 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence-Based Extractive Summarisation for Scientific Articles
Apr 07, 2022
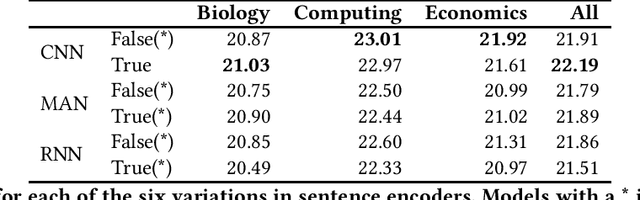
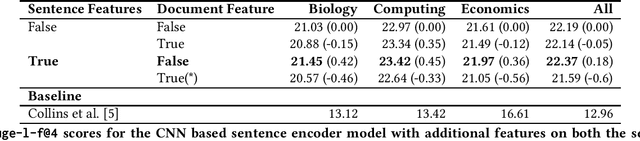

This paper presents the results of research on supervised extractive text summarisation for scientific articles. We show that a simple sequential tagging model based only on the text within a document achieves high results against a simple classification model. Improvements can be achieved through additional sentence-level features, though these were minimal. Through further analysis, we show the potential of the sequential model relying on the structure of the document depending on the academic discipline which the document is from.
Elsevier OA CC-By Corpus
Sep 15, 2020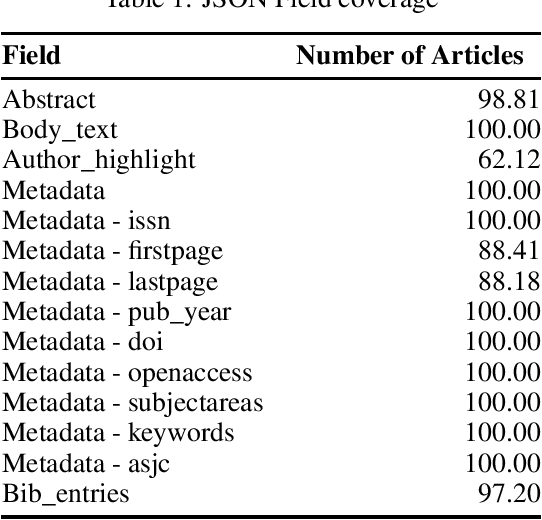
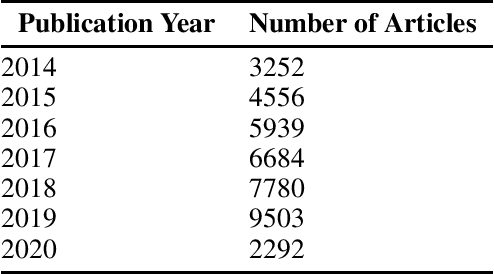

We introduce the Elsevier OA CC-BY corpus. This is the first open corpus of Scientific Research papers which has a representative sample from across scientific disciplines. This corpus not only includes the full text of the article, but also the metadata of the documents, along with the bibliographic information for each reference.
Learning Computational Grammars
Jul 15, 2001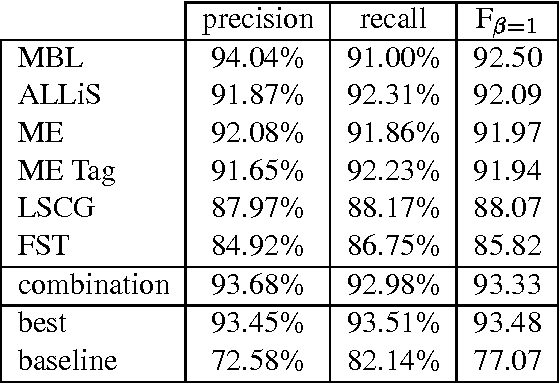
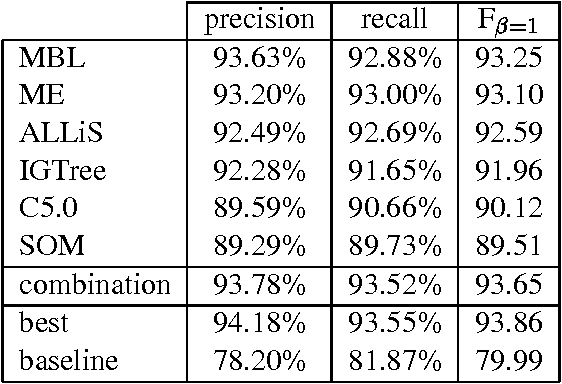
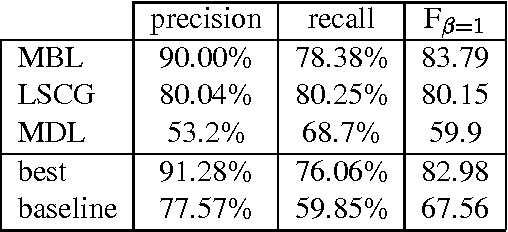
This paper reports on the "Learning Computational Grammars" (LCG) project, a postdoc network devoted to studying the application of machine learning techniques to grammars suitable for computational use. We were interested in a more systematic survey to understand the relevance of many factors to the success of learning, esp. the availability of annotated data, the kind of dependencies in the data, and the availability of knowledge bases (grammars). We focused on syntax, esp. noun phrase (NP) syntax.
Applying System Combination to Base Noun Phrase Identification
Aug 17, 2000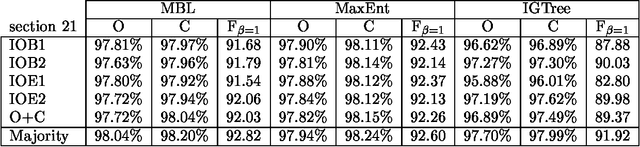
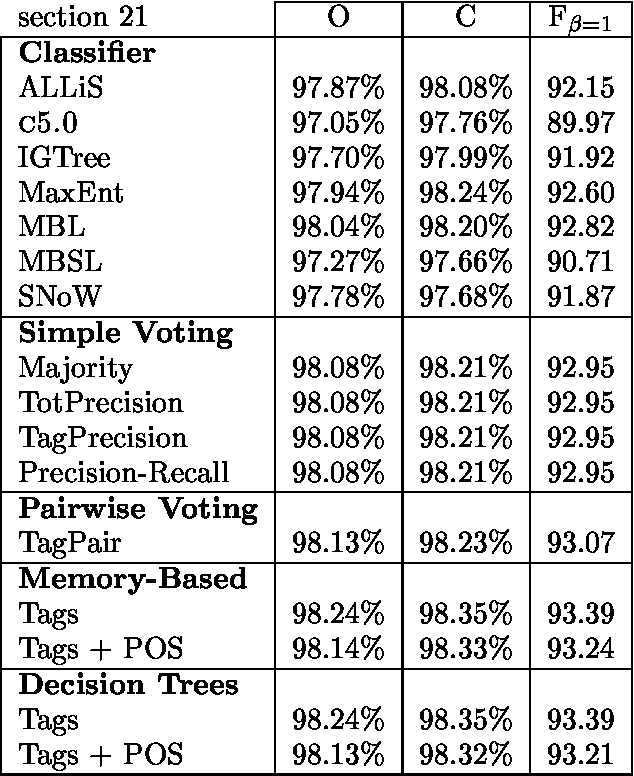

We use seven machine learning algorithms for one task: identifying base noun phrases. The results have been processed by different system combination methods and all of these outperformed the best individual result. We have applied the seven learners with the best combinator, a majority vote of the top five systems, to a standard data set and managed to improve the best published result for this data set.
* 7 pages
Robust Grammatical Analysis for Spoken Dialogue Systems
Jun 25, 1999
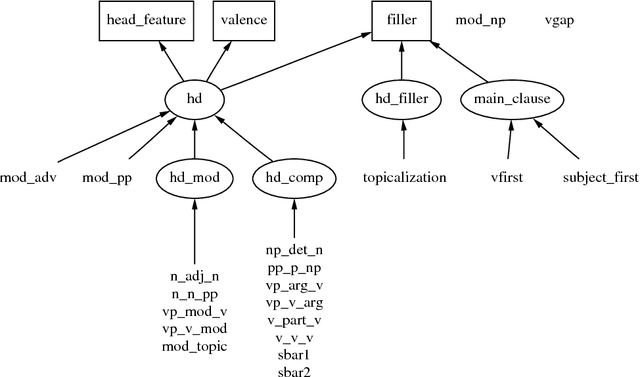
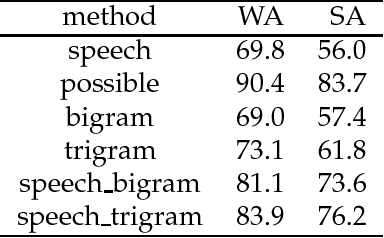
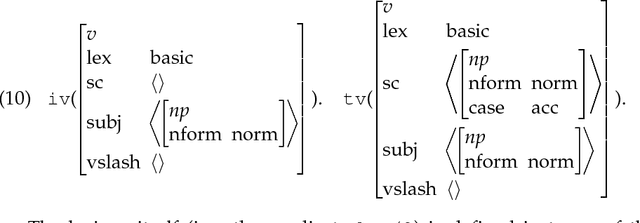
We argue that grammatical analysis is a viable alternative to concept spotting for processing spoken input in a practical spoken dialogue system. We discuss the structure of the grammar, and a model for robust parsing which combines linguistic sources of information and statistical sources of information. We discuss test results suggesting that grammatical processing allows fast and accurate processing of spoken input.
Grammatical analysis in the OVIS spoken-dialogue system
May 01, 1997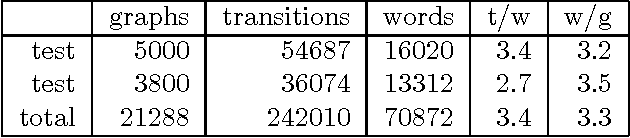
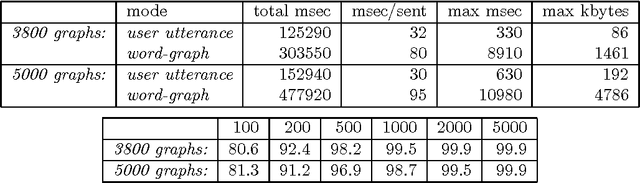
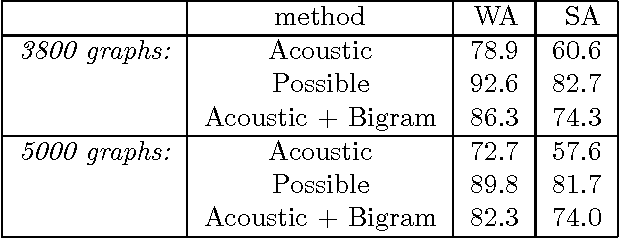
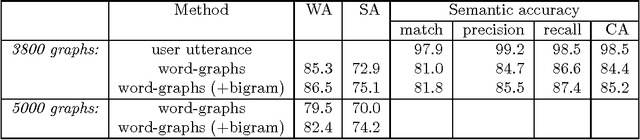
We argue that grammatical processing is a viable alternative to concept spotting for processing spoken input in a practical dialogue system. We discuss the structure of the grammar, the properties of the parser, and a method for achieving robustness. We discuss test results suggesting that grammatical processing allows fast and accurate processing of spoken input.
* 8 pages, uses aclap.sty