 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEndoAgent: A Memory-Guided Reflective Agent for Intelligent Endoscopic Vision-to-Decision Reasoning
Aug 10, 2025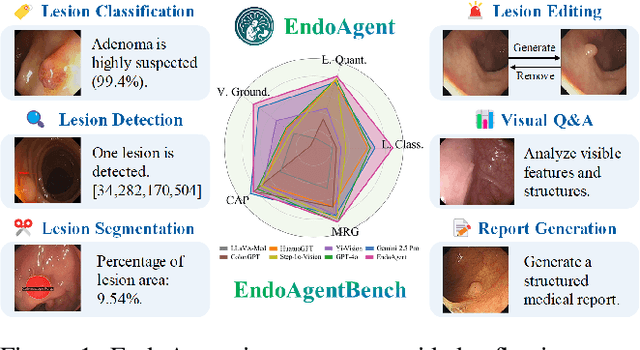
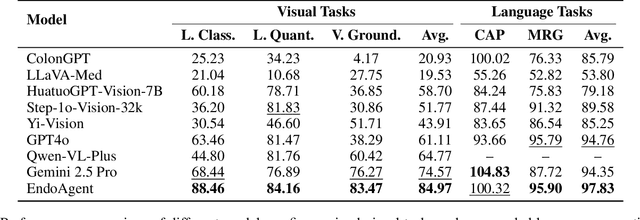
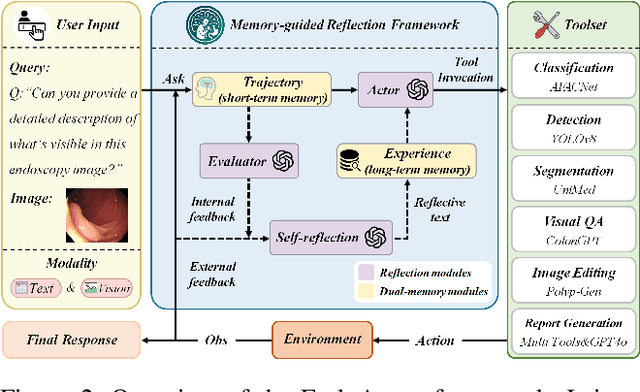

Developing general artificial intelligence (AI) systems to support endoscopic image diagnosis is an emerging research priority. Existing methods based on large-scale pretraining often lack unified coordination across tasks and struggle to handle the multi-step processes required in complex clinical workflows. While AI agents have shown promise in flexible instruction parsing and tool integration across domains, their potential in endoscopy remains underexplored. To address this gap, we propose EndoAgent, the first memory-guided agent for vision-to-decision endoscopic analysis that integrates iterative reasoning with adaptive tool selection and collaboration. Built on a dual-memory design, it enables sophisticated decision-making by ensuring logical coherence through short-term action tracking and progressively enhancing reasoning acuity through long-term experiential learning. To support diverse clinical tasks, EndoAgent integrates a suite of expert-designed tools within a unified reasoning loop. We further introduce EndoAgentBench, a benchmark of 5,709 visual question-answer pairs that assess visual understanding and language generation capabilities in realistic scenarios. Extensive experiments show that EndoAgent consistently outperforms both general and medical multimodal models, exhibiting its strong flexibility and reasoning capabilities.
Improve Decoding Factuality by Token-wise Cross Layer Entropy of Large Language Models
Feb 05, 2025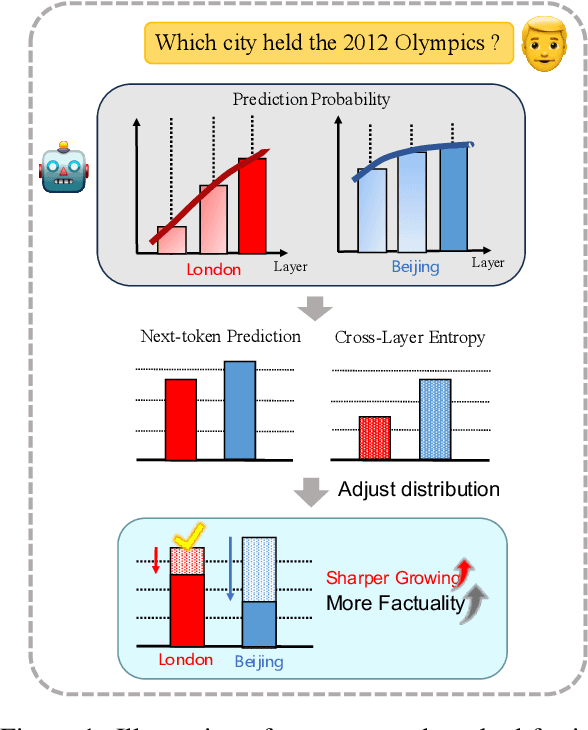
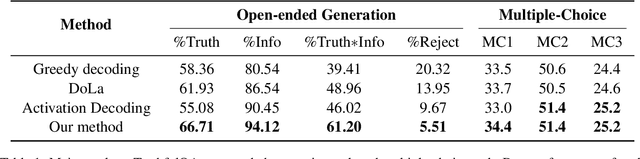
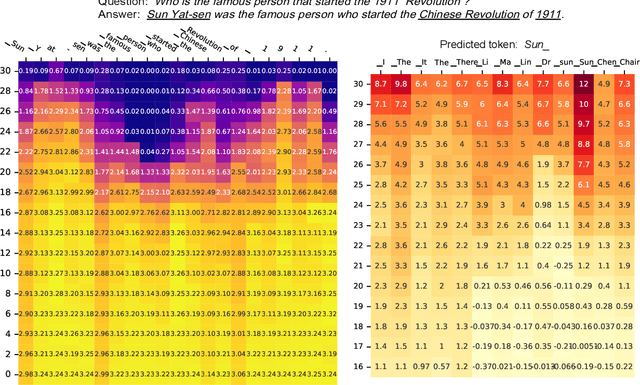
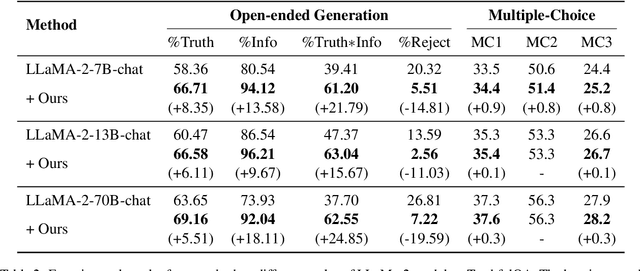
Despite their impressive capacities, Large language models (LLMs) often struggle with the hallucination issue of generating inaccurate or fabricated content even when they possess correct knowledge. In this paper, we extend the exploration of the correlation between hidden-state prediction changes and output factuality into a deeper, token-wise level. Based on the insights , we propose cross-layer Entropy eNhanced Decoding (END), a decoding method that mitigates hallucinations without requiring extra training. END leverages inner probability changes across layers to individually quantify the factual knowledge required for each candidate token, and adjusts the final predicting distribution to prioritize tokens with higher factuality. Experiments on both hallucination and QA benchmarks demonstrate that END significantly enhances the truthfulness and informativeness of generated content while maintaining robust QA accuracy. Moreover, our work provides a deeper perspective on understanding the correlations between inherent knowledge and output factuality.
Mitigating Social Bias in Large Language Models: A Multi-Objective Approach within a Multi-Agent Framework
Dec 20, 2024



Natural language processing (NLP) has seen remarkable advancements with the development of large language models (LLMs). Despite these advancements, LLMs often produce socially biased outputs. Recent studies have mainly addressed this problem by prompting LLMs to behave ethically, but this approach results in unacceptable performance degradation. In this paper, we propose a multi-objective approach within a multi-agent framework (MOMA) to mitigate social bias in LLMs without significantly compromising their performance. The key idea of MOMA involves deploying multiple agents to perform causal interventions on bias-related contents of the input questions, breaking the shortcut connection between these contents and the corresponding answers. Unlike traditional debiasing techniques leading to performance degradation, MOMA substantially reduces bias while maintaining accuracy in downstream tasks. Our experiments conducted on two datasets and two models demonstrate that MOMA reduces bias scores by up to 87.7%, with only a marginal performance degradation of up to 6.8% in the BBQ dataset. Additionally, it significantly enhances the multi-objective metric icat in the StereoSet dataset by up to 58.1%. Code will be made available at https://github.com/Cortantse/MOMA.
Generative Modeling with Explicit Memory
Dec 11, 2024



Recent studies indicate that the denoising process in deep generative diffusion models implicitly learns and memorizes semantic information from the data distribution. These findings suggest that capturing more complex data distributions requires larger neural networks, leading to a substantial increase in computational demands, which in turn become the primary bottleneck in both training and inference of diffusion models. To this end, we introduce \textbf{G}enerative \textbf{M}odeling with \textbf{E}xplicit \textbf{M}emory (GMem), leveraging an external memory bank in both training and sampling phases of diffusion models. This approach preserves semantic information from data distributions, reducing reliance on neural network capacity for learning and generalizing across diverse datasets. The results are significant: our GMem enhances both training, sampling efficiency, and generation quality. For instance, on ImageNet at $256 \times 256$ resolution, GMem accelerates SiT training by over $46.7\times$, achieving the performance of a SiT model trained for $7M$ steps in fewer than $150K$ steps. Compared to the most efficient existing method, REPA, GMem still offers a $16\times$ speedup, attaining an FID score of 5.75 within $250K$ steps, whereas REPA requires over $4M$ steps. Additionally, our method achieves state-of-the-art generation quality, with an FID score of {3.56} without classifier-free guidance on ImageNet $256\times256$. Our code is available at \url{https://github.com/LINs-lab/GMem}.
Underwater Image Enhancement by Transformer-based Diffusion Model with Non-uniform Sampling for Skip Strategy
Sep 07, 2023



In this paper, we present an approach to image enhancement with diffusion model in underwater scenes. Our method adapts conditional denoising diffusion probabilistic models to generate the corresponding enhanced images by using the underwater images and the Gaussian noise as the inputs. Additionally, in order to improve the efficiency of the reverse process in the diffusion model, we adopt two different ways. We firstly propose a lightweight transformer-based denoising network, which can effectively promote the time of network forward per iteration. On the other hand, we introduce a skip sampling strategy to reduce the number of iterations. Besides, based on the skip sampling strategy, we propose two different non-uniform sampling methods for the sequence of the time step, namely piecewise sampling and searching with the evolutionary algorithm. Both of them are effective and can further improve performance by using the same steps against the previous uniform sampling. In the end, we conduct a relative evaluation of the widely used underwater enhancement datasets between the recent state-of-the-art methods and the proposed approach. The experimental results prove that our approach can achieve both competitive performance and high efficiency. Our code is available at \href{mailto:https://github.com/piggy2009/DM_underwater}{\color{blue}{https://github.com/piggy2009/DM\_underwater}}.
Unsupervised Capsule Networks of High-Dimension Point Clouds classification
Jun 15, 2022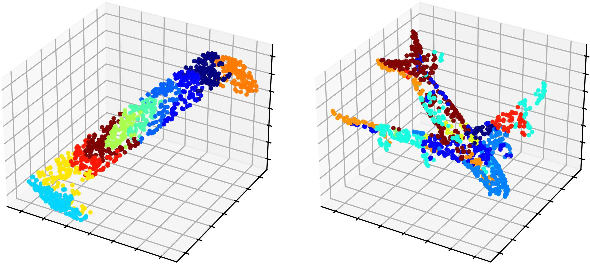
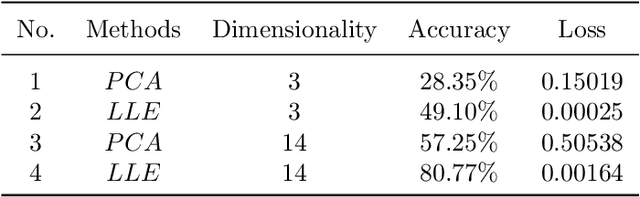
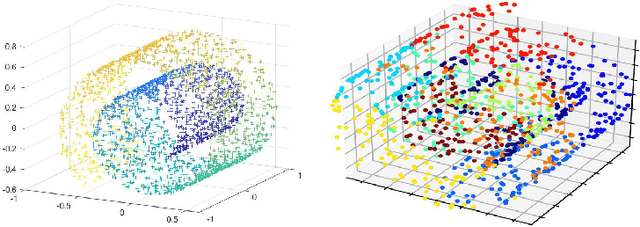
Three-dimensional point clouds learning is widely applied, but the point clouds are still unable to deal with classification and recognition tasks satisfactorily in the cases of irregular geometric structures and high-dimensional space. In 3D space, point clouds tend to have regular Euclidean structure because of their density. On the contrary, due to the high dimensionality, the spatial structure of high-dimensional space is more complex, and point clouds are mostly presented in non-European structure. Furthermore, among current 3D point clouds classification algorithms, Canonical Capsules algorithm based on Euclidean distance is difficult to decompose and identify non-Euclidean structures effectively. Thus, aiming at the point clouds classification task of non-Euclidean structure in 3D and high-dimensional space, this paper refers to the LLE algorithm based on geodesic distance for optimizing and proposes the unsupervised algorithm of high-dimensional point clouds capsule. In this paper, the geometric features of point clouds are considered in the extraction process, so as to transform the high-dimensional non-Euclidean structure into a lower-dimensional Euclidean structure with retaining spatial geometric features. To verify the feasibility of the unsupervised algorithm of high-dimensional point clouds capsule, experiments are conducted in Swiss Roll dataset, point clouds MNIST dataset and point clouds LFW dataset. The results show that (1) non-Euclidean structures can be can effectively identified by this model in Swiss Roll dataset; (2) a significant unsupervised learning effect is realized in point clouds MNIST dataset. In conclusion, the high-dimensional point clouds capsule unsupervised algorithm proposed in this paper is conducive to expand the application scenarios of current point clouds classification and recognition tasks.
Video Salient Object Detection via Adaptive Local-Global Refinement
May 12, 2021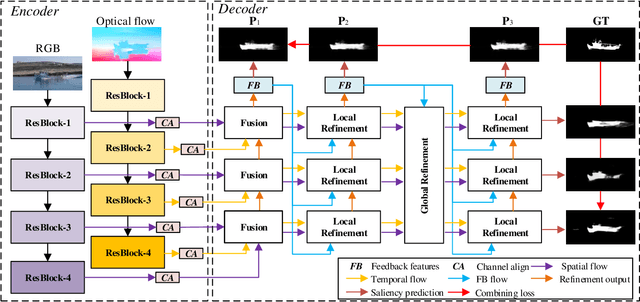
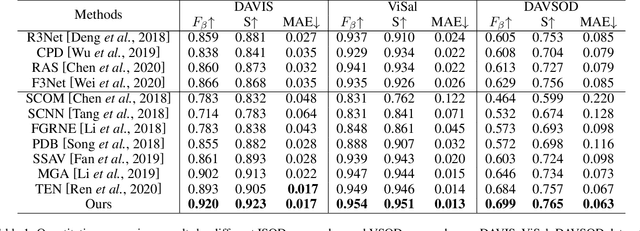
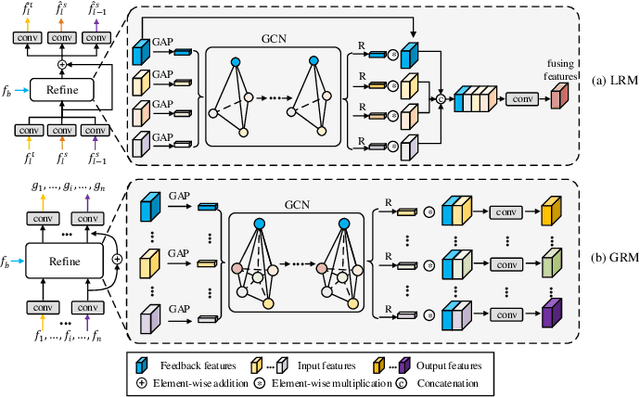

Video salient object detection (VSOD) is an important task in many vision applications. Reliable VSOD requires to simultaneously exploit the information from both the spatial domain and the temporal domain. Most of the existing algorithms merely utilize simple fusion strategies, such as addition and concatenation, to merge the information from different domains. Despite their simplicity, such fusion strategies may introduce feature redundancy, and also fail to fully exploit the relationship between multi-level features extracted from both spatial and temporal domains. In this paper, we suggest an adaptive local-global refinement framework for VSOD. Different from previous approaches, we propose a local refinement architecture and a global one to refine the simply fused features with different scopes, which can fully explore the local dependence and the global dependence of multi-level features. In addition, to emphasize the effective information and suppress the useless one, an adaptive weighting mechanism is designed based on graph convolutional neural network (GCN). We show that our weighting methodology can further exploit the feature correlations, thus driving the network to learn more discriminative feature representation. Extensive experimental results on public video datasets demonstrate the superiority of our method over the existing ones.
Website Fingerprinting on Early QUIC Traffic
Jan 28, 2021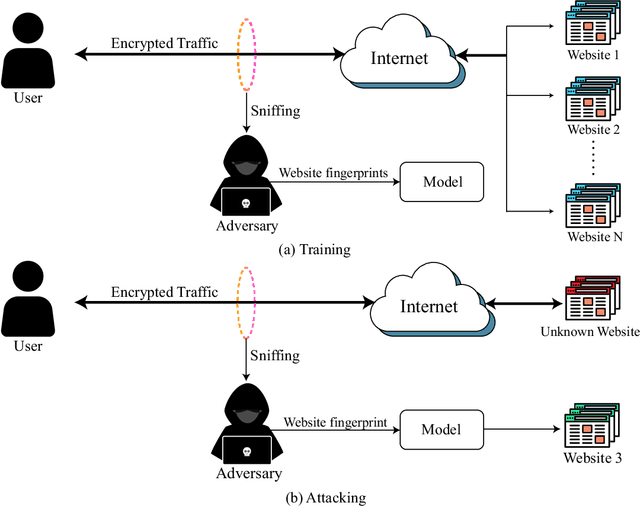
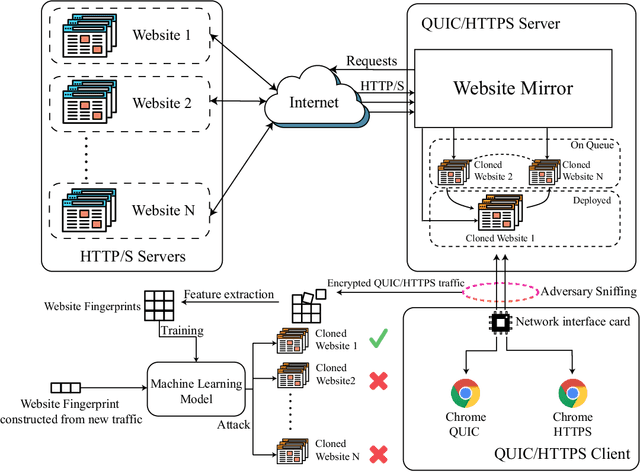
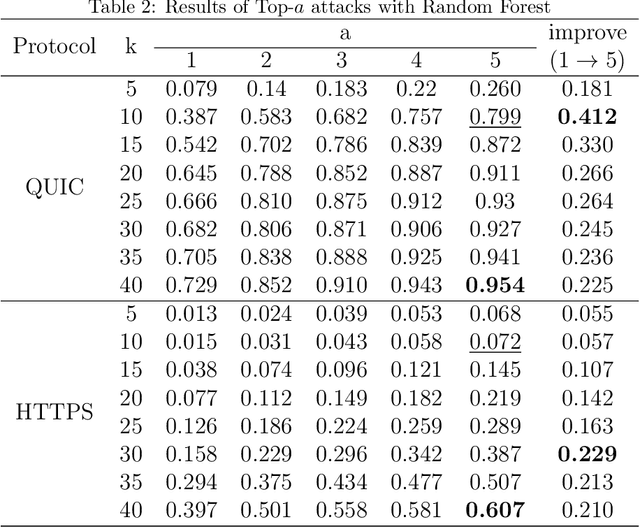
Cryptographic protocols have been widely used to protect the user's privacy and avoid exposing private information. QUIC (Quick UDP Internet Connections), as an alternative to traditional HTTP, demonstrates its unique transmission characteristics: based on UDP for encrypted resource transmission, accelerating web page rendering. However, existing encrypted transmission schemes based on TCP are vulnerable to website fingerprinting (WFP) attacks, allowing adversaries to infer the users' visited websites by eavesdropping on the transmission channel. Whether QUIC protocol can effectively resisting to such attacks is worth investigating. In this work, we demonstrated the extreme vulnerability of QUIC under WFP attacks by comparing attack results under well-designed conditions. We also study the transferability of features, which enable the adversary to use proven effective features on a special protocol attacking a new protocol. This study shows that QUIC is more vulnerable to WFP attacks than HTTPS in the early traffic scenario but is similar in the normal scenario. The maximum attack accuracy on QUIC is 56.8 % and 73 % higher than on HTTPS utilizing Simple features and Transfer features. The insecurity characteristic of QUIC explains the dramatic gap. We also find that features are transferable between protocols, and the feature importance is partially inherited on normal traffic due to the relatively fixed browser rendering sequence and the similar request-response model of protocols. However, the transferability is inefficient when on early traffic, as QUIC and HTTPS show significantly different vulnerability when considering early traffic. We also show that attack accuracy on QUIC could reach 95.4 % with only 40 packets and just using simple features, whereas only 60.7 % when on HTTPS.
Continuous LWE
May 19, 2020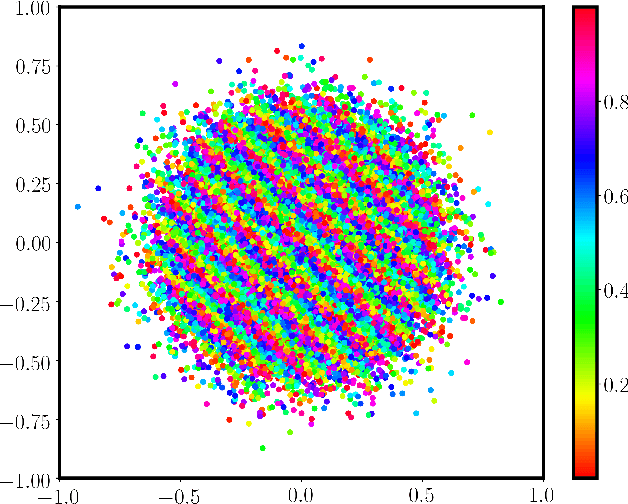
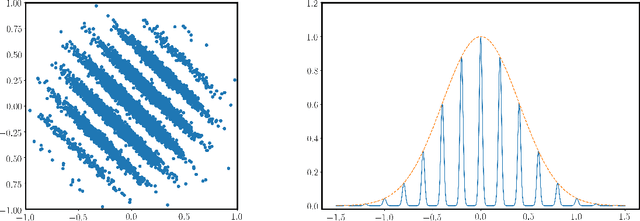
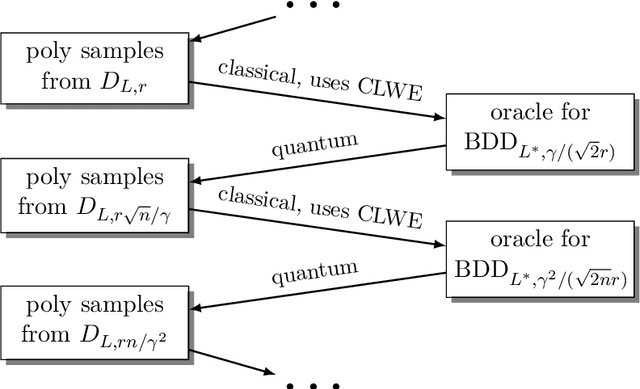
We introduce a continuous analogue of the Learning with Errors (LWE) problem, which we name CLWE. We give a polynomial-time quantum reduction from worst-case lattice problems to CLWE, showing that CLWE enjoys similar hardness guarantees to those of LWE. Alternatively, our result can also be seen as opening new avenues of (quantum) attacks on lattice problems. Our work resolves an open problem regarding the computational complexity of learning mixtures of Gaussians without separability assumptions (Diakonikolas 2016, Moitra 2018). As an additional motivation, (a slight variant of) CLWE was considered in the context of robust machine learning (Diakonikolas et al.~FOCS 2017), where hardness in the statistical query (SQ) model was shown; our work addresses the open question regarding its computational hardness (Bubeck et al.~ICML 2019).