 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCA-Enhanced Probabilistic U-Net for Effective Ambiguous Medical Image Segmentation
Mar 12, 2026Ambiguous Medical Image Segmentation (AMIS) is significant to address the challenges of inherent uncertainties from image ambiguities, noise, and subjective annotations. Existing conditional variational autoencoder (cVAE)-based methods effectively capture uncertainty but face limitations including redundancy in high-dimensional latent spaces and limited expressiveness of single posterior networks. To overcome these issues, we introduce a novel PCA-Enhanced Probabilistic U-Net (\textbf{PEP U-Net}). Our method effectively incorporates Principal Component Analysis (PCA) for dimensionality reduction in the posterior network to mitigate redundancy and improve computational efficiency. Additionally, we further employ an inverse PCA operation to reconstruct critical information, enhancing the latent space's representational capacity. Compared to conventional generative models, our method preserves the ability to generate diverse segmentation hypotheses while achieving a superior balance between segmentation accuracy and predictive variability, thereby advancing the performance of generative modeling in medical image segmentation.
HEAL: Hindsight Entropy-Assisted Learning for Reasoning Distillation
Mar 11, 2026Distilling reasoning capabilities from Large Reasoning Models (LRMs) into smaller models is typically constrained by the limitation of rejection sampling. Standard methods treat the teacher as a static filter, discarding complex "corner-case" problems where the teacher fails to explore valid solutions independently, thereby creating an artificial "Teacher Ceiling" for the student. In this work, we propose Hindsight Entropy-Assisted Learning (HEAL), an RL-free framework designed to bridge this reasoning gap. Drawing on the educational theory of the Zone of Proximal Development(ZPD), HEAL synergizes three core modules: (1) Guided Entropy-Assisted Repair (GEAR), an active intervention mechanism that detects critical reasoning breakpoints via entropy dynamics and injects targeted hindsight hints to repair broken trajectories; (2) Perplexity-Uncertainty Ratio Estimator (PURE), a rigorous filtering protocol that decouples genuine cognitive breakthroughs from spurious shortcuts; and (3) Progressive Answer-guided Curriculum Evolution (PACE), a three-stage distillation strategy that organizes training from foundational alignment to frontier breakthrough. Extensive experiments on multiple benchmarks demonstrate that HEAL significantly outperforms traditional SFT distillation and other baselines.
AIConfigurator: Lightning-Fast Configuration Optimization for Multi-Framework LLM Serving
Jan 09, 2026Optimizing Large Language Model (LLM) inference in production systems is increasingly difficult due to dynamic workloads, stringent latency/throughput targets, and a rapidly expanding configuration space. This complexity spans not only distributed parallelism strategies (tensor/pipeline/expert) but also intricate framework-specific runtime parameters such as those concerning the enablement of CUDA graphs, available KV-cache memory fractions, and maximum token capacity, which drastically impact performance. The diversity of modern inference frameworks (e.g., TRT-LLM, vLLM, SGLang), each employing distinct kernels and execution policies, makes manual tuning both framework-specific and computationally prohibitive. We present AIConfigurator, a unified performance-modeling system that enables rapid, framework-agnostic inference configuration search without requiring GPU-based profiling. AIConfigurator combines (1) a methodology that decomposes inference into analytically modelable primitives - GEMM, attention, communication, and memory operations while capturing framework-specific scheduling dynamics; (2) a calibrated kernel-level performance database for these primitives across a wide range of hardware platforms and popular open-weights models (GPT-OSS, Qwen, DeepSeek, LLama, Mistral); and (3) an abstraction layer that automatically resolves optimal launch parameters for the target backend, seamlessly integrating into production-grade orchestration systems. Evaluation on production LLM serving workloads demonstrates that AIConfigurator identifies superior serving configurations that improve performance by up to 40% for dense models (e.g., Qwen3-32B) and 50% for MoE architectures (e.g., DeepSeek-V3), while completing searches within 30 seconds on average. Enabling the rapid exploration of vast design spaces - from cluster topology down to engine specific flags.
Group Distributionally Robust Machine Learning under Group Level Distributional Uncertainty
Sep 10, 2025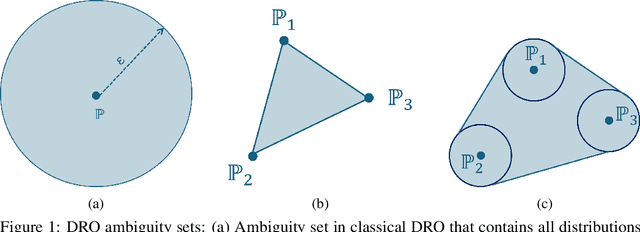

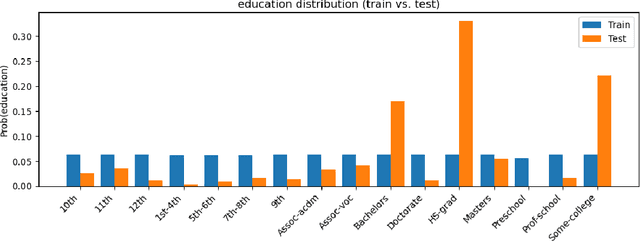
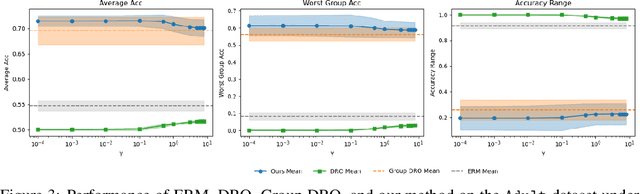
The performance of machine learning (ML) models critically depends on the quality and representativeness of the training data. In applications with multiple heterogeneous data generating sources, standard ML methods often learn spurious correlations that perform well on average but degrade performance for atypical or underrepresented groups. Prior work addresses this issue by optimizing the worst-group performance. However, these approaches typically assume that the underlying data distributions for each group can be accurately estimated using the training data, a condition that is frequently violated in noisy, non-stationary, and evolving environments. In this work, we propose a novel framework that relies on Wasserstein-based distributionally robust optimization (DRO) to account for the distributional uncertainty within each group, while simultaneously preserving the objective of improving the worst-group performance. We develop a gradient descent-ascent algorithm to solve the proposed DRO problem and provide convergence results. Finally, we validate the effectiveness of our method on real-world data.
JRDB-Reasoning: A Difficulty-Graded Benchmark for Visual Reasoning in Robotics
Aug 14, 2025Recent advances in Vision-Language Models (VLMs) and large language models (LLMs) have greatly enhanced visual reasoning, a key capability for embodied AI agents like robots. However, existing visual reasoning benchmarks often suffer from several limitations: they lack a clear definition of reasoning complexity, offer have no control to generate questions over varying difficulty and task customization, and fail to provide structured, step-by-step reasoning annotations (workflows). To bridge these gaps, we formalize reasoning complexity, introduce an adaptive query engine that generates customizable questions of varying complexity with detailed intermediate annotations, and extend the JRDB dataset with human-object interaction and geometric relationship annotations to create JRDB-Reasoning, a benchmark tailored for visual reasoning in human-crowded environments. Our engine and benchmark enable fine-grained evaluation of visual reasoning frameworks and dynamic assessment of visual-language models across reasoning levels.
FairPOT: Balancing AUC Performance and Fairness with Proportional Optimal Transport
Aug 05, 2025Fairness metrics utilizing the area under the receiver operator characteristic curve (AUC) have gained increasing attention in high-stakes domains such as healthcare, finance, and criminal justice. In these domains, fairness is often evaluated over risk scores rather than binary outcomes, and a common challenge is that enforcing strict fairness can significantly degrade AUC performance. To address this challenge, we propose Fair Proportional Optimal Transport (FairPOT), a novel, model-agnostic post-processing framework that strategically aligns risk score distributions across different groups using optimal transport, but does so selectively by transforming a controllable proportion, i.e., the top-lambda quantile, of scores within the disadvantaged group. By varying lambda, our method allows for a tunable trade-off between reducing AUC disparities and maintaining overall AUC performance. Furthermore, we extend FairPOT to the partial AUC setting, enabling fairness interventions to concentrate on the highest-risk regions. Extensive experiments on synthetic, public, and clinical datasets show that FairPOT consistently outperforms existing post-processing techniques in both global and partial AUC scenarios, often achieving improved fairness with slight AUC degradation or even positive gains in utility. The computational efficiency and practical adaptability of FairPOT make it a promising solution for real-world deployment.
Next-User Retrieval: Enhancing Cold-Start Recommendations via Generative Next-User Modeling
Jun 18, 2025The item cold-start problem is critical for online recommendation systems, as the success of this phase determines whether high-quality new items can transition to popular ones, receive essential feedback to inspire creators, and thus lead to the long-term retention of creators. However, modern recommendation systems still struggle to address item cold-start challenges due to the heavy reliance on item and historical interactions, which are non-trivial for cold-start items lacking sufficient exposure and feedback. Lookalike algorithms provide a promising solution by extending feedback for new items based on lookalike users. Traditional lookalike algorithms face such limitations: (1) failing to effectively model the lookalike users and further improve recommendations with the existing rule- or model-based methods; and (2) struggling to utilize the interaction signals and incorporate diverse features in modern recommendation systems. Inspired by lookalike algorithms, we propose Next-User Retrieval, a novel framework for enhancing cold-start recommendations via generative next-user modeling. Specifically, we employ a transformer-based model to capture the unidirectional relationships among recently interacted users and utilize these sequences to generate the next potential user who is most likely to interact with the item. The additional item features are also integrated as prefix prompt embeddings to assist the next-user generation. The effectiveness of Next-User Retrieval is evaluated through both offline experiments and online A/B tests. Our method achieves significant improvements with increases of 0.0142% in daily active users and +0.1144% in publications in Douyin, showcasing its practical applicability and scalability.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Enhancing Cooperative Multi-Agent Reinforcement Learning with State Modelling and Adversarial Exploration
May 08, 2025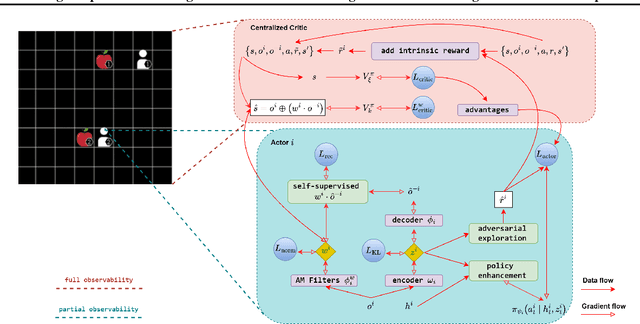


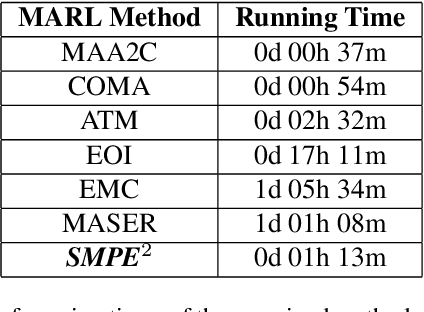
Learning to cooperate in distributed partially observable environments with no communication abilities poses significant challenges for multi-agent deep reinforcement learning (MARL). This paper addresses key concerns in this domain, focusing on inferring state representations from individual agent observations and leveraging these representations to enhance agents' exploration and collaborative task execution policies. To this end, we propose a novel state modelling framework for cooperative MARL, where agents infer meaningful belief representations of the non-observable state, with respect to optimizing their own policies, while filtering redundant and less informative joint state information. Building upon this framework, we propose the MARL SMPE algorithm. In SMPE, agents enhance their own policy's discriminative abilities under partial observability, explicitly by incorporating their beliefs into the policy network, and implicitly by adopting an adversarial type of exploration policies which encourages agents to discover novel, high-value states while improving the discriminative abilities of others. Experimentally, we show that SMPE outperforms state-of-the-art MARL algorithms in complex fully cooperative tasks from the MPE, LBF, and RWARE benchmarks.
Quantitative Analysis of Performance Drop in DeepSeek Model Quantization
May 05, 2025Recently, there is a high demand for deploying DeepSeek-R1 and V3 locally, possibly because the official service often suffers from being busy and some organizations have data privacy concerns. While single-machine deployment offers infrastructure simplicity, the models' 671B FP8 parameter configuration exceeds the practical memory limits of a standard 8-GPU machine. Quantization is a widely used technique that helps reduce model memory consumption. However, it is unclear what the performance of DeepSeek-R1 and V3 will be after being quantized. This technical report presents the first quantitative evaluation of multi-bitwidth quantization across the complete DeepSeek model spectrum. Key findings reveal that 4-bit quantization maintains little performance degradation versus FP8 while enabling single-machine deployment on standard NVIDIA GPU devices. We further propose DQ3_K_M, a dynamic 3-bit quantization method that significantly outperforms traditional Q3_K_M variant on various benchmarks, which is also comparable with 4-bit quantization (Q4_K_M) approach in most tasks. Moreover, DQ3_K_M supports single-machine deployment configurations for both NVIDIA H100/A100 and Huawei 910B. Our implementation of DQ3\_K\_M is released at https://github.com/UnicomAI/DeepSeek-Eval, containing optimized 3-bit quantized variants of both DeepSeek-R1 and DeepSeek-V3.