 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence-Based Extractive Summarisation for Scientific Articles
Apr 07, 2022
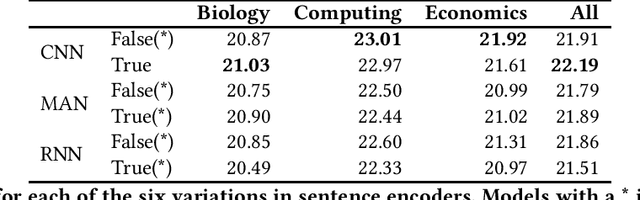
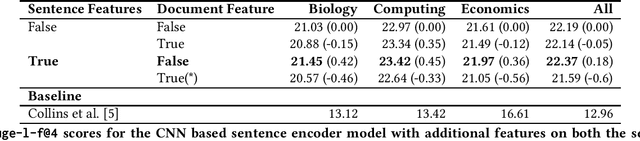

This paper presents the results of research on supervised extractive text summarisation for scientific articles. We show that a simple sequential tagging model based only on the text within a document achieves high results against a simple classification model. Improvements can be achieved through additional sentence-level features, though these were minimal. Through further analysis, we show the potential of the sequential model relying on the structure of the document depending on the academic discipline which the document is from.
Elsevier OA CC-By Corpus
Sep 15, 2020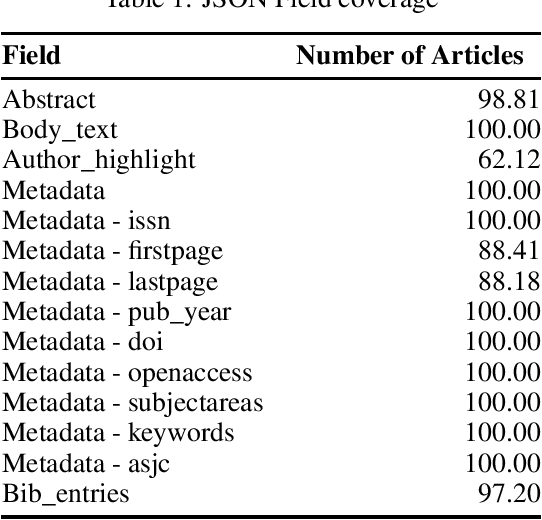
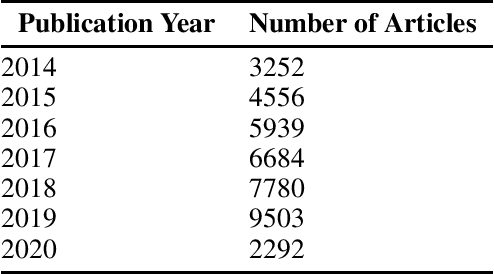

We introduce the Elsevier OA CC-BY corpus. This is the first open corpus of Scientific Research papers which has a representative sample from across scientific disciplines. This corpus not only includes the full text of the article, but also the metadata of the documents, along with the bibliographic information for each reference.