 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Active Structure-from-Motion in Dark and Textureless Environment
Oct 20, 2024



Active 3D measurement, especially structured light (SL) has been widely used in various fields for its robustness against textureless or equivalent surfaces by low light illumination. In addition, reconstruction of large scenes by moving the SL system has become popular, however, there have been few practical techniques to obtain the system's precise pose information only from images, since most conventional techniques are based on image features, which cannot be retrieved under textureless environments. In this paper, we propose a simultaneous shape reconstruction and pose estimation technique for SL systems from an image set where sparsely projected patterns onto the scene are observed (i.e. no scene texture information), which we call Active SfM. To achieve this, we propose a full optimization framework of the volumetric shape that employs neural signed distance fields (Neural-SDF) for SL with the goal of not only reconstructing the scene shape but also estimating the poses for each motion of the system. Experimental results show that the proposed method is able to achieve accurate shape reconstruction as well as pose estimation from images where only projected patterns are observed.
ActiveNeuS: Neural Signed Distance Fields for Active Stereo
Oct 20, 2024



3D-shape reconstruction in extreme environments, such as low illumination or scattering condition, has been an open problem and intensively researched. Active stereo is one of potential solution for such environments for its robustness and high accuracy. However, active stereo systems usually consist of specialized system configurations with complicated algorithms, which narrow their application. In this paper, we propose Neural Signed Distance Field for active stereo systems to enable implicit correspondence search and triangulation in generalized Structured Light. With our technique, textureless or equivalent surfaces by low light condition are successfully reconstructed even with a small number of captured images. Experiments were conducted to confirm that the proposed method could achieve state-of-the-art reconstruction quality under such severe condition. We also demonstrated that the proposed method worked in an underwater scenario.
Depth Reconstruction with Neural Signed Distance Fields in Structured Light Systems
May 20, 2024



We introduce a novel depth estimation technique for multi-frame structured light setups using neural implicit representations of 3D space. Our approach employs a neural signed distance field (SDF), trained through self-supervised differentiable rendering. Unlike passive vision, where joint estimation of radiance and geometry fields is necessary, we capitalize on known radiance fields from projected patterns in structured light systems. This enables isolated optimization of the geometry field, ensuring convergence and network efficacy with fixed device positioning. To enhance geometric fidelity, we incorporate an additional color loss based on object surfaces during training. Real-world experiments demonstrate our method's superiority in geometric performance for few-shot scenarios, while achieving comparable results with increased pattern availability.
TIDE: Temporally Incremental Disparity Estimation via Pattern Flow in Structured Light System
Oct 13, 2023We introduced Temporally Incremental Disparity Estimation Network (TIDE-Net), a learning-based technique for disparity computation in mono-camera structured light systems. In our hardware setting, a static pattern is projected onto a dynamic scene and captured by a monocular camera. Different from most former disparity estimation methods that operate in a frame-wise manner, our network acquires disparity maps in a temporally incremental way. Specifically, We exploit the deformation of projected patterns (named pattern flow ) on captured image sequences, to model the temporal information. Notably, this newly proposed pattern flow formulation reflects the disparity changes along the epipolar line, which is a special form of optical flow. Tailored for pattern flow, the TIDE-Net, a recurrent architecture, is proposed and implemented. For each incoming frame, our model fuses correlation volumes (from current frame) and disparity (from former frame) warped by pattern flow. From fused features, the final stage of TIDE-Net estimates the residual disparity rather than the full disparity, as conducted by many previous methods. Interestingly, this design brings clear empirical advantages in terms of efficiency and generalization ability. Using only synthetic data for training, our extensitve evaluation results (w.r.t. both accuracy and efficienty metrics) show superior performance than several SOTA models on unseen real data. The code is available on https://github.com/CodePointer/TIDENet.
Online Adaptive Disparity Estimation for Dynamic Scenes in Structured Light Systems
Oct 13, 2023



In recent years, deep neural networks have shown remarkable progress in dense disparity estimation from dynamic scenes in monocular structured light systems. However, their performance significantly drops when applied in unseen environments. To address this issue, self-supervised online adaptation has been proposed as a solution to bridge this performance gap. Unlike traditional fine-tuning processes, online adaptation performs test-time optimization to adapt networks to new domains. Therefore, achieving fast convergence during the adaptation process is critical for attaining satisfactory accuracy. In this paper, we propose an unsupervised loss function based on long sequential inputs. It ensures better gradient directions and faster convergence. Our loss function is designed using a multi-frame pattern flow, which comprises a set of sparse trajectories of the projected pattern along the sequence. We estimate the sparse pseudo ground truth with a confidence mask using a filter-based method, which guides the online adaptation process. Our proposed framework significantly improves the online adaptation speed and achieves superior performance on unseen data.
Generalization of pixel-wise phase estimation by CNN and improvement of phase-unwrapping by MRF optimization for one-shot 3D scan
Sep 26, 2023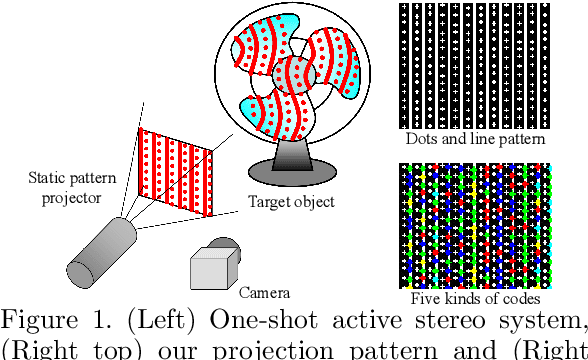

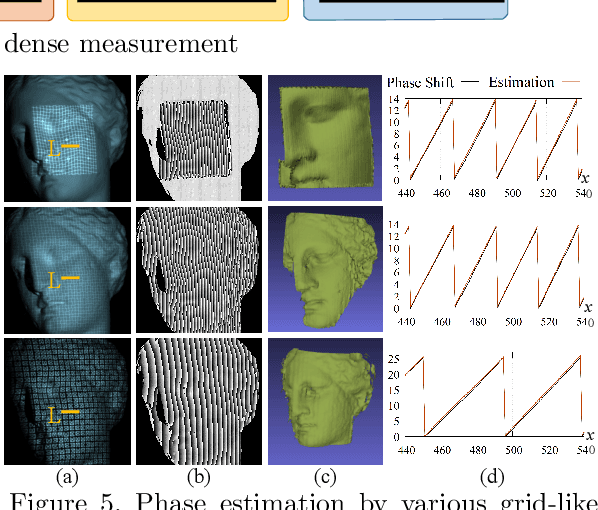
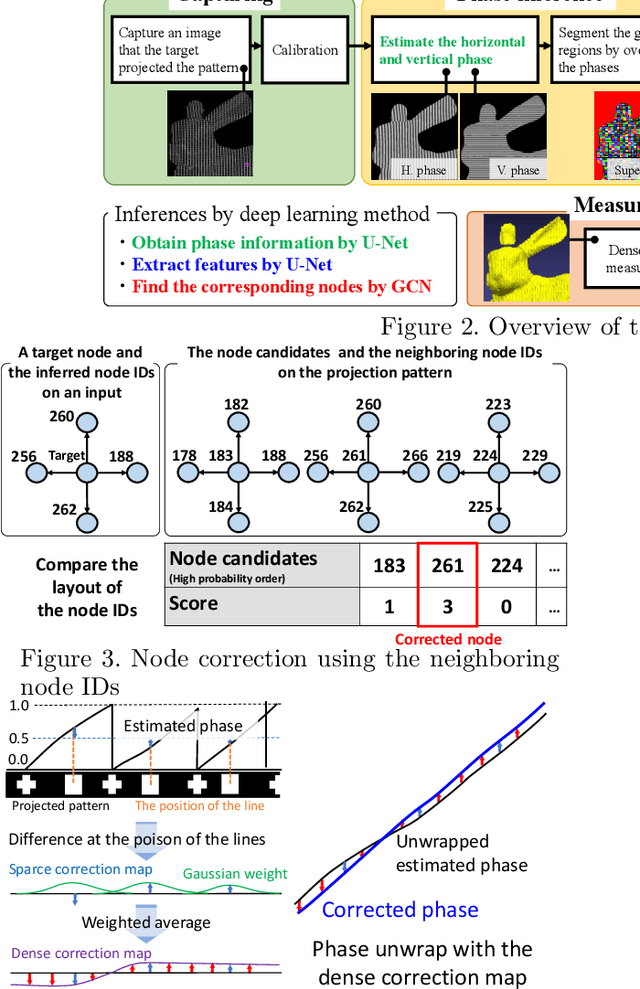
Active stereo technique using single pattern projection, a.k.a. one-shot 3D scan, have drawn a wide attention from industry, medical purposes, etc. One severe drawback of one-shot 3D scan is sparse reconstruction. In addition, since spatial pattern becomes complicated for the purpose of efficient embedding, it is easily affected by noise, which results in unstable decoding. To solve the problems, we propose a pixel-wise interpolation technique for one-shot scan, which is applicable to any types of static pattern if the pattern is regular and periodic. This is achieved by U-net which is pre-trained by CG with efficient data augmentation algorithm. In the paper, to further overcome the decoding instability, we propose a robust correspondence finding algorithm based on Markov random field (MRF) optimization. We also propose a shape refinement algorithm based on b-spline and Gaussian kernel interpolation using explicitly detected laser curves. Experiments are conducted to show the effectiveness of the proposed method using real data with strong noises and textures.
Underwater Image Enhancement by Transformer-based Diffusion Model with Non-uniform Sampling for Skip Strategy
Sep 07, 2023



In this paper, we present an approach to image enhancement with diffusion model in underwater scenes. Our method adapts conditional denoising diffusion probabilistic models to generate the corresponding enhanced images by using the underwater images and the Gaussian noise as the inputs. Additionally, in order to improve the efficiency of the reverse process in the diffusion model, we adopt two different ways. We firstly propose a lightweight transformer-based denoising network, which can effectively promote the time of network forward per iteration. On the other hand, we introduce a skip sampling strategy to reduce the number of iterations. Besides, based on the skip sampling strategy, we propose two different non-uniform sampling methods for the sequence of the time step, namely piecewise sampling and searching with the evolutionary algorithm. Both of them are effective and can further improve performance by using the same steps against the previous uniform sampling. In the end, we conduct a relative evaluation of the widely used underwater enhancement datasets between the recent state-of-the-art methods and the proposed approach. The experimental results prove that our approach can achieve both competitive performance and high efficiency. Our code is available at \href{mailto:https://github.com/piggy2009/DM_underwater}{\color{blue}{https://github.com/piggy2009/DM\_underwater}}.
Deep Gesture Generation for Social Robots Using Type-Specific Libraries
Oct 13, 2022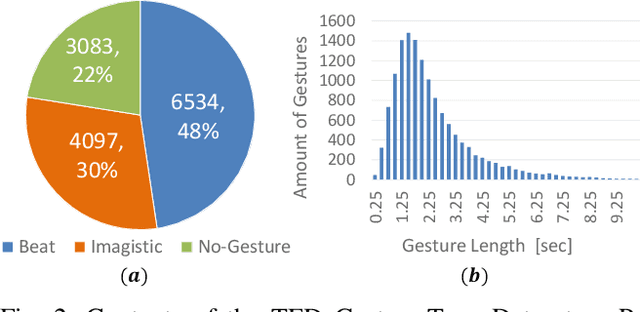
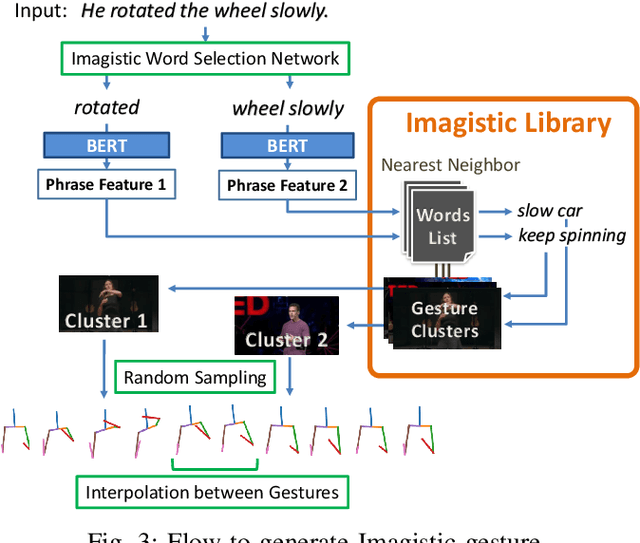
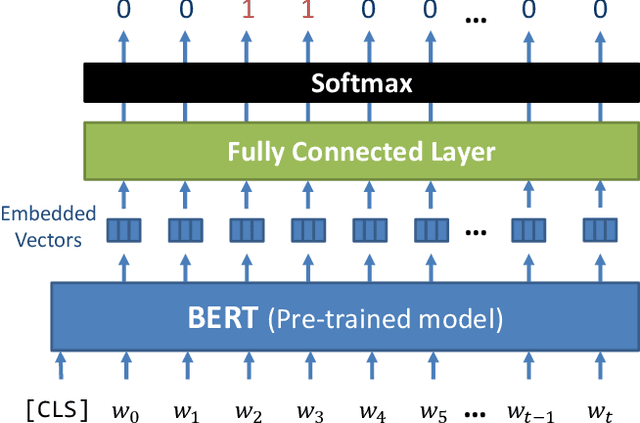
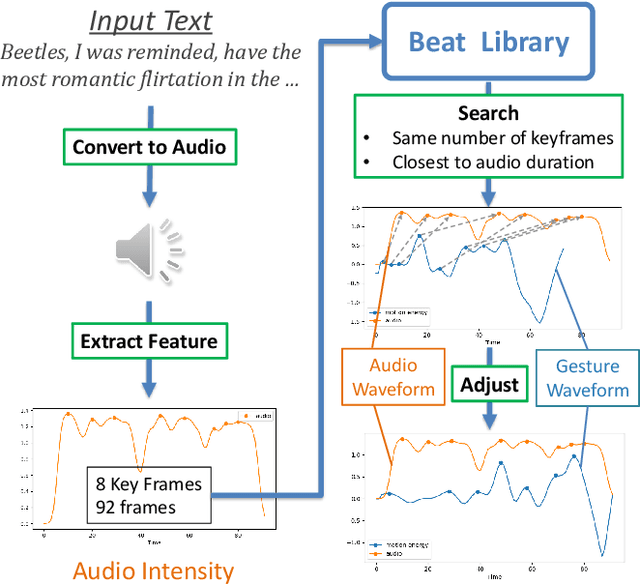
Body language such as conversational gesture is a powerful way to ease communication. Conversational gestures do not only make a speech more lively but also contain semantic meaning that helps to stress important information in the discussion. In the field of robotics, giving conversational agents (humanoid robots or virtual avatars) the ability to properly use gestures is critical, yet remain a task of extraordinary difficulty. This is because given only a text as input, there are many possibilities and ambiguities to generate an appropriate gesture. Different to previous works we propose a new method that explicitly takes into account the gesture types to reduce these ambiguities and generate human-like conversational gestures. Key to our proposed system is a new gesture database built on the TED dataset that allows us to map a word to one of three types of gestures: "Imagistic" gestures, which express the content of the speech, "Beat" gestures, which emphasize words, and "No gestures." We propose a system that first maps the words in the input text to their corresponding gesture type, generate type-specific gestures and combine the generated gestures into one final smooth gesture. In our comparative experiments, the effectiveness of the proposed method was confirmed in user studies for both avatar and humanoid robot.
MOTSLAM: MOT-assisted monocular dynamic SLAM using single-view depth estimation
Oct 05, 2022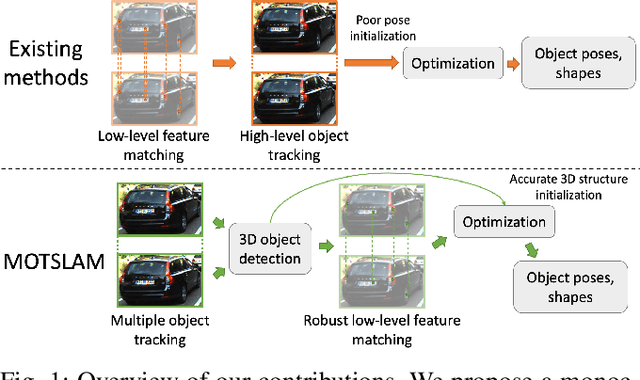
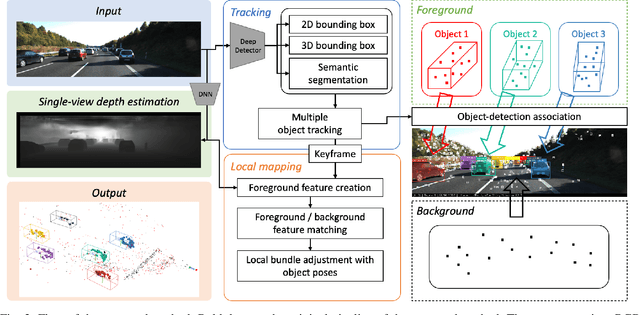

Visual SLAM systems targeting static scenes have been developed with satisfactory accuracy and robustness. Dynamic 3D object tracking has then become a significant capability in visual SLAM with the requirement of understanding dynamic surroundings in various scenarios including autonomous driving, augmented and virtual reality. However, performing dynamic SLAM solely with monocular images remains a challenging problem due to the difficulty of associating dynamic features and estimating their positions. In this paper, we present MOTSLAM, a dynamic visual SLAM system with the monocular configuration that tracks both poses and bounding boxes of dynamic objects. MOTSLAM first performs multiple object tracking (MOT) with associated both 2D and 3D bounding box detection to create initial 3D objects. Then, neural-network-based monocular depth estimation is applied to fetch the depth of dynamic features. Finally, camera poses, object poses, and both static, as well as dynamic map points, are jointly optimized using a novel bundle adjustment. Our experiments on the KITTI dataset demonstrate that our system has reached best performance on both camera ego-motion and object tracking on monocular dynamic SLAM.
A Method For Adding Motion-Blur on Arbitrary Objects By using Auto-Segmentation and Color Compensation Techniques
Sep 22, 2021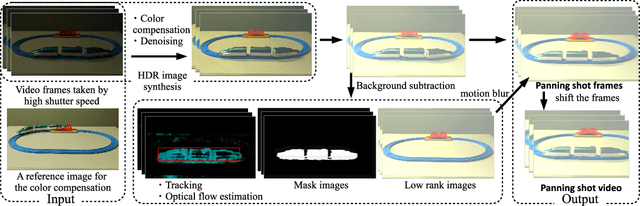
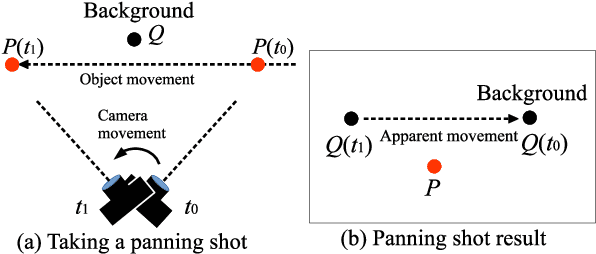


When dynamic objects are captured by a camera, motion blur inevitably occurs. Such a blur is sometimes considered as just a noise, however, it sometimes gives an important effect to add dynamism in the scene for photographs or videos. Unlike the similar effects, such as defocus blur, which is now easily controlled even by smartphones, motion blur is still uncontrollable and makes undesired effects on photographs. In this paper, an unified framework to add motion blur on per-object basis is proposed. In the method, multiple frames are captured without motion blur and they are accumulated to create motion blur on target objects. To capture images without motion blur, shutter speed must be short, however, it makes captured images dark, and thus, a sensor gain should be increased to compensate it. Since a sensor gain causes a severe noise on image, we propose a color compensation algorithm based on non-linear filtering technique for solution. Another contribution is that our technique can be used to make HDR images for fast moving objects by using multi-exposure images. In the experiments, effectiveness of the method is confirmed by ablation study using several data sets.
* This paper was accepted at ICIP 2021