 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Act Evaluation Benchmark: An Open, Transparent, and Reproducible Evaluation Dataset for NLP and RAG Systems
Mar 10, 2026The rapid rollout of AI in heterogeneous public and societal sectors has subsequently escalated the need for compliance with regulatory standards and frameworks. The EU AI Act has emerged as a landmark in the regulatory landscape. The development of solutions that elicit the level of AI systems' compliance with such standards is often limited by the lack of resources, hindering the semi-automated or automated evaluation of their performance. This generates the need for manual work, which is often error-prone, resource-limited or limited to cases not clearly described by the regulation. This paper presents an open, transparent, and reproducible method of creating a resource that facilitates the evaluation of NLP models with a strong focus on RAG systems. We have developed a dataset that contain the tasks of risk-level classification, article retrieval, obligation generation, and question-answering for the EU AI Act. The dataset files are in a machine-to-machine appropriate format. To generate the files, we utilise domain knowledge as an exegetical basis, combining with the processing and reasoning power of large language models to generate scenarios along with the respective tasks. Our methodology demonstrates a way to harness language models for grounded generation with high document relevancy. Besides, we overcome limitations such as navigating the decision boundaries of risk-levels that are not explicitly defined within the EU AI Act, such as limited and minimal cases. Finally, we demonstrate our dataset's effectiveness by evaluating a RAG-based solution that reaches 0.87 and 0.85 F1-score for prohibited and high-risk scenarios.
Depth-guided Free-space Segmentation for a Mobile Robot
Nov 03, 2023



Accurate indoor free-space segmentation is a challenging task due to the complexity and the dynamic nature that indoor environments exhibit. We propose an indoors free-space segmentation method that associates large depth values with navigable regions. Our method leverages an unsupervised masking technique that, using positive instances, generates segmentation labels based on textural homogeneity and depth uniformity. Moreover, we generate superpixels corresponding to areas of higher depth and align them with features extracted from a Dense Prediction Transformer (DPT). Using the estimated free-space masks and the DPT feature representation, a SegFormer model is fine-tuned on our custom-collected indoor dataset. Our experiments demonstrate sufficient performance in intricate scenarios characterized by cluttered obstacles and challenging identification of free space.
Developing Machine-Learned Potentials for Coarse-Grained Molecular Simulations: Challenges and Pitfalls
Sep 26, 2022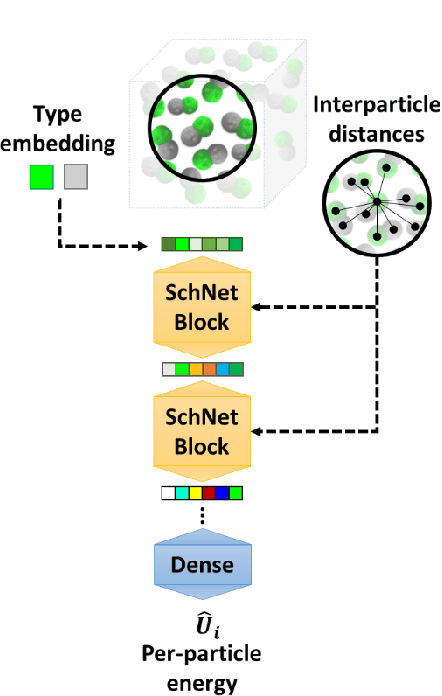
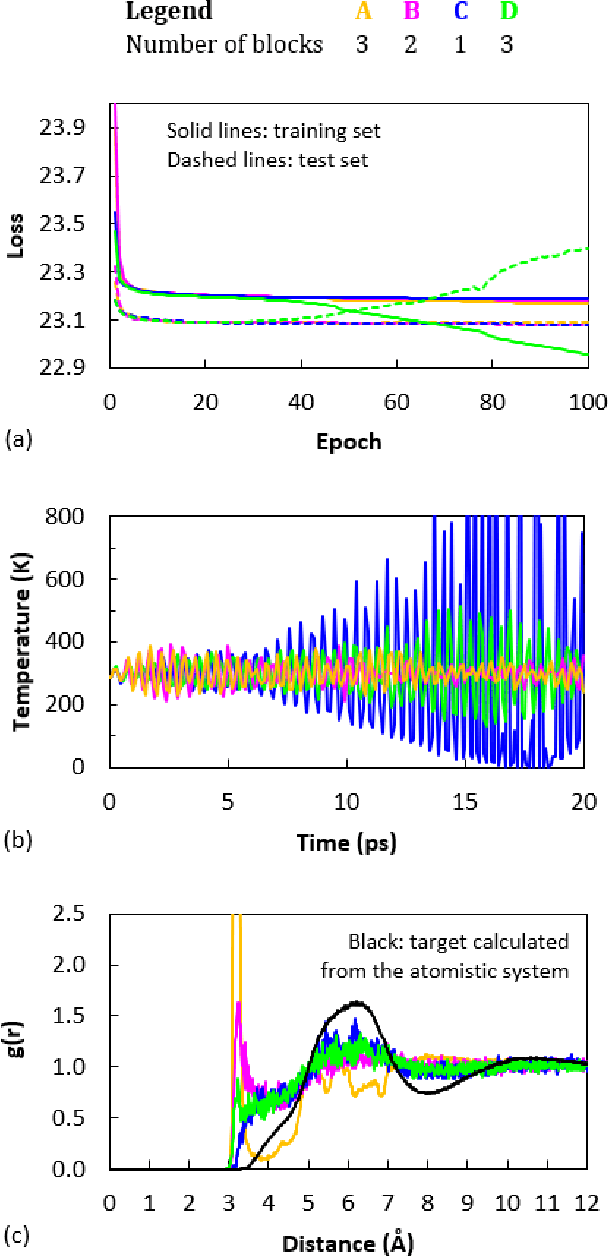
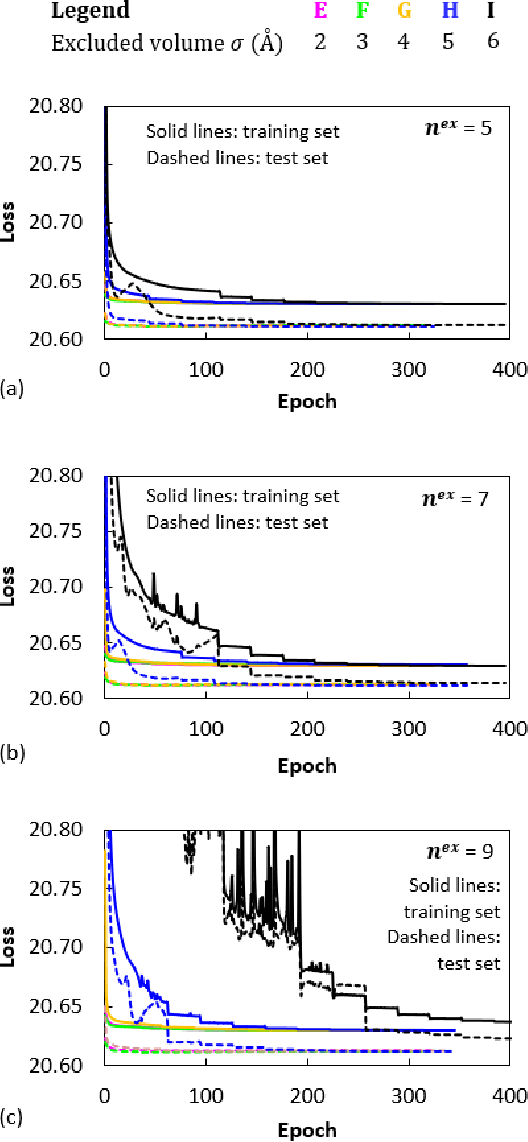
Coarse graining (CG) enables the investigation of molecular properties for larger systems and at longer timescales than the ones attainable at the atomistic resolution. Machine learning techniques have been recently proposed to learn CG particle interactions, i.e. develop CG force fields. Graph representations of molecules and supervised training of a graph convolutional neural network architecture are used to learn the potential of mean force through a force matching scheme. In this work, the force acting on each CG particle is correlated to a learned representation of its local environment that goes under the name of SchNet, constructed via continuous filter convolutions. We explore the application of SchNet models to obtain a CG potential for liquid benzene, investigating the effect of model architecture and hyperparameters on the thermodynamic, dynamical, and structural properties of the simulated CG systems, reporting and discussing challenges encountered and future directions envisioned.
Investigation of Machine Learning-based Coarse-Grained Mapping Schemes for Organic Molecules
Sep 26, 2022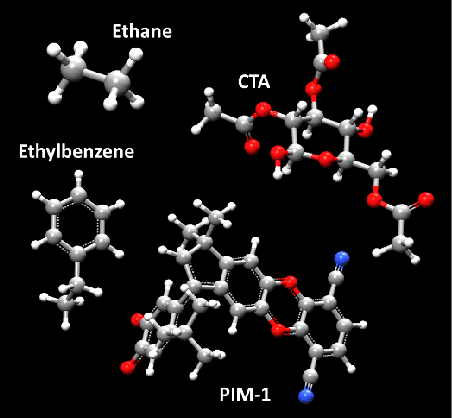
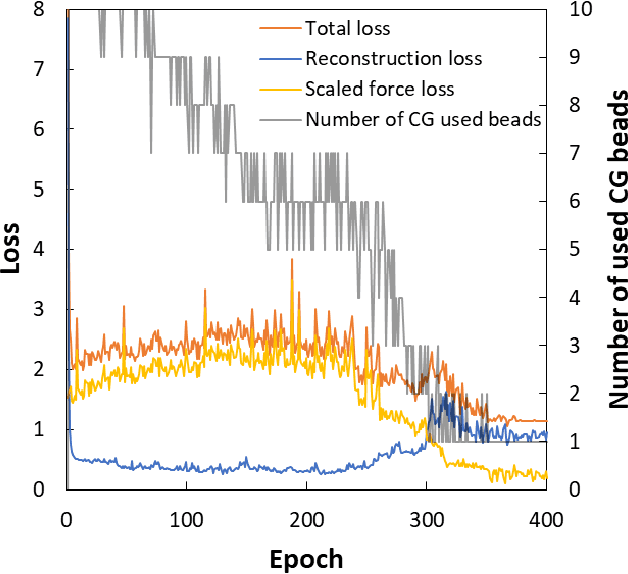
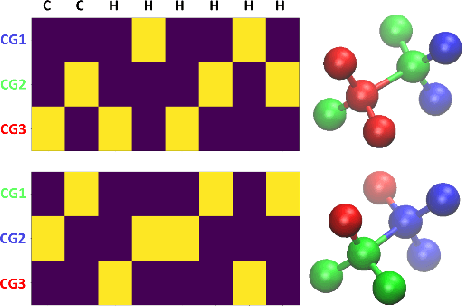
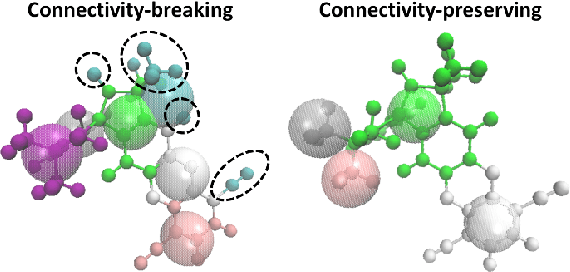
Due to the wide range of timescales that are present in macromolecular systems, hierarchical multiscale strategies are necessary for their computational study. Coarse-graining (CG) allows to establish a link between different system resolutions and provides the backbone for the development of robust multiscale simulations and analyses. The CG mapping process is typically system- and application-specific, and it relies on chemical intuition. In this work, we explored the application of a Machine Learning strategy, based on Variational Autoencoders, for the development of suitable mapping schemes from the atomistic to the coarse-grained space of molecules with increasing chemical complexity. An extensive evaluation of the effect of the model hyperparameters on the training process and on the final output was performed, and an existing method was extended with the definition of different loss functions and the implementation of a selection criterion that ensures physical consistency of the output. The relationship between the input feature choice and the reconstruction accuracy was analyzed, supporting the need to introduce rotational invariance into the system. Strengths and limitations of the approach, both in the mapping and in the backmapping steps, are highlighted and critically discussed.
Evidence Transfer for Improving Clustering Tasks Using External Categorical Evidence
Nov 09, 2018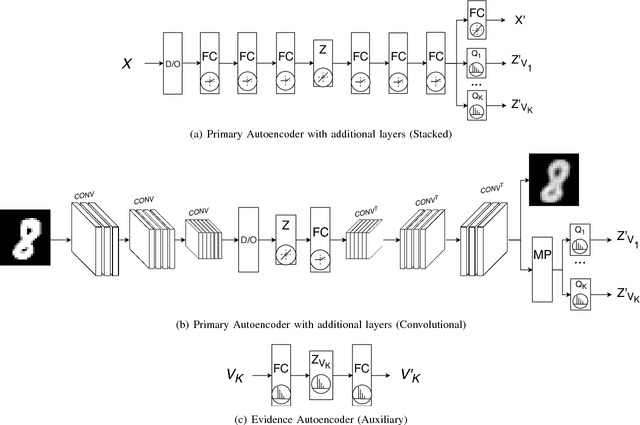

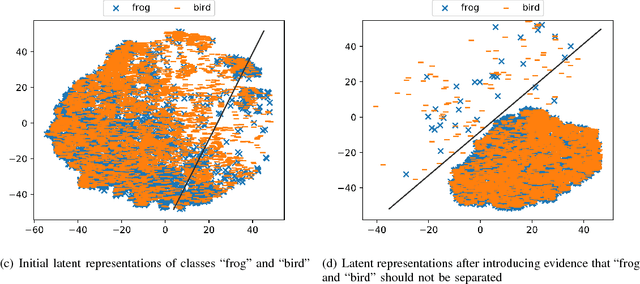

In this paper we introduce evidence transfer for clustering, a deep learning method that can incrementally manipulate the latent representations of an autoencoder, according to external categorical evidence, in order to improve a clustering outcome. It is deployed on a baseline solution to reduce the cross entropy between the external evidence and an extension of the latent space. By evidence transfer we define the process by which the categorical outcome of an external, auxiliary task is exploited to improve a primary task, in this case representation learning for clustering. Our proposed method makes no assumptions regarding the categorical evidence presented, nor the structure of the latent space. We compare our method, against the baseline solution by performing k-means clustering before and after its deployment. Experiments with three different kinds of evidence show that our method effectively manipulates the latent representations when introduced with real corresponding evidence, while remaining robust when presented with low quality evidence.
ANNETT-O: An Ontology for Describing Artificial Neural Network Evaluation, Topology and Training
May 10, 2018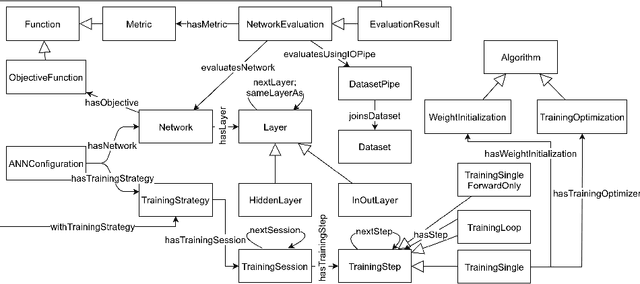
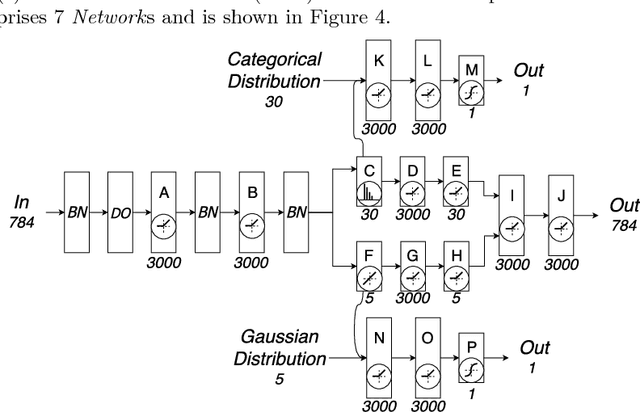

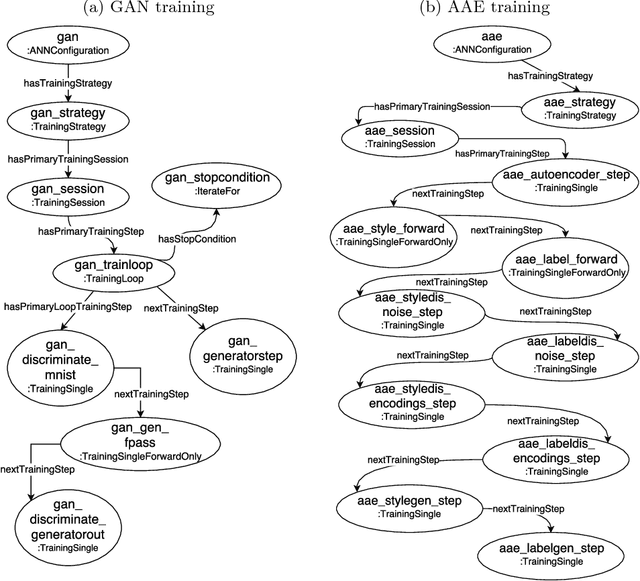
Deep learning models, while effective and versatile, are becoming increasingly complex, often including multiple overlapping networks of arbitrary depths, multiple objectives and non-intuitive training methodologies. This makes it increasingly difficult for researchers and practitioners to design, train and understand them. In this paper we present ANNETT-O, a much-needed, generic and computer-actionable vocabulary for researchers and practitioners to describe their deep learning configurations, training procedures and experiments. The proposed ontology focuses on topological, training and evaluation aspects of complex deep neural configurations, while keeping peripheral entities more succinct. Knowledge bases implementing ANNETT-O can support a wide variety of queries, providing relevant insights to users. In addition to a detailed description of the ontology, we demonstrate its suitability to the task via a number of hypothetical use-cases of increasing complexity.
MUDOS-NG: Multi-document Summaries Using N-gram Graphs
Dec 09, 2010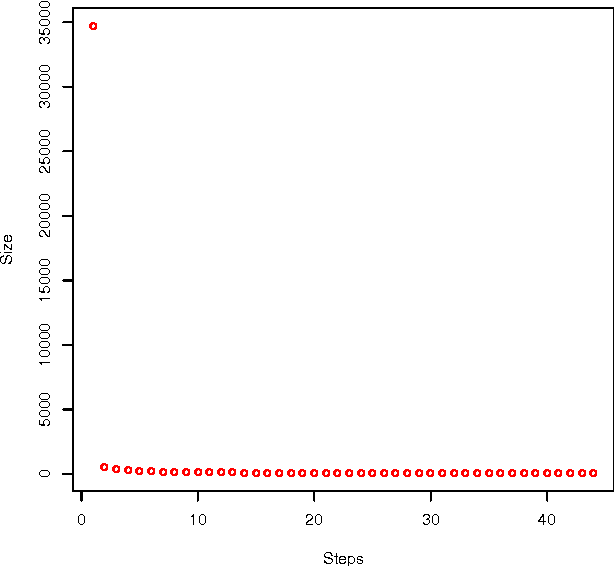

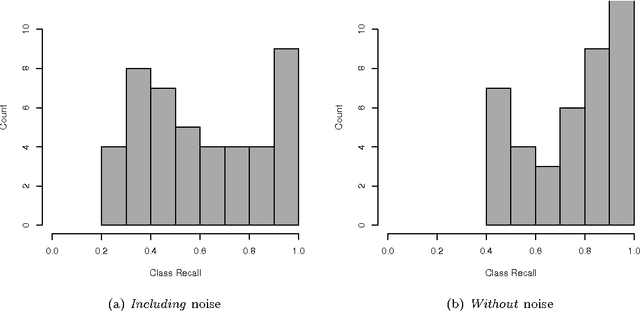
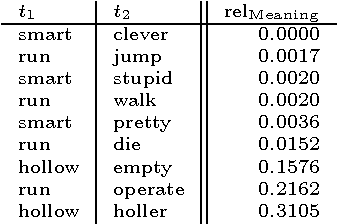
This report describes the MUDOS-NG summarization system, which applies a set of language-independent and generic methods for generating extractive summaries. The proposed methods are mostly combinations of simple operators on a generic character n-gram graph representation of texts. This work defines the set of used operators upon n-gram graphs and proposes using these operators within the multi-document summarization process in such subtasks as document analysis, salient sentence selection, query expansion and redundancy control. Furthermore, a novel chunking methodology is used, together with a novel way to assign concepts to sentences for query expansion. The experimental results of the summarization system, performed upon widely used corpora from the Document Understanding and the Text Analysis Conferences, are promising and provide evidence for the potential of the generic methods introduced. This work aims to designate core methods exploiting the n-gram graph representation, providing the basis for more advanced summarization systems.
Summarizing Reports on Evolving Events; Part I: Linear Evolution
Aug 22, 2005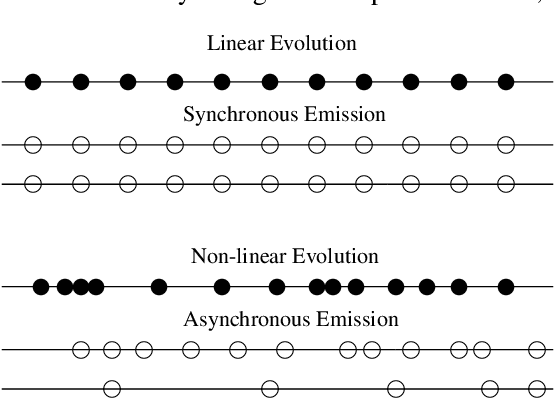

We present an approach for summarization from multiple documents which report on events that evolve through time, taking into account the different document sources. We distinguish the evolution of an event into linear and non-linear. According to our approach, each document is represented by a collection of messages which are then used in order to instantiate the cross-document relations that determine the summary content. The paper presents the summarization system that implements this approach through a case study on linear evolution.
* 7 pages. Published on the Conference Recent Advances in Natural Language Processing (RANLP, 2005)
Summarization from Medical Documents: A Survey
Apr 13, 2005
Objective: The aim of this paper is to survey the recent work in medical documents summarization. Background: During the last decade, documents summarization got increasing attention by the AI research community. More recently it also attracted the interest of the medical research community as well, due to the enormous growth of information that is available to the physicians and researchers in medicine, through the large and growing number of published journals, conference proceedings, medical sites and portals on the World Wide Web, electronic medical records, etc. Methodology: This survey gives first a general background on documents summarization, presenting the factors that summarization depends upon, discussing evaluation issues and describing briefly the various types of summarization techniques. It then examines the characteristics of the medical domain through the different types of medical documents. Finally, it presents and discusses the summarization techniques used so far in the medical domain, referring to the corresponding systems and their characteristics. Discussion and conclusions: The paper discusses thoroughly the promising paths for future research in medical documents summarization. It mainly focuses on the issue of scaling to large collections of documents in various languages and from different media, on personalization issues, on portability to new sub-domains, and on the integration of summarization technology in practical applications
* 21 pages, 4 tables
An Introduction to the Summarization of Evolving Events: Linear and Non-linear Evolution
Mar 15, 2005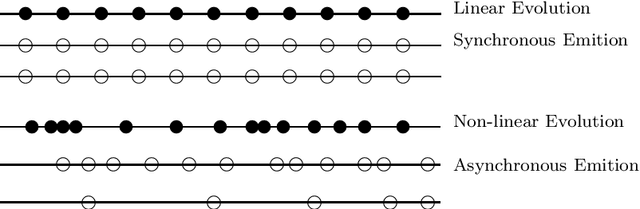
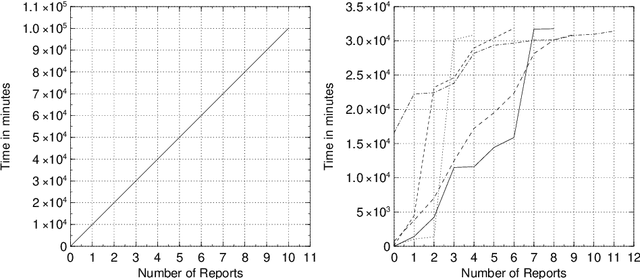
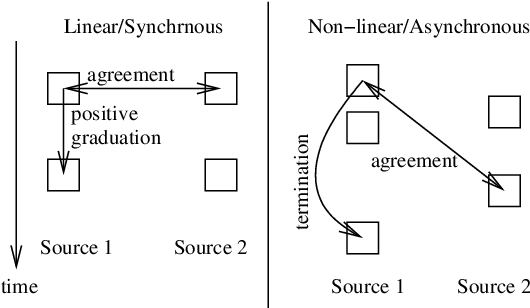
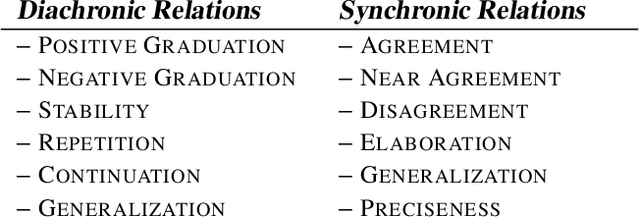
This paper examines the summarization of events that evolve through time. It discusses different types of evolution taking into account the time in which the incidents of an event are happening and the different sources reporting on the specific event. It proposes an approach for multi-document summarization which employs ``messages'' for representing the incidents of an event and cross-document relations that hold between messages according to certain conditions. The paper also outlines the current version of the summarization system we are implementing to realize this approach.
* 10 pages, 3 figures. To be pulished in Natural Language Understanding and Cognitive Science (NLUCS - 2005) conference