 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Cooperative Multi-Agent Reinforcement Learning with State Modelling and Adversarial Exploration
May 08, 2025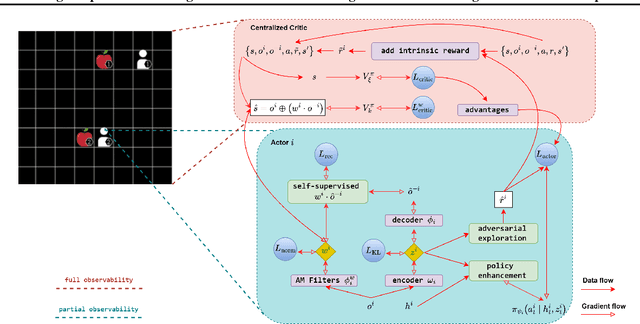


Learning to cooperate in distributed partially observable environments with no communication abilities poses significant challenges for multi-agent deep reinforcement learning (MARL). This paper addresses key concerns in this domain, focusing on inferring state representations from individual agent observations and leveraging these representations to enhance agents' exploration and collaborative task execution policies. To this end, we propose a novel state modelling framework for cooperative MARL, where agents infer meaningful belief representations of the non-observable state, with respect to optimizing their own policies, while filtering redundant and less informative joint state information. Building upon this framework, we propose the MARL SMPE algorithm. In SMPE, agents enhance their own policy's discriminative abilities under partial observability, explicitly by incorporating their beliefs into the policy network, and implicitly by adopting an adversarial type of exploration policies which encourages agents to discover novel, high-value states while improving the discriminative abilities of others. Experimentally, we show that SMPE outperforms state-of-the-art MARL algorithms in complex fully cooperative tasks from the MPE, LBF, and RWARE benchmarks.
Ranking Joint Policies in Dynamic Games using Evolutionary Dynamics
Feb 20, 2025Game-theoretic solution concepts, such as the Nash equilibrium, have been key to finding stable joint actions in multi-player games. However, it has been shown that the dynamics of agents' interactions, even in simple two-player games with few strategies, are incapable of reaching Nash equilibria, exhibiting complex and unpredictable behavior. Instead, evolutionary approaches can describe the long-term persistence of strategies and filter out transient ones, accounting for the long-term dynamics of agents' interactions. Our goal is to identify agents' joint strategies that result in stable behavior, being resistant to changes, while also accounting for agents' payoffs, in dynamic games. Towards this goal, and building on previous results, this paper proposes transforming dynamic games into their empirical forms by considering agents' strategies instead of agents' actions, and applying the evolutionary methodology $\alpha$-Rank to evaluate and rank strategy profiles according to their long-term dynamics. This methodology not only allows us to identify joint strategies that are strong through agents' long-term interactions, but also provides a descriptive, transparent framework regarding the high ranking of these strategies. Experiments report on agents that aim to collaboratively solve a stochastic version of the graph coloring problem. We consider different styles of play as strategies to define the empirical game, and train policies realizing these strategies, using the DQN algorithm. Then we run simulations to generate the payoff matrix required by $\alpha$-Rank to rank joint strategies.
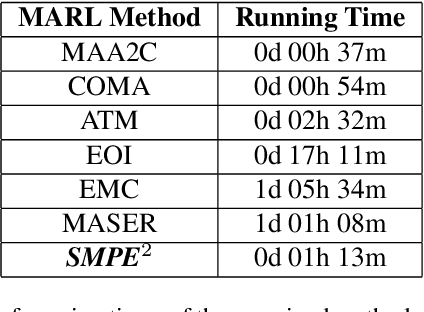
An Extended Benchmarking of Multi-Agent Reinforcement Learning Algorithms in Complex Fully Cooperative Tasks
Feb 07, 2025



Multi-Agent Reinforcement Learning (MARL) has recently emerged as a significant area of research. However, MARL evaluation often lacks systematic diversity, hindering a comprehensive understanding of algorithms' capabilities. In particular, cooperative MARL algorithms are predominantly evaluated on benchmarks such as SMAC and GRF, which primarily feature team game scenarios without assessing adequately various aspects of agents' capabilities required in fully cooperative real-world tasks such as multi-robot cooperation and warehouse, resource management, search and rescue, and human-AI cooperation. Moreover, MARL algorithms are mainly evaluated on low dimensional state spaces, and thus their performance on high-dimensional (e.g., image) observations is not well-studied. To fill this gap, this paper highlights the crucial need for expanding systematic evaluation across a wider array of existing benchmarks. To this end, we conduct extensive evaluation and comparisons of well-known MARL algorithms on complex fully cooperative benchmarks, including tasks with images as agents' observations. Interestingly, our analysis shows that many algorithms, hailed as state-of-the-art on SMAC and GRF, may underperform standard MARL baselines on fully cooperative benchmarks. Finally, towards more systematic and better evaluation of cooperative MARL algorithms, we have open-sourced PyMARLzoo+, an extension of the widely used (E)PyMARL libraries, which addresses an open challenge from [TBG++21], facilitating seamless integration and support with all benchmarks of PettingZoo, as well as Overcooked, PressurePlate, Capture Target and Box Pushing.
XDQN: Inherently Interpretable DQN through Mimicking
Jan 08, 2023


Although deep reinforcement learning (DRL) methods have been successfully applied in challenging tasks, their application in real-world operational settings is challenged by methods' limited ability to provide explanations. Among the paradigms for explainability in DRL is the interpretable box design paradigm, where interpretable models substitute inner constituent models of the DRL method, thus making the DRL method "inherently" interpretable. In this paper we explore this paradigm and we propose XDQN, an explainable variation of DQN, which uses an interpretable policy model trained through mimicking. XDQN is challenged in a complex, real-world operational multi-agent problem, where agents are independent learners solving congestion problems. Specifically, XDQN is evaluated in three MARL scenarios, pertaining to the demand-capacity balancing problem of air traffic management. XDQN achieves performance similar to that of DQN, while its abilities to provide global models' interpretations and interpretations of local decisions are demonstrated.
Automating the resolution of flight conflicts: Deep reinforcement learning in service of air traffic controllers
Jun 15, 2022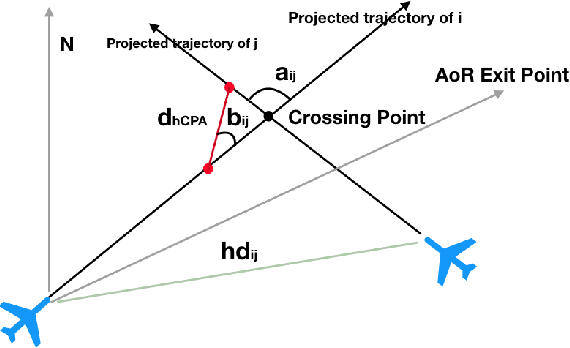
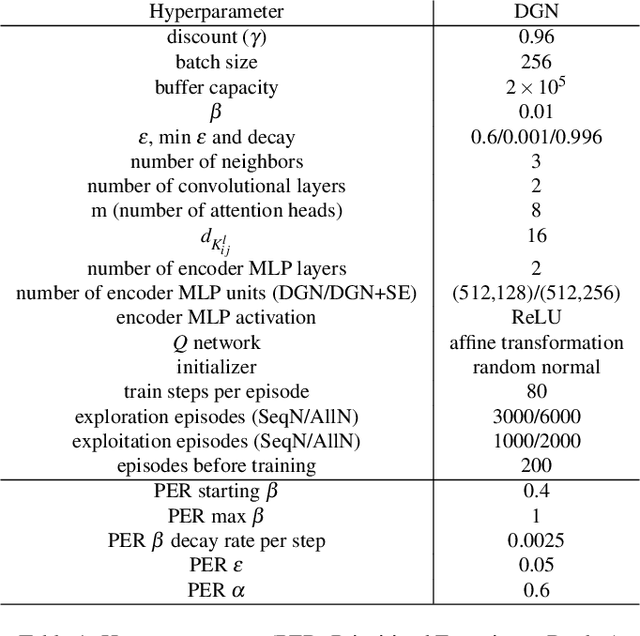

Dense and complex air traffic scenarios require higher levels of automation than those exhibited by tactical conflict detection and resolution (CD\&R) tools that air traffic controllers (ATCO) use today. However, the air traffic control (ATC) domain, being safety critical, requires AI systems to which operators are comfortable to relinquishing control, guaranteeing operational integrity and automation adoption. Two major factors towards this goal are quality of solutions, and transparency in decision making. This paper proposes using a graph convolutional reinforcement learning method operating in a multiagent setting where each agent (flight) performs a CD\&R task, jointly with other agents. We show that this method can provide high-quality solutions with respect to stakeholders interests (air traffic controllers and airspace users), addressing operational transparency issues.
Semantic Integration & Single-Site Opening of Multiple Governmental Data Sources
Jul 02, 2014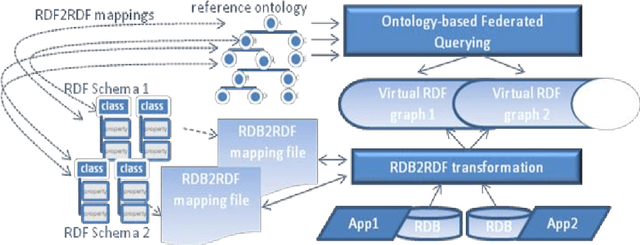
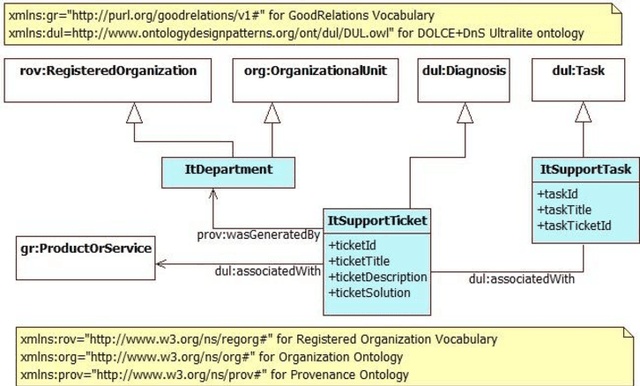
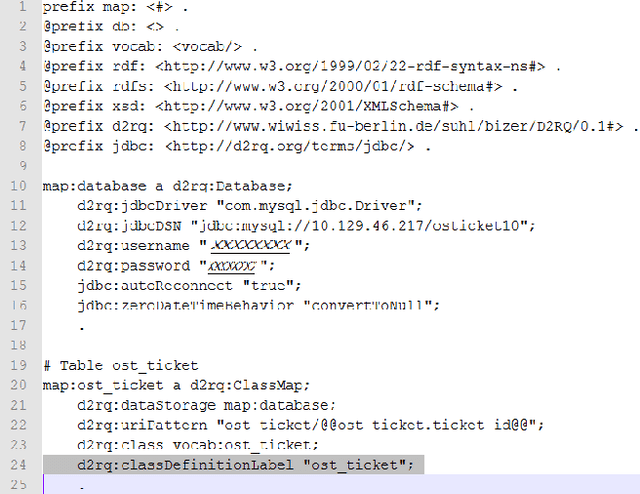
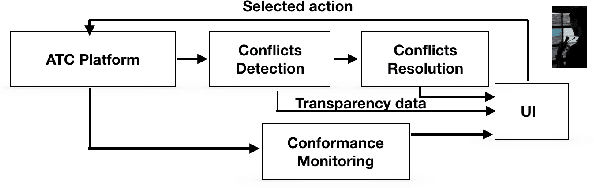
In many cases, government data is still "locked" in several "data silos", even within the boundaries of a single (inter-)national public organization with disparate and distributed organizational units and departments spread across multiple sites. Opening data and enabling its unified querying from a single site in an efficient and effective way is a semantic application integration and open government data challenge. This paper describes how NARA is using Semantic Web technology to implement an application integration approach within the boundaries of its organization via opening and querying multiple governmental data sources from a single site. The generic approach proposed, namely S3-AI, provides support to answering unified, ontology-mediated, federated queries to data produced and exploited by disparate applications, while these are being located in different organizational sites. S3-AI preserves ownership, autonomy and independency of applications and data. The paper extensively demonstrates S3-AI, using the D2RQ and Fuseki technologies, for addressing the needs of a governmental "IT helpdesk support" case.
MUDOS-NG: Multi-document Summaries Using N-gram Graphs
Dec 09, 2010

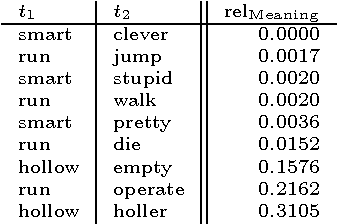
This report describes the MUDOS-NG summarization system, which applies a set of language-independent and generic methods for generating extractive summaries. The proposed methods are mostly combinations of simple operators on a generic character n-gram graph representation of texts. This work defines the set of used operators upon n-gram graphs and proposes using these operators within the multi-document summarization process in such subtasks as document analysis, salient sentence selection, query expansion and redundancy control. Furthermore, a novel chunking methodology is used, together with a novel way to assign concepts to sentences for query expansion. The experimental results of the summarization system, performed upon widely used corpora from the Document Understanding and the Text Analysis Conferences, are promising and provide evidence for the potential of the generic methods introduced. This work aims to designate core methods exploiting the n-gram graph representation, providing the basis for more advanced summarization systems.