 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-Based Decomposition of Electrodermal Activity for Real-World Mental Health Applications
Jun 04, 2025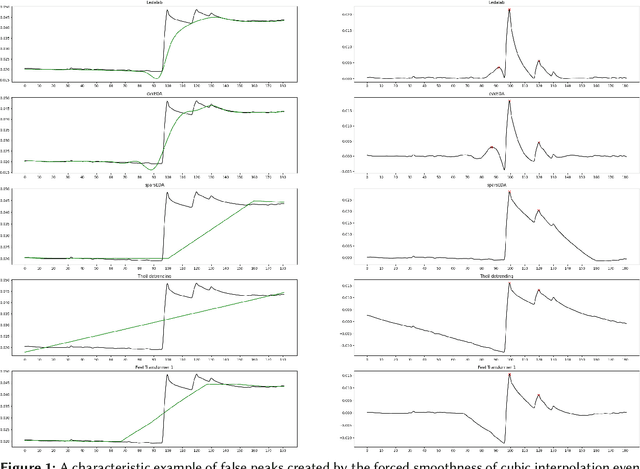
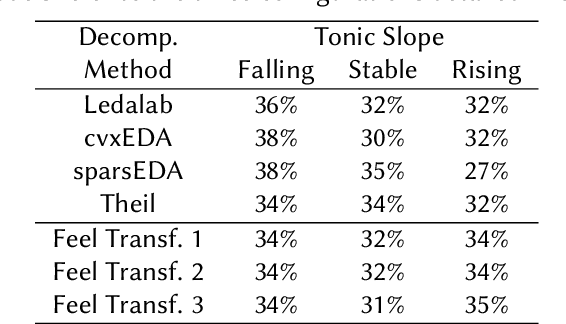
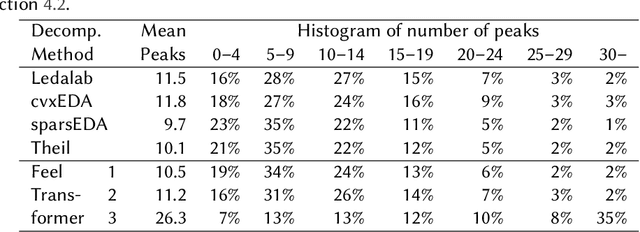
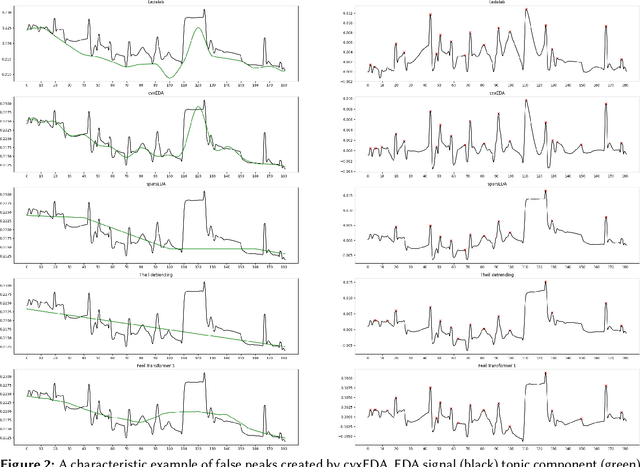
Decomposing Electrodermal Activity (EDA) into phasic (short-term, stimulus-linked responses) and tonic (longer-term baseline) components is essential for extracting meaningful emotional and physiological biomarkers. This study presents a comparative analysis of knowledge-driven, statistical, and deep learning-based methods for EDA signal decomposition, with a focus on in-the-wild data collected from wearable devices. In particular, the authors introduce the Feel Transformer, a novel Transformer-based model adapted from the Autoformer architecture, designed to separate phasic and tonic components without explicit supervision. The model leverages pooling and trend-removal mechanisms to enforce physiologically meaningful decompositions. Comparative experiments against methods such as Ledalab, cvxEDA, and conventional detrending show that the Feel Transformer achieves a balance between feature fidelity (SCR frequency, amplitude, and tonic slope) and robustness to noisy, real-world data. The model demonstrates potential for real-time biosignal analysis and future applications in stress prediction, digital mental health interventions, and physiological forecasting.
seqKAN: Sequence processing with Kolmogorov-Arnold Networks
Feb 20, 2025



Kolmogorov-Arnold Networks (KANs) have been recently proposed as a machine learning framework that is more interpretable and controllable than the multi-layer perceptron. Various network architectures have been proposed within the KAN framework targeting different tasks and application domains, including sequence processing. This paper proposes seqKAN, a new KAN architecture for sequence processing. Although multiple sequence processing KAN architectures have already been proposed, we argue that seqKAN is more faithful to the core concept of the KAN framework. Furthermore, we empirically demonstrate that it achieves better results. The empirical evaluation is performed on generated data from a complex physics problem on an interpolation and an extrapolation task. Using this dataset we compared seqKAN against a prior KAN network for timeseries prediction, recurrent deep networks, and symbolic regression. seqKAN substantially outperforms all architectures, particularly on the extrapolation dataset, while also being the most transparent.
Comparing Prior and Learned Time Representations in Transformer Models of Timeseries
Nov 19, 2024



What sets timeseries analysis apart from other machine learning exercises is that time representation becomes a primary aspect of the experiment setup, as it must adequately represent the temporal relations that are relevant for the application at hand. In the work described here we study wo different variations of the Transformer architecture: one where we use the fixed time representation proposed in the literature and one where the time representation is learned from the data. Our experiments use data from predicting the energy output of solar panels, a task that exhibits known periodicities (daily and seasonal) that is straight-forward to encode in the fixed time representation. Our results indicate that even in an experiment where the phenomenon is well-understood, it is difficult to encode prior knowledge due to side-effects that are difficult to mitigate. We conclude that research work is needed to work the human into the learning loop in ways that improve the robustness and trust-worthiness of the network.
Predicting Solar Heat Production to Optimize Renewable Energy Usage
May 16, 2024
Utilizing solar energy to meet space heating and domestic hot water demand is very efficient (in terms of environmental footprint as well as cost), but in order to ensure that user demand is entirely covered throughout the year needs to be complemented with auxiliary heating systems, typically boilers and heat pumps. Naturally, the optimal control of such a system depends on an accurate prediction of solar thermal production. Experimental testing and physics-based numerical models are used to find a collector's performance curve - the mapping from solar radiation and other external conditions to heat production - but this curve changes over time once the collector is exposed to outdoor conditions. In order to deploy advanced control strategies in small domestic installations, we present an approach that uses machine learning to automatically construct and continuously adapt a model that predicts heat production. Our design is driven by the need to (a) construct and adapt models using supervision that can be extracted from low-cost instrumentation, avoiding extreme accuracy and reliability requirements; and (b) at inference time, use inputs that are typically provided in publicly available weather forecasts. Recent developments in attention-based machine learning, as well as careful adaptation of the training setup to the specifics of the task, have allowed us to design a machine learning-based solution that covers our requirements. We present positive empirical results for the predictive accuracy of our solution, and discuss the impact of these results on the end-to-end system.
Depth-guided Free-space Segmentation for a Mobile Robot
Nov 03, 2023



Accurate indoor free-space segmentation is a challenging task due to the complexity and the dynamic nature that indoor environments exhibit. We propose an indoors free-space segmentation method that associates large depth values with navigable regions. Our method leverages an unsupervised masking technique that, using positive instances, generates segmentation labels based on textural homogeneity and depth uniformity. Moreover, we generate superpixels corresponding to areas of higher depth and align them with features extracted from a Dense Prediction Transformer (DPT). Using the estimated free-space masks and the DPT feature representation, a SegFormer model is fine-tuned on our custom-collected indoor dataset. Our experiments demonstrate sufficient performance in intricate scenarios characterized by cluttered obstacles and challenging identification of free space.
What's in a Name?
Oct 08, 2007



This paper describes experiments on identifying the language of a single name in isolation or in a document written in a different language. A new corpus has been compiled and made available, matching names against languages. This corpus is used in a series of experiments measuring the performance of general language models and names-only language models on the language identification task. Conclusions are drawn from the comparison between using general language models and names-only language models and between identifying the language of isolated names and the language of very short document fragments. Future research directions are outlined.
Learning Phonotactics Using ILP
Aug 11, 2007

This paper describes experiments on learning Dutch phonotactic rules using Inductive Logic Programming, a machine learning discipline based on inductive logical operators. Two different ways of approaching the problem are experimented with, and compared against each other as well as with related work on the task. The results show a direct correspondence between the quality and informedness of the background knowledge and the constructed theory, demonstrating the ability of ILP to take good advantage of the prior domain knowledge available. Further research is outlined.
A Data-Parallel Version of Aleph
Aug 10, 2007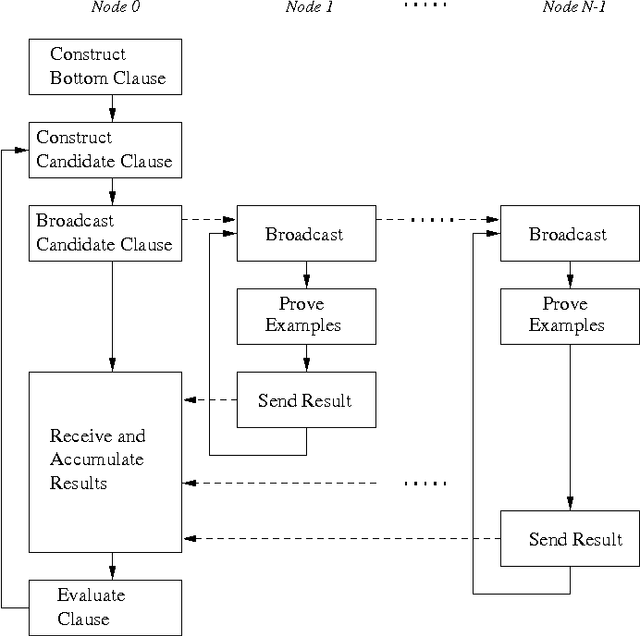
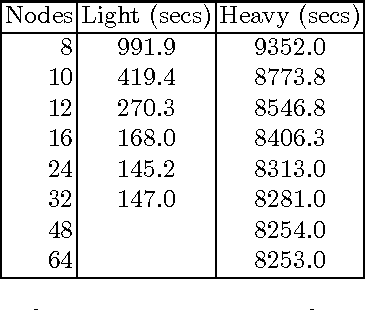
This is to present work on modifying the Aleph ILP system so that it evaluates the hypothesised clauses in parallel by distributing the data-set among the nodes of a parallel or distributed machine. The paper briefly discusses MPI, the interface used to access message- passing libraries for parallel computers and clusters. It then proceeds to describe an extension of YAP Prolog with an MPI interface and an implementation of data-parallel clause evaluation for Aleph through this interface. The paper concludes by testing the data-parallel Aleph on artificially constructed data-sets.
Learning Computational Grammars
Jul 15, 2001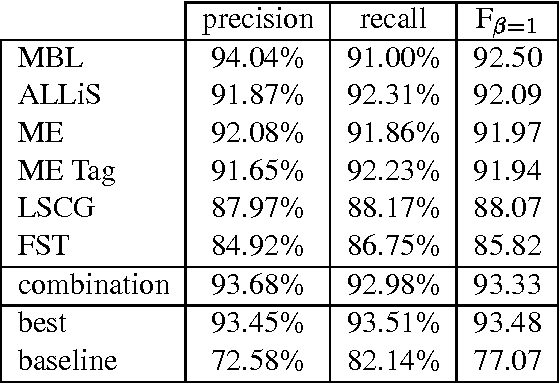
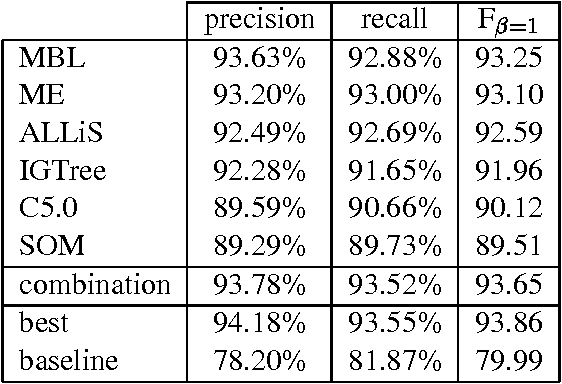
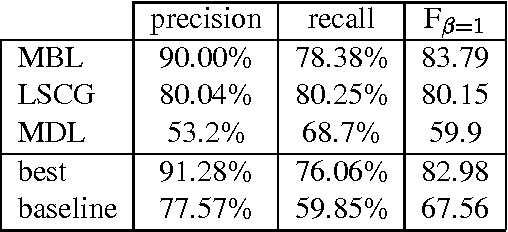
This paper reports on the "Learning Computational Grammars" (LCG) project, a postdoc network devoted to studying the application of machine learning techniques to grammars suitable for computational use. We were interested in a more systematic survey to understand the relevance of many factors to the success of learning, esp. the availability of annotated data, the kind of dependencies in the data, and the availability of knowledge bases (grammars). We focused on syntax, esp. noun phrase (NP) syntax.