 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJointly Learning to Repair Code and Generate Commit Message
Sep 25, 2021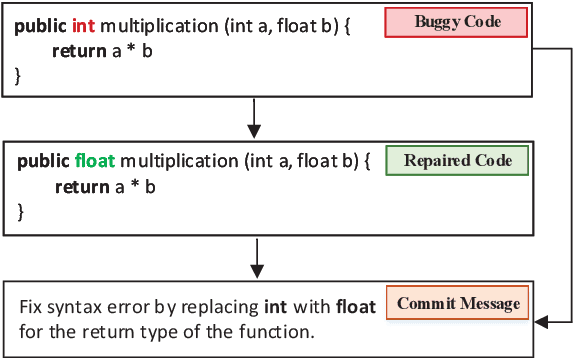
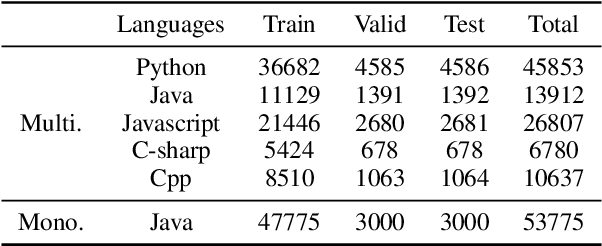
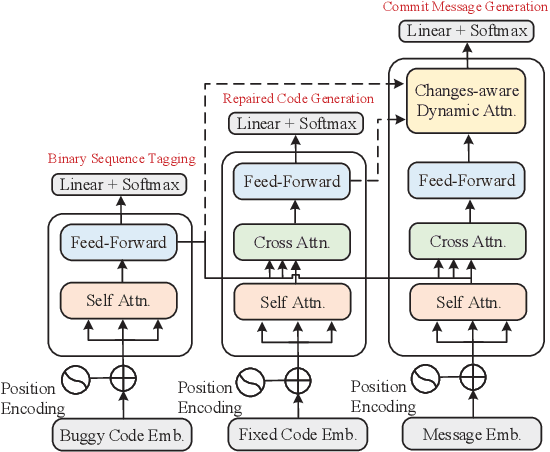
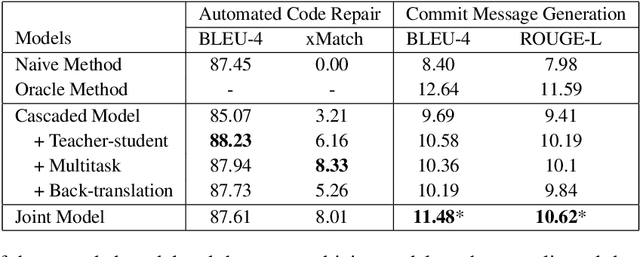
We propose a novel task of jointly repairing program codes and generating commit messages. Code repair and commit message generation are two essential and related tasks for software development. However, existing work usually performs the two tasks independently. We construct a multilingual triple dataset including buggy code, fixed code, and commit messages for this novel task. We provide the cascaded models as baseline, which are enhanced with different training approaches, including the teacher-student method, the multi-task method, and the back-translation method. To deal with the error propagation problem of the cascaded method, the joint model is proposed that can both repair the code and generate the commit message in a unified framework. Experimental results show that the enhanced cascaded model with teacher-student method and multitask-learning method achieves the best score on different metrics of automated code repair, and the joint model behaves better than the cascaded model on commit message generation.
CodeXGLUE: A Machine Learning Benchmark Dataset for Code Understanding and Generation
Feb 09, 2021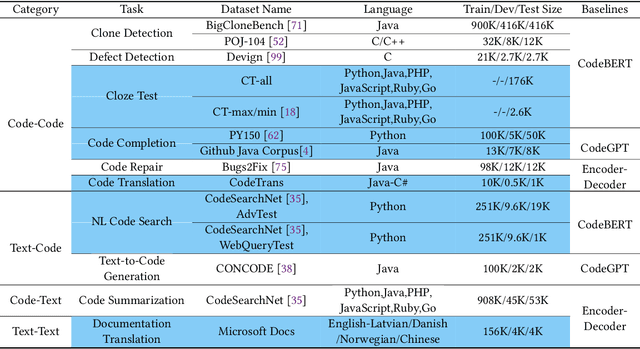

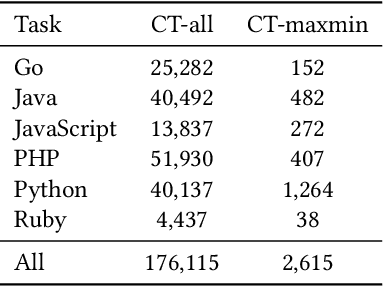

Benchmark datasets have a significant impact on accelerating research in programming language tasks. In this paper, we introduce CodeXGLUE, a benchmark dataset to foster machine learning research for program understanding and generation. CodeXGLUE includes a collection of 10 tasks across 14 datasets and a platform for model evaluation and comparison. CodeXGLUE also features three baseline systems, including the BERT-style, GPT-style, and Encoder-Decoder models, to make it easy for researchers to use the platform. The availability of such data and baselines can help the development and validation of new methods that can be applied to various program understanding and generation problems.
CodeBLEU: a Method for Automatic Evaluation of Code Synthesis
Sep 27, 2020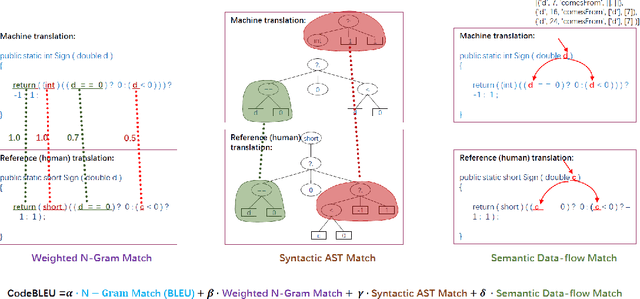


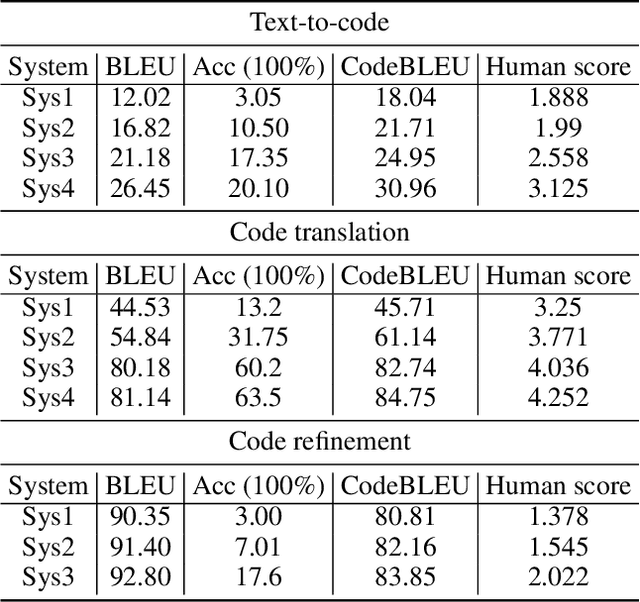
Evaluation metrics play a vital role in the growth of an area as it defines the standard of distinguishing between good and bad models. In the area of code synthesis, the commonly used evaluation metric is BLEU or perfect accuracy, but they are not suitable enough to evaluate codes, because BLEU is originally designed to evaluate the natural language, neglecting important syntactic and semantic features of codes, and perfect accuracy is too strict thus it underestimates different outputs with the same semantic logic. To remedy this, we introduce a new automatic evaluation metric, dubbed CodeBLEU. It absorbs the strength of BLEU in the n-gram match and further injects code syntax via abstract syntax trees (AST) and code semantics via data-flow. We conduct experiments by evaluating the correlation coefficient between CodeBLEU and quality scores assigned by the programmers on three code synthesis tasks, i.e., text-to-code, code translation, and code refinement. Experimental results show that our proposed CodeBLEU can achieve a better correlation with programmer assigned scores compared with BLEU and accuracy.
Representing a Partially Observed Non-Rigid 3D Human Using Eigen-Texture and Eigen-Deformation
Jul 07, 2018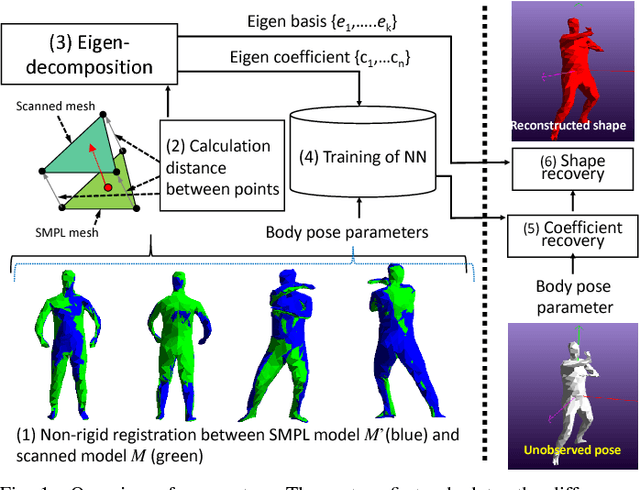
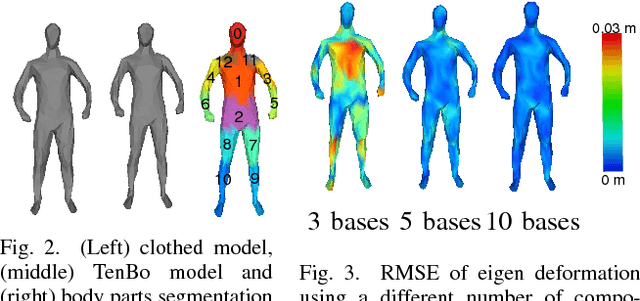
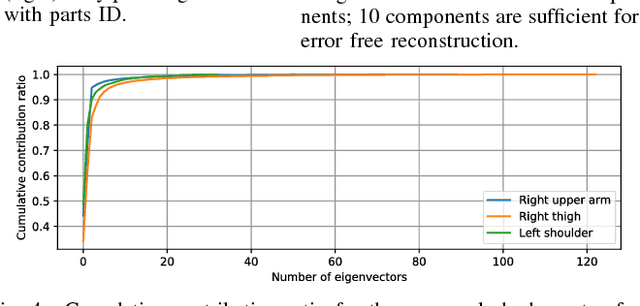

Reconstruction of the shape and motion of humans from RGB-D is a challenging problem, receiving much attention in recent years. Recent approaches for full-body reconstruction use a statistic shape model, which is built upon accurate full-body scans of people in skin-tight clothes, to complete invisible parts due to occlusion. Such a statistic model may still be fit to an RGB-D measurement with loose clothes but cannot describe its deformations, such as clothing wrinkles. Observed surfaces may be reconstructed precisely from actual measurements, while we have no cues for unobserved surfaces. For full-body reconstruction with loose clothes, we propose to use lower dimensional embeddings of texture and deformation referred to as eigen-texturing and eigen-deformation, to reproduce views of even unobserved surfaces. Provided a full-body reconstruction from a sequence of partial measurements as 3D meshes, the texture and deformation of each triangle are then embedded using eigen-decomposition. Combined with neural-network-based coefficient regression, our method synthesizes the texture and deformation from arbitrary viewpoints. We evaluate our method using simulated data and visually demonstrate how our method works on real data.