 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrating LLM Judges: Linear Probes for Fast and Reliable Uncertainty Estimation
Dec 23, 2025As LLM-based judges become integral to industry applications, obtaining well-calibrated uncertainty estimates efficiently has become critical for production deployment. However, existing techniques, such as verbalized confidence and multi-generation methods, are often either poorly calibrated or computationally expensive. We introduce linear probes trained with a Brier score-based loss to provide calibrated uncertainty estimates from reasoning judges' hidden states, requiring no additional model training. We evaluate our approach on both objective tasks (reasoning, mathematics, factuality, coding) and subjective human preference judgments. Our results demonstrate that probes achieve superior calibration compared to existing methods with $\approx10$x computational savings, generalize robustly to unseen evaluation domains, and deliver higher accuracy on high-confidence predictions. However, probes produce conservative estimates that underperform on easier datasets but may benefit safety-critical deployments prioritizing low false-positive rates. Overall, our work demonstrates that interpretability-based uncertainty estimation provides a practical and scalable plug-and-play solution for LLM judges in production.
AI Research Agents for Machine Learning: Search, Exploration, and Generalization in MLE-bench
Jul 03, 2025AI research agents are demonstrating great potential to accelerate scientific progress by automating the design, implementation, and training of machine learning models. We focus on methods for improving agents' performance on MLE-bench, a challenging benchmark where agents compete in Kaggle competitions to solve real-world machine learning problems. We formalize AI research agents as search policies that navigate a space of candidate solutions, iteratively modifying them using operators. By designing and systematically varying different operator sets and search policies (Greedy, MCTS, Evolutionary), we show that their interplay is critical for achieving high performance. Our best pairing of search strategy and operator set achieves a state-of-the-art result on MLE-bench lite, increasing the success rate of achieving a Kaggle medal from 39.6% to 47.7%. Our investigation underscores the importance of jointly considering the search strategy, operator design, and evaluation methodology in advancing automated machine learning.
Don't Make It Up: Preserving Ignorance Awareness in LLM Fine-Tuning
Jun 17, 2025Existing work on mitigating catastrophic forgetting in large language model (LLM) fine-tuning has primarily focused on preserving specific data or tasks, while critically overlooking the degradation of essential capabilities instilled through safety alignment, particularly the model's ability to faithfully express ignorance. In this work, we show that this capability is significantly degraded during conventional fine-tuning, leading to undesired behaviors such as hallucinations. To address this novel but highly practical problem, we propose SEAT, a simple and effective fine-tuning approach that preserves both fine-tuning performance and the model's inherent ability to acknowledge its ignorance. SEAT integrates two key components: (1) sparse training that constrains activation drift, and (2) a novel entity perturbation method with KL-divergence regularization, designed to counter knowledge entanglement. Experimental results demonstrate that SEAT significantly outperforms baselines in preserving ignorance awareness while retaining fine-tuning performance, offering a more robust solution for LLM fine-tuning.
HalluLens: LLM Hallucination Benchmark
Apr 24, 2025



Large language models (LLMs) often generate responses that deviate from user input or training data, a phenomenon known as "hallucination." These hallucinations undermine user trust and hinder the adoption of generative AI systems. Addressing hallucinations is essential for the advancement of LLMs. This paper introduces a comprehensive hallucination benchmark, incorporating both new extrinsic and existing intrinsic evaluation tasks, built upon clear taxonomy of hallucination. A major challenge in benchmarking hallucinations is the lack of a unified framework due to inconsistent definitions and categorizations. We disentangle LLM hallucination from "factuality," proposing a clear taxonomy that distinguishes between extrinsic and intrinsic hallucinations, to promote consistency and facilitate research. Extrinsic hallucinations, where the generated content is not consistent with the training data, are increasingly important as LLMs evolve. Our benchmark includes dynamic test set generation to mitigate data leakage and ensure robustness against such leakage. We also analyze existing benchmarks, highlighting their limitations and saturation. The work aims to: (1) establish a clear taxonomy of hallucinations, (2) introduce new extrinsic hallucination tasks, with data that can be dynamically regenerated to prevent saturation by leakage, (3) provide a comprehensive analysis of existing benchmarks, distinguishing them from factuality evaluations.
Calibrating Verbal Uncertainty as a Linear Feature to Reduce Hallucinations
Mar 18, 2025



LLMs often adopt an assertive language style also when making false claims. Such ``overconfident hallucinations'' mislead users and erode trust. Achieving the ability to express in language the actual degree of uncertainty around a claim is therefore of great importance. We find that ``verbal uncertainty'' is governed by a single linear feature in the representation space of LLMs, and show that this has only moderate correlation with the actual ``semantic uncertainty'' of the model. We apply this insight and show that (1) the mismatch between semantic and verbal uncertainty is a better predictor of hallucinations than semantic uncertainty alone and (2) we can intervene on verbal uncertainty at inference time and reduce hallucinations on short-form answers, achieving an average relative reduction of 32%.
LUNAR: LLM Unlearning via Neural Activation Redirection
Feb 11, 2025Large Language Models (LLMs) benefit from training on ever larger amounts of textual data, but as a result, they increasingly incur the risk of leaking private information. The ability to selectively remove knowledge from LLMs is, therefore, a highly desirable capability. In this paper, we propose LUNAR, a novel unlearning methodology grounded in the Linear Representation Hypothesis. LUNAR operates by redirecting the representations of unlearned data to regions that trigger the model's inherent ability to express its inability to answer. LUNAR achieves state-of-the-art unlearning performance while significantly enhancing the controllability of the unlearned model during inference. Specifically, LUNAR achieves between 2.9x to 11.7x improvements on combined "unlearning efficacy" and "model utility" score ("Deviation Score") on the PISTOL dataset across various base models. We also demonstrate, through quantitative analysis and qualitative examples, LUNAR's superior controllability in generating coherent and contextually aware responses, mitigating undesired side effects of existing methods. Moreover, we demonstrate that LUNAR is robust against white-box adversarial attacks and versatile in handling real-world scenarios, such as processing sequential unlearning requests.
Robust LLM safeguarding via refusal feature adversarial training
Sep 30, 2024

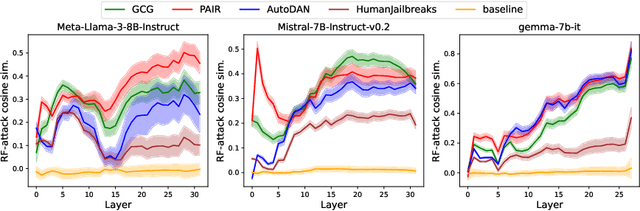

Large language models (LLMs) are vulnerable to adversarial attacks that can elicit harmful responses. Defending against such attacks remains challenging due to the opacity of jailbreaking mechanisms and the high computational cost of training LLMs robustly. We demonstrate that adversarial attacks share a universal mechanism for circumventing LLM safeguards that works by ablating a dimension in the residual stream embedding space called the refusal feature. We further show that the operation of refusal feature ablation (RFA) approximates the worst-case perturbation of offsetting model safety. Based on these findings, we propose Refusal Feature Adversarial Training (ReFAT), a novel algorithm that efficiently performs LLM adversarial training by simulating the effect of input-level attacks via RFA. Experiment results show that ReFAT significantly improves the robustness of three popular LLMs against a wide range of adversarial attacks, with considerably less computational overhead compared to existing adversarial training methods.
Source2Synth: Synthetic Data Generation and Curation Grounded in Real Data Sources
Sep 12, 2024



Large Language Models still struggle in challenging scenarios that leverage structured data, complex reasoning, or tool usage. In this paper, we propose Source2Synth: a new method that can be used for teaching LLMs new skills without relying on costly human annotations. Source2Synth takes as input a custom data source and produces synthetic data points with intermediate reasoning steps grounded in real-world sources. Source2Synth improves the dataset quality by discarding low-quality generations based on their answerability. We demonstrate the generality of this approach by applying it to two challenging domains: we test reasoning abilities in multi-hop question answering (MHQA), and tool usage in tabular question answering (TQA). Our method improves performance by 25.51% for TQA on WikiSQL and 22.57% for MHQA on HotPotQA compared to the fine-tuned baselines.
PISTOL: Dataset Compilation Pipeline for Structural Unlearning of LLMs
Jun 24, 2024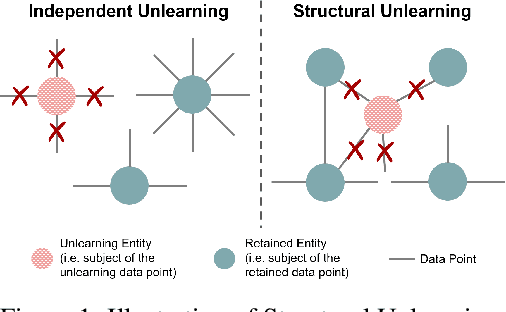
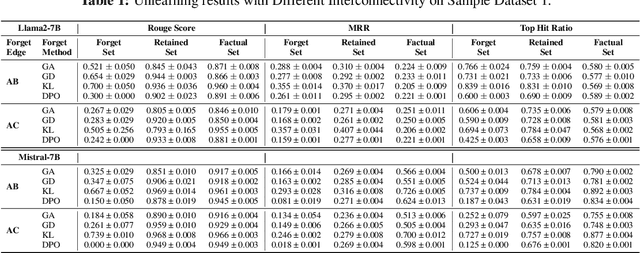

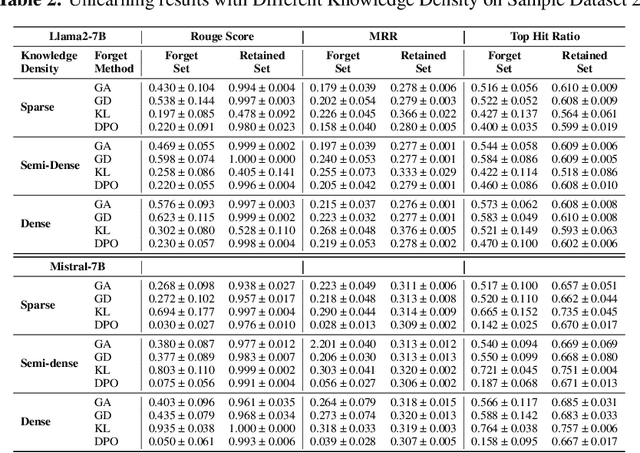
Recently, machine unlearning, which seeks to erase specific data stored in the pre-trained or fine-tuned models, has emerged as a crucial protective measure for LLMs. However, unlearning approaches for LLMs that have been considered thus far have focused on the removal of independent data points and have not taken into account that the stored facts are logically connected to one another and form an implicit knowledge graph. To facilitate the development of structural unlearning methods, which are essential for the practical application of unlearning, we propose PISTOL, a pipeline for compiling multi-scenario datasets for benchmarking structural LLM unlearning. Additionally, leveraging sample datasets synthesized using PISTOL, we conducted benchmarks with four distinct unlearning methods on both Llama2-7B and Mistral-7B models. This analysis helps to illustrate the prevailing challenges in effectively and robustly removing highly inter-connected data, batched data, or data skewed towards a specific domain. It also highlights the choice of pre-trained model can impact unlearning performance. This work not only advances our understandings on the limitation of current LLMs unlearning methods and proposes future research directions, but also provides a replicable framework for ongoing exploration and validation in the field.
Know When To Stop: A Study of Semantic Drift in Text Generation
Apr 08, 2024
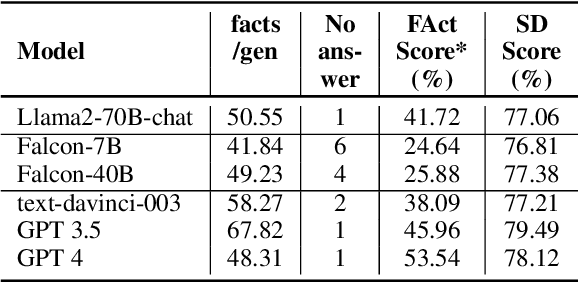

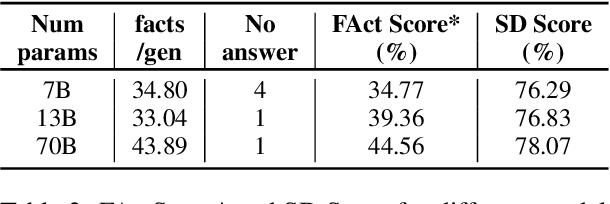
In this work, we explicitly show that modern LLMs tend to generate correct facts first, then "drift away" and generate incorrect facts later: this was occasionally observed but never properly measured. We develop a semantic drift score that measures the degree of separation between correct and incorrect facts in generated texts and confirm our hypothesis when generating Wikipedia-style biographies. This correct-then-incorrect generation pattern suggests that factual accuracy can be improved by knowing when to stop generation. Therefore, we explore the trade-off between information quantity and factual accuracy for several early stopping methods and manage to improve factuality by a large margin. We further show that reranking with semantic similarity can further improve these results, both compared to the baseline and when combined with early stopping. Finally, we try calling external API to bring the model back to the right generation path, but do not get positive results. Overall, our methods generalize and can be applied to any long-form text generation to produce more reliable information, by balancing trade-offs between factual accuracy, information quantity and computational cost.