 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Souper-Model: How Simple Arithmetic Unlocks State-of-the-Art LLM Performance
Nov 17, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities across diverse domains, but their training remains resource- and time-intensive, requiring massive compute power and careful orchestration of training procedures. Model souping-the practice of averaging weights from multiple models of the same architecture-has emerged as a promising pre- and post-training technique that can enhance performance without expensive retraining. In this paper, we introduce Soup Of Category Experts (SoCE), a principled approach for model souping that utilizes benchmark composition to identify optimal model candidates and applies non-uniform weighted averaging to maximize performance. Contrary to previous uniform-averaging approaches, our method leverages the observation that benchmark categories often exhibit low inter-correlations in model performance. SoCE identifies "expert" models for each weakly-correlated category cluster and combines them using optimized weighted averaging rather than uniform weights. We demonstrate that the proposed method improves performance and robustness across multiple domains, including multilingual capabilities, tool calling, and math and achieves state-of-the-art results on the Berkeley Function Calling Leaderboard.
AI Research Agents for Machine Learning: Search, Exploration, and Generalization in MLE-bench
Jul 03, 2025AI research agents are demonstrating great potential to accelerate scientific progress by automating the design, implementation, and training of machine learning models. We focus on methods for improving agents' performance on MLE-bench, a challenging benchmark where agents compete in Kaggle competitions to solve real-world machine learning problems. We formalize AI research agents as search policies that navigate a space of candidate solutions, iteratively modifying them using operators. By designing and systematically varying different operator sets and search policies (Greedy, MCTS, Evolutionary), we show that their interplay is critical for achieving high performance. Our best pairing of search strategy and operator set achieves a state-of-the-art result on MLE-bench lite, increasing the success rate of achieving a Kaggle medal from 39.6% to 47.7%. Our investigation underscores the importance of jointly considering the search strategy, operator design, and evaluation methodology in advancing automated machine learning.
LLM-First Search: Self-Guided Exploration of the Solution Space
Jun 05, 2025Large Language Models (LLMs) have demonstrated remarkable improvements in reasoning and planning through increased test-time compute, often by framing problem-solving as a search process. While methods like Monte Carlo Tree Search (MCTS) have proven effective in some domains, their reliance on fixed exploration hyperparameters limits their adaptability across tasks of varying difficulty, rendering them impractical or expensive in certain settings. In this paper, we propose \textbf{LLM-First Search (LFS)}, a novel \textit{LLM Self-Guided Search} method that removes the need for pre-defined search strategies by empowering the LLM to autonomously control the search process via self-guided exploration. Rather than relying on external heuristics or hardcoded policies, the LLM evaluates whether to pursue the current search path or explore alternative branches based on its internal scoring mechanisms. This enables more flexible and context-sensitive reasoning without requiring manual tuning or task-specific adaptation. We evaluate LFS on Countdown and Sudoku against three classic widely-used search algorithms, Tree-of-Thoughts' Breadth First Search (ToT-BFS), Best First Search (BestFS), and MCTS, each of which have been used to achieve SotA results on a range of challenging reasoning tasks. We found that LFS (1) performs better on more challenging tasks without additional tuning, (2) is more computationally efficient compared to the other methods, especially when powered by a stronger model, (3) scales better with stronger models, due to its LLM-First design, and (4) scales better with increased compute budget. Our code is publicly available at \href{https://github.com/NathanHerr/LLM-First-Search}{LLM-First-Search}.
MLGym: A New Framework and Benchmark for Advancing AI Research Agents
Feb 20, 2025



We introduce Meta MLGym and MLGym-Bench, a new framework and benchmark for evaluating and developing LLM agents on AI research tasks. This is the first Gym environment for machine learning (ML) tasks, enabling research on reinforcement learning (RL) algorithms for training such agents. MLGym-bench consists of 13 diverse and open-ended AI research tasks from diverse domains such as computer vision, natural language processing, reinforcement learning, and game theory. Solving these tasks requires real-world AI research skills such as generating new ideas and hypotheses, creating and processing data, implementing ML methods, training models, running experiments, analyzing the results, and iterating through this process to improve on a given task. We evaluate a number of frontier large language models (LLMs) on our benchmarks such as Claude-3.5-Sonnet, Llama-3.1 405B, GPT-4o, o1-preview, and Gemini-1.5 Pro. Our MLGym framework makes it easy to add new tasks, integrate and evaluate models or agents, generate synthetic data at scale, as well as develop new learning algorithms for training agents on AI research tasks. We find that current frontier models can improve on the given baselines, usually by finding better hyperparameters, but do not generate novel hypotheses, algorithms, architectures, or substantial improvements. We open-source our framework and benchmark to facilitate future research in advancing the AI research capabilities of LLM agents.
MaestroMotif: Skill Design from Artificial Intelligence Feedback
Dec 11, 2024
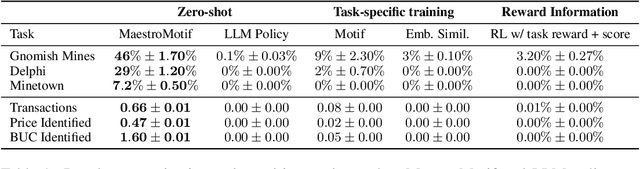

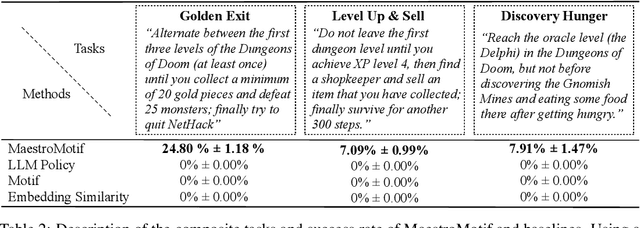
Describing skills in natural language has the potential to provide an accessible way to inject human knowledge about decision-making into an AI system. We present MaestroMotif, a method for AI-assisted skill design, which yields high-performing and adaptable agents. MaestroMotif leverages the capabilities of Large Language Models (LLMs) to effectively create and reuse skills. It first uses an LLM's feedback to automatically design rewards corresponding to each skill, starting from their natural language description. Then, it employs an LLM's code generation abilities, together with reinforcement learning, for training the skills and combining them to implement complex behaviors specified in language. We evaluate MaestroMotif using a suite of complex tasks in the NetHack Learning Environment (NLE), demonstrating that it surpasses existing approaches in both performance and usability.
Source2Synth: Synthetic Data Generation and Curation Grounded in Real Data Sources
Sep 12, 2024



Large Language Models still struggle in challenging scenarios that leverage structured data, complex reasoning, or tool usage. In this paper, we propose Source2Synth: a new method that can be used for teaching LLMs new skills without relying on costly human annotations. Source2Synth takes as input a custom data source and produces synthetic data points with intermediate reasoning steps grounded in real-world sources. Source2Synth improves the dataset quality by discarding low-quality generations based on their answerability. We demonstrate the generality of this approach by applying it to two challenging domains: we test reasoning abilities in multi-hop question answering (MHQA), and tool usage in tabular question answering (TQA). Our method improves performance by 25.51% for TQA on WikiSQL and 22.57% for MHQA on HotPotQA compared to the fine-tuned baselines.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Are Large Language Models Strategic Decision Makers? A Study of Performance and Bias in Two-Player Non-Zero-Sum Games
Jul 05, 2024



Large Language Models (LLMs) have been increasingly used in real-world settings, yet their strategic abilities remain largely unexplored. Game theory provides a good framework for assessing the decision-making abilities of LLMs in interactions with other agents. Although prior studies have shown that LLMs can solve these tasks with carefully curated prompts, they fail when the problem setting or prompt changes. In this work we investigate LLMs' behaviour in strategic games, Stag Hunt and Prisoner Dilemma, analyzing performance variations under different settings and prompts. Our results show that the tested state-of-the-art LLMs exhibit at least one of the following systematic biases: (1) positional bias, (2) payoff bias, or (3) behavioural bias. Subsequently, we observed that the LLMs' performance drops when the game configuration is misaligned with the affecting biases. Performance is assessed based on the selection of the correct action, one which agrees with the prompted preferred behaviours of both players. Alignment refers to whether the LLM's bias aligns with the correct action. For example, GPT-4o's average performance drops by 34% when misaligned. Additionally, the current trend of "bigger and newer is better" does not hold for the above, where GPT-4o (the current best-performing LLM) suffers the most substantial performance drop. Lastly, we note that while chain-of-thought prompting does reduce the effect of the biases on most models, it is far from solving the problem at the fundamental level.
DreamCraft: Text-Guided Generation of Functional 3D Environments in Minecraft
Apr 23, 2024Procedural Content Generation (PCG) algorithms enable the automatic generation of complex and diverse artifacts. However, they don't provide high-level control over the generated content and typically require domain expertise. In contrast, text-to-3D methods allow users to specify desired characteristics in natural language, offering a high amount of flexibility and expressivity. But unlike PCG, such approaches cannot guarantee functionality, which is crucial for certain applications like game design. In this paper, we present a method for generating functional 3D artifacts from free-form text prompts in the open-world game Minecraft. Our method, DreamCraft, trains quantized Neural Radiance Fields (NeRFs) to represent artifacts that, when viewed in-game, match given text descriptions. We find that DreamCraft produces more aligned in-game artifacts than a baseline that post-processes the output of an unconstrained NeRF. Thanks to the quantized representation of the environment, functional constraints can be integrated using specialized loss terms. We show how this can be leveraged to generate 3D structures that match a target distribution or obey certain adjacency rules over the block types. DreamCraft inherits a high degree of expressivity and controllability from the NeRF, while still being able to incorporate functional constraints through domain-specific objectives.