficiency. This tension can be exacerbated by the emerging models with increasing complexity in their structure and model size. SuperScaler is a system that facilitates the design and generation of highly flexible parallelization plans. It formulates the plan design and generation into three sequential phases explicitly: model transformation, space-time scheduling, and data dependency preserving. Such a principled approach decouples multiple seemingly intertwined factors and enables the composition of highly flexible parallelization plans. As a result, SuperScaler can not only generate empirical parallelization plans, but also construct new plans that achieve up to 3.5X speedup compared to state-of-the-art solutions like DeepSpeed, Megatron and Alpa, for emerging DNN models like Swin-Transformer and AlphaFold2, as well as well-optimized models like GPT-3.
CodeXGLUE: A Machine Learning Benchmark Dataset for Code Understanding and Generation
Feb 09, 2021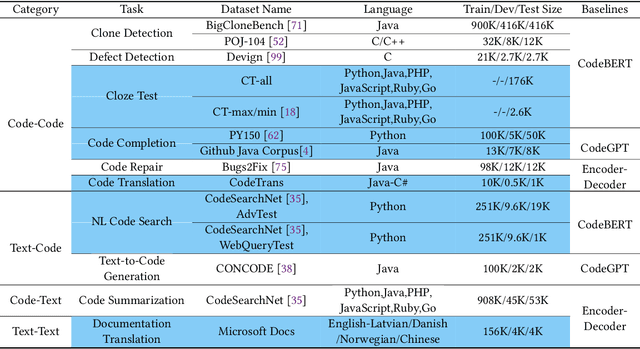

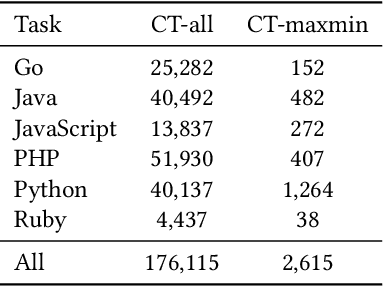

Benchmark datasets have a significant impact on accelerating research in programming language tasks. In this paper, we introduce CodeXGLUE, a benchmark dataset to foster machine learning research for program understanding and generation. CodeXGLUE includes a collection of 10 tasks across 14 datasets and a platform for model evaluation and comparison. CodeXGLUE also features three baseline systems, including the BERT-style, GPT-style, and Encoder-Decoder models, to make it easy for researchers to use the platform. The availability of such data and baselines can help the development and validation of new methods that can be applied to various program understanding and generation problems.
LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding
Dec 29, 2020
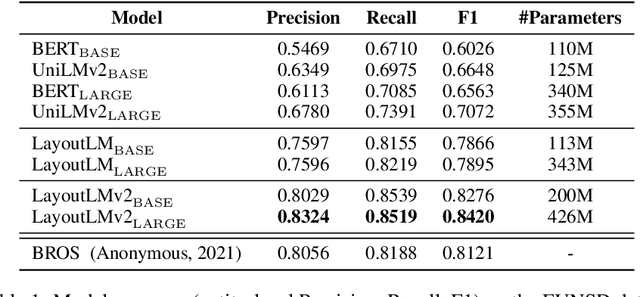
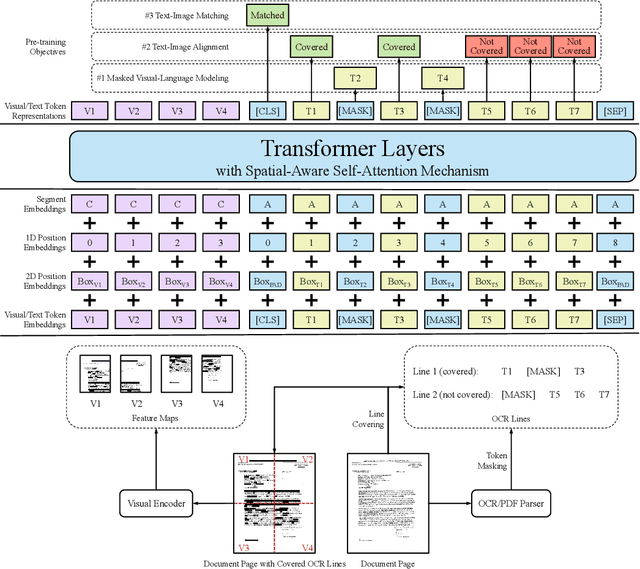
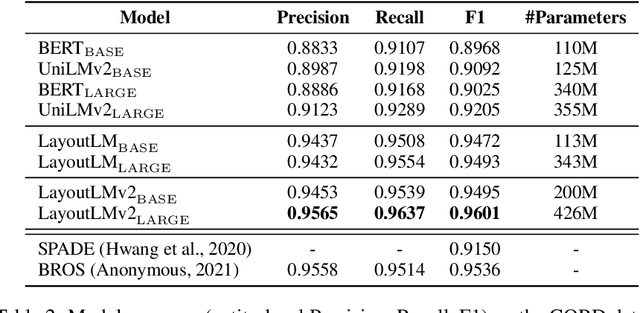
Pre-training of text and layout has proved effective in a variety of visually-rich document understanding tasks due to its effective model architecture and the advantage of large-scale unlabeled scanned/digital-born documents. In this paper, we present \textbf{LayoutLMv2} by pre-training text, layout and image in a multi-modal framework, where new model architectures and pre-training tasks are leveraged. Specifically, LayoutLMv2 not only uses the existing masked visual-language modeling task but also the new text-image alignment and text-image matching tasks in the pre-training stage, where cross-modality interaction is better learned. Meanwhile, it also integrates a spatial-aware self-attention mechanism into the Transformer architecture, so that the model can fully understand the relative positional relationship among different text blocks. Experiment results show that LayoutLMv2 outperforms strong baselines and achieves new state-of-the-art results on a wide variety of downstream visually-rich document understanding tasks, including FUNSD (0.7895 -> 0.8420), CORD (0.9493 -> 0.9601), SROIE (0.9524 -> 0.9781), Kleister-NDA (0.834 -> 0.852), RVL-CDIP (0.9443 -> 0.9564), and DocVQA (0.7295 -> 0.8672).
TextNAS: A Neural Architecture Search Space tailored for Text Representation
Dec 23, 2019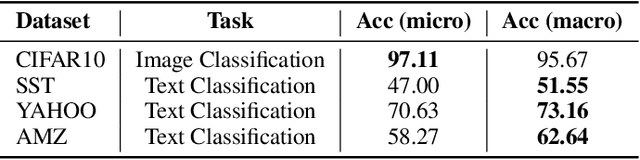


Learning text representation is crucial for text classification and other language related tasks. There are a diverse set of text representation networks in the literature, and how to find the optimal one is a non-trivial problem. Recently, the emerging Neural Architecture Search (NAS) techniques have demonstrated good potential to solve the problem. Nevertheless, most of the existing works of NAS focus on the search algorithms and pay little attention to the search space. In this paper, we argue that the search space is also an important human prior to the success of NAS in different applications. Thus, we propose a novel search space tailored for text representation. Through automatic search, the discovered network architecture outperforms state-of-the-art models on various public datasets on text classification and natural language inference tasks. Furthermore, some of the design principles found in the automatic network agree well with human intuition.
Towards Efficient Large-Scale Graph Neural Network Computing
Oct 19, 2018
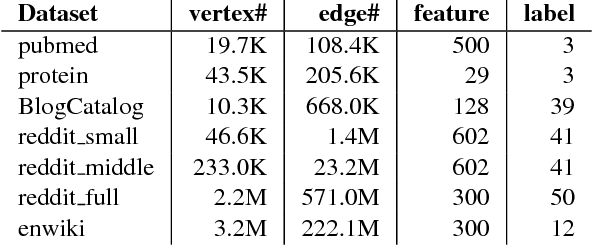

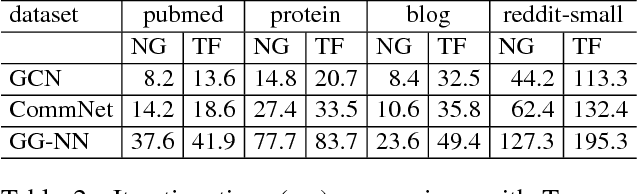
Recent deep learning models have moved beyond low-dimensional regular grids such as image, video, and speech, to high-dimensional graph-structured data, such as social networks, brain connections, and knowledge graphs. This evolution has led to large graph-based irregular and sparse models that go beyond what existing deep learning frameworks are designed for. Further, these models are not easily amenable to efficient, at scale, acceleration on parallel hardwares (e.g. GPUs). We introduce NGra, the first parallel processing framework for graph-based deep neural networks (GNNs). NGra presents a new SAGA-NN model for expressing deep neural networks as vertex programs with each layer in well-defined (Scatter, ApplyEdge, Gather, ApplyVertex) graph operation stages. This model not only allows GNNs to be expressed intuitively, but also facilitates the mapping to an efficient dataflow representation. NGra addresses the scalability challenge transparently through automatic graph partitioning and chunk-based stream processing out of GPU core or over multiple GPUs, which carefully considers data locality, data movement, and overlapping of parallel processing and data movement. NGra further achieves efficiency through highly optimized Scatter/Gather operators on GPUs despite its sparsity. Our evaluation shows that NGra scales to large real graphs that none of the existing frameworks can handle directly, while achieving up to about 4 times speedup even at small scales over the multiple-baseline design on TensorFlow.
RPC Considered Harmful: Fast Distributed Deep Learning on RDMA
May 22, 2018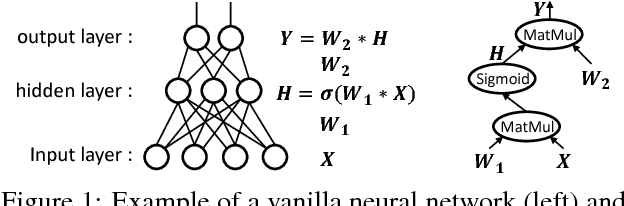
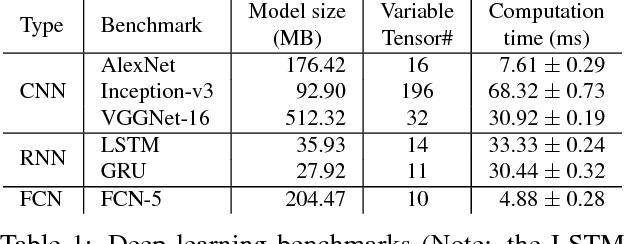
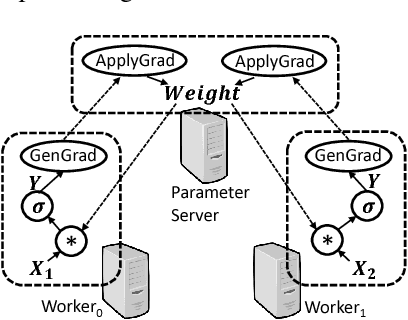

Deep learning emerges as an important new resource-intensive workload and has been successfully applied in computer vision, speech, natural language processing, and so on. Distributed deep learning is becoming a necessity to cope with growing data and model sizes. Its computation is typically characterized by a simple tensor data abstraction to model multi-dimensional matrices, a data-flow graph to model computation, and iterative executions with relatively frequent synchronizations, thereby making it substantially different from Map/Reduce style distributed big data computation. RPC, commonly used as the communication primitive, has been adopted by popular deep learning frameworks such as TensorFlow, which uses gRPC. We show that RPC is sub-optimal for distributed deep learning computation, especially on an RDMA-capable network. The tensor abstraction and data-flow graph, coupled with an RDMA network, offers the opportunity to reduce the unnecessary overhead (e.g., memory copy) without sacrificing programmability and generality. In particular, from a data access point of view, a remote machine is abstracted just as a "device" on an RDMA channel, with a simple memory interface for allocating, reading, and writing memory regions. Our graph analyzer looks at both the data flow graph and the tensors to optimize memory allocation and remote data access using this interface. The result is up to 25 times speedup in representative deep learning benchmarks against the standard gRPC in TensorFlow and up to 169% improvement even against an RPC implementation optimized for RDMA, leading to faster convergence in the training process.