 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImprove Decoding Factuality by Token-wise Cross Layer Entropy of Large Language Models
Feb 05, 2025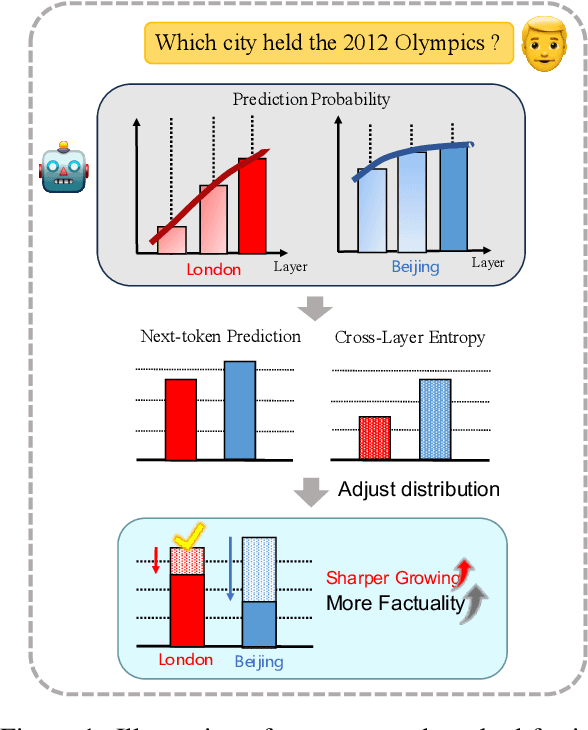
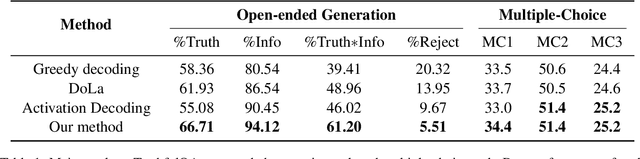
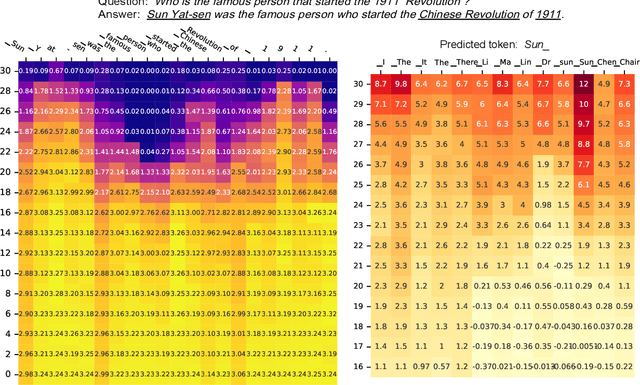
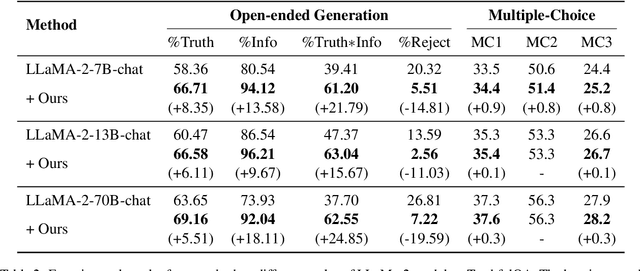
Despite their impressive capacities, Large language models (LLMs) often struggle with the hallucination issue of generating inaccurate or fabricated content even when they possess correct knowledge. In this paper, we extend the exploration of the correlation between hidden-state prediction changes and output factuality into a deeper, token-wise level. Based on the insights , we propose cross-layer Entropy eNhanced Decoding (END), a decoding method that mitigates hallucinations without requiring extra training. END leverages inner probability changes across layers to individually quantify the factual knowledge required for each candidate token, and adjusts the final predicting distribution to prioritize tokens with higher factuality. Experiments on both hallucination and QA benchmarks demonstrate that END significantly enhances the truthfulness and informativeness of generated content while maintaining robust QA accuracy. Moreover, our work provides a deeper perspective on understanding the correlations between inherent knowledge and output factuality.
Enhancing Large Language Model with Decomposed Reasoning for Emotion Cause Pair Extraction
Jan 31, 2024Emotion-Cause Pair Extraction (ECPE) involves extracting clause pairs representing emotions and their causes in a document. Existing methods tend to overfit spurious correlations, such as positional bias in existing benchmark datasets, rather than capturing semantic features. Inspired by recent work, we explore leveraging large language model (LLM) to address ECPE task without additional training. Despite strong capabilities, LLMs suffer from uncontrollable outputs, resulting in mediocre performance. To address this, we introduce chain-of-thought to mimic human cognitive process and propose the Decomposed Emotion-Cause Chain (DECC) framework. Combining inducing inference and logical pruning, DECC guides LLMs to tackle ECPE task. We further enhance the framework by incorporating in-context learning. Experiment results demonstrate the strength of DECC compared to state-of-the-art supervised fine-tuning methods. Finally, we analyze the effectiveness of each component and the robustness of the method in various scenarios, including different LLM bases, rebalanced datasets, and multi-pair extraction.