 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Computational Grammars
Jul 15, 2001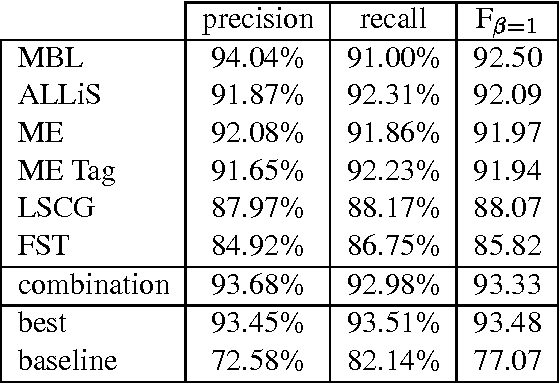
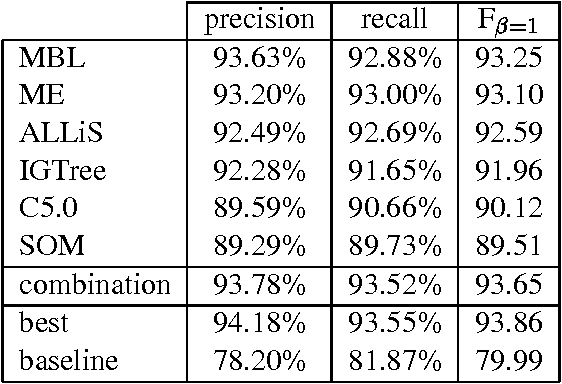
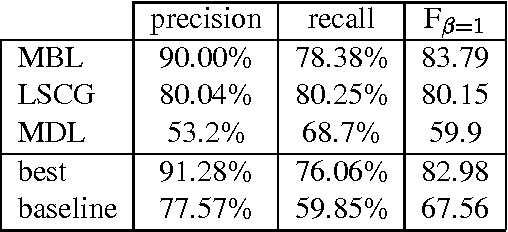
This paper reports on the "Learning Computational Grammars" (LCG) project, a postdoc network devoted to studying the application of machine learning techniques to grammars suitable for computational use. We were interested in a more systematic survey to understand the relevance of many factors to the success of learning, esp. the availability of annotated data, the kind of dependencies in the data, and the availability of knowledge bases (grammars). We focused on syntax, esp. noun phrase (NP) syntax.
Introduction to the CoNLL-2001 Shared Task: Clause Identification
Jul 15, 2001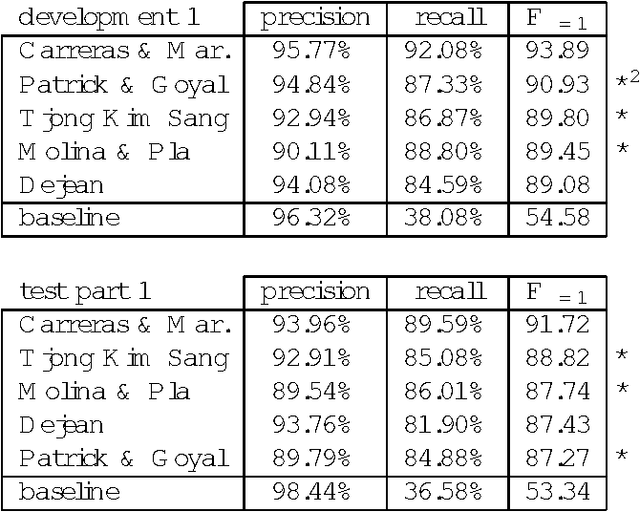


We describe the CoNLL-2001 shared task: dividing text into clauses. We give background information on the data sets, present a general overview of the systems that have taken part in the shared task and briefly discuss their performance.
Applying System Combination to Base Noun Phrase Identification
Aug 17, 2000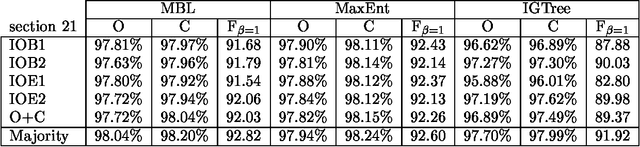
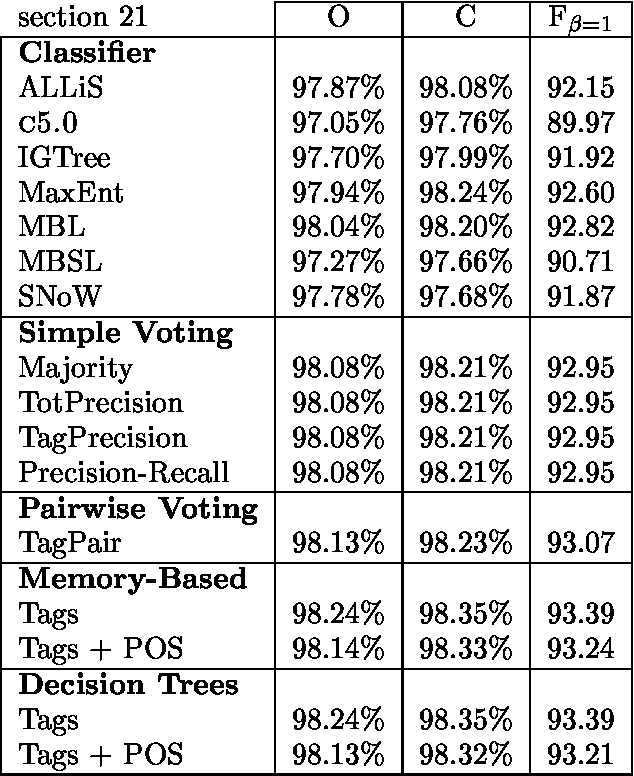

We use seven machine learning algorithms for one task: identifying base noun phrases. The results have been processed by different system combination methods and all of these outperformed the best individual result. We have applied the seven learners with the best combinator, a majority vote of the top five systems, to a standard data set and managed to improve the best published result for this data set.
* 7 pages