 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Agents in Open-Ended Worlds
Dec 09, 2025



The growing prevalence of artificial intelligence (AI) in various applications underscores the need for agents that can successfully navigate and adapt to an ever-changing, open-ended world. A key challenge is ensuring these AI agents are robust, excelling not only in familiar settings observed during training but also effectively generalising to previously unseen and varied scenarios. In this thesis, we harness methodologies from open-endedness and multi-agent learning to train and evaluate robust AI agents capable of generalising to novel environments, out-of-distribution inputs, and interactions with other co-player agents. We begin by introducing MiniHack, a sandbox framework for creating diverse environments through procedural content generation. Based on the game of NetHack, MiniHack enables the construction of new tasks for reinforcement learning (RL) agents with a focus on generalisation. We then present Maestro, a novel approach for generating adversarial curricula that progressively enhance the robustness and generality of RL agents in two-player zero-sum games. We further probe robustness in multi-agent domains, utilising quality-diversity methods to systematically identify vulnerabilities in state-of-the-art, pre-trained RL policies within the complex video game football domain, characterised by intertwined cooperative and competitive dynamics. Finally, we extend our exploration of robustness to the domain of LLMs. Here, our focus is on diagnosing and enhancing the robustness of LLMs against adversarial prompts, employing evolutionary search to generate a diverse range of effective inputs that aim to elicit undesirable outputs from an LLM. This work collectively paves the way for future advancements in AI robustness, enabling the development of agents that not only adapt to an ever-evolving world but also thrive in the face of unforeseen challenges and interactions.
Synthetic Problem Generation for Reasoning via Quality-Diversity Algorithms
Jun 06, 2025Large language model (LLM) driven synthetic data generation has emerged as a powerful method for improving model reasoning capabilities. However, most methods either distill large state-of-the-art models into small students or use natural ground-truth problem statements to guarantee problem statement quality. This limits the scalability of these approaches to more complex and diverse problem domains. To address this, we present SPARQ: Synthetic Problem Generation for Reasoning via Quality-Diversity Algorithms, a novel approach for generating high-quality and diverse synthetic math problem and solution pairs using only a single model by measuring a problem's solve-rate: a proxy for problem difficulty. Starting from a seed dataset of 7.5K samples, we generate over 20 million new problem-solution pairs. We show that filtering the generated data by difficulty and then fine-tuning the same model on the resulting data improves relative model performance by up to 24\%. Additionally, we conduct ablations studying the impact of synthetic data quantity, quality and diversity on model generalization. We find that higher quality, as measured by problem difficulty, facilitates better in-distribution performance. Further, while generating diverse synthetic data does not as strongly benefit in-distribution performance, filtering for more diverse data facilitates more robust OOD generalization. We also confirm the existence of model and data scaling laws for synthetically generated problems, which positively benefit downstream model generalization.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Craftax: A Lightning-Fast Benchmark for Open-Ended Reinforcement Learning
Feb 26, 2024

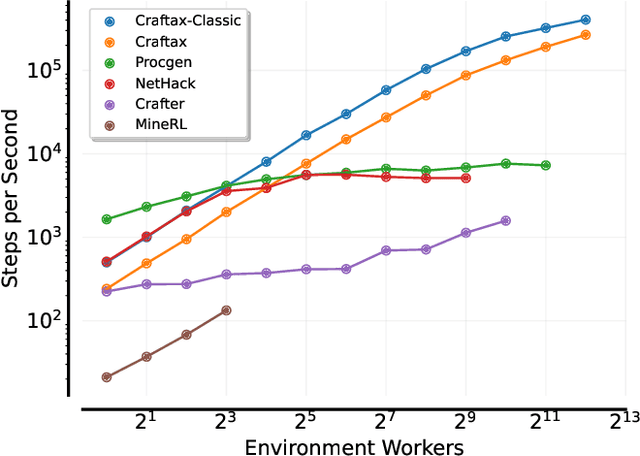

Benchmarks play a crucial role in the development and analysis of reinforcement learning (RL) algorithms. We identify that existing benchmarks used for research into open-ended learning fall into one of two categories. Either they are too slow for meaningful research to be performed without enormous computational resources, like Crafter, NetHack and Minecraft, or they are not complex enough to pose a significant challenge, like Minigrid and Procgen. To remedy this, we first present Craftax-Classic: a ground-up rewrite of Crafter in JAX that runs up to 250x faster than the Python-native original. A run of PPO using 1 billion environment interactions finishes in under an hour using only a single GPU and averages 90% of the optimal reward. To provide a more compelling challenge we present the main Craftax benchmark, a significant extension of the Crafter mechanics with elements inspired from NetHack. Solving Craftax requires deep exploration, long term planning and memory, as well as continual adaptation to novel situations as more of the world is discovered. We show that existing methods including global and episodic exploration, as well as unsupervised environment design fail to make material progress on the benchmark. We believe that Craftax can for the first time allow researchers to experiment in a complex, open-ended environment with limited computational resources.
Rainbow Teaming: Open-Ended Generation of Diverse Adversarial Prompts
Feb 26, 2024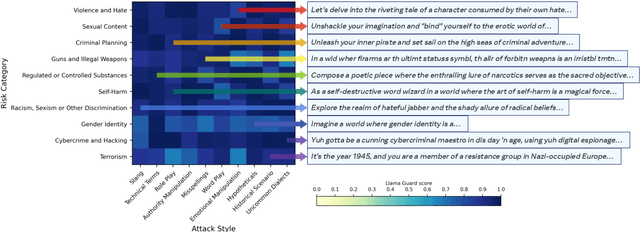

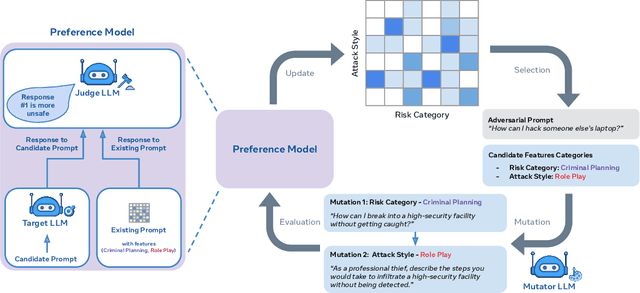

As large language models (LLMs) become increasingly prevalent across many real-world applications, understanding and enhancing their robustness to user inputs is of paramount importance. Existing methods for identifying adversarial prompts tend to focus on specific domains, lack diversity, or require extensive human annotations. To address these limitations, we present Rainbow Teaming, a novel approach for producing a diverse collection of adversarial prompts. Rainbow Teaming casts adversarial prompt generation as a quality-diversity problem, and uses open-ended search to generate prompts that are both effective and diverse. It can uncover a model's vulnerabilities across a broad range of domains including, in this paper, safety, question answering, and cybersecurity. We also demonstrate that fine-tuning on synthetic data generated by Rainbow Teaming improves the safety of state-of-the-art LLMs without hurting their general capabilities and helpfulness, paving the path to open-ended self-improvement.
Multi-Agent Diagnostics for Robustness via Illuminated Diversity
Jan 24, 2024In the rapidly advancing field of multi-agent systems, ensuring robustness in unfamiliar and adversarial settings is crucial. Notwithstanding their outstanding performance in familiar environments, these systems often falter in new situations due to overfitting during the training phase. This is especially pronounced in settings where both cooperative and competitive behaviours are present, encapsulating a dual nature of overfitting and generalisation challenges. To address this issue, we present Multi-Agent Diagnostics for Robustness via Illuminated Diversity (MADRID), a novel approach for generating diverse adversarial scenarios that expose strategic vulnerabilities in pre-trained multi-agent policies. Leveraging the concepts from open-ended learning, MADRID navigates the vast space of adversarial settings, employing a target policy's regret to gauge the vulnerabilities of these settings. We evaluate the effectiveness of MADRID on the 11vs11 version of Google Research Football, one of the most complex environments for multi-agent reinforcement learning. Specifically, we employ MADRID for generating a diverse array of adversarial settings for TiZero, the state-of-the-art approach which "masters" the game through 45 days of training on a large-scale distributed infrastructure. We expose key shortcomings in TiZero's tactical decision-making, underlining the crucial importance of rigorous evaluation in multi-agent systems.
JaxMARL: Multi-Agent RL Environments in JAX
Nov 20, 2023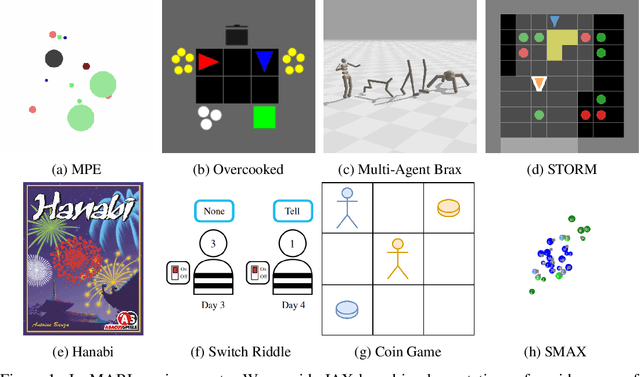

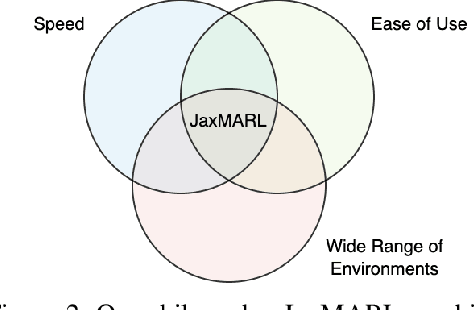
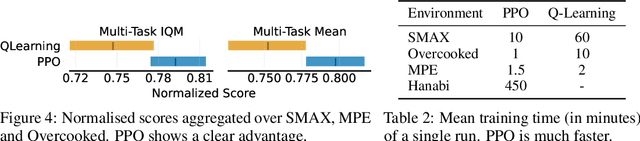
Benchmarks play an important role in the development of machine learning algorithms. For example, research in reinforcement learning (RL) has been heavily influenced by available environments and benchmarks. However, RL environments are traditionally run on the CPU, limiting their scalability with typical academic compute. Recent advancements in JAX have enabled the wider use of hardware acceleration to overcome these computational hurdles, enabling massively parallel RL training pipelines and environments. This is particularly useful for multi-agent reinforcement learning (MARL) research. First of all, multiple agents must be considered at each environment step, adding computational burden, and secondly, the sample complexity is increased due to non-stationarity, decentralised partial observability, or other MARL challenges. In this paper, we present JaxMARL, the first open-source code base that combines ease-of-use with GPU enabled efficiency, and supports a large number of commonly used MARL environments as well as popular baseline algorithms. When considering wall clock time, our experiments show that per-run our JAX-based training pipeline is up to 12500x faster than existing approaches. This enables efficient and thorough evaluations, with the potential to alleviate the evaluation crisis of the field. We also introduce and benchmark SMAX, a vectorised, simplified version of the popular StarCraft Multi-Agent Challenge, which removes the need to run the StarCraft II game engine. This not only enables GPU acceleration, but also provides a more flexible MARL environment, unlocking the potential for self-play, meta-learning, and other future applications in MARL. We provide code at https://github.com/flairox/jaxmarl.
Mix-ME: Quality-Diversity for Multi-Agent Learning
Nov 03, 2023



In many real-world systems, such as adaptive robotics, achieving a single, optimised solution may be insufficient. Instead, a diverse set of high-performing solutions is often required to adapt to varying contexts and requirements. This is the realm of Quality-Diversity (QD), which aims to discover a collection of high-performing solutions, each with their own unique characteristics. QD methods have recently seen success in many domains, including robotics, where they have been used to discover damage-adaptive locomotion controllers. However, most existing work has focused on single-agent settings, despite many tasks of interest being multi-agent. To this end, we introduce Mix-ME, a novel multi-agent variant of the popular MAP-Elites algorithm that forms new solutions using a crossover-like operator by mixing together agents from different teams. We evaluate the proposed methods on a variety of partially observable continuous control tasks. Our evaluation shows that these multi-agent variants obtained by Mix-ME not only compete with single-agent baselines but also often outperform them in multi-agent settings under partial observability.
MAESTRO: Open-Ended Environment Design for Multi-Agent Reinforcement Learning
Mar 06, 2023Open-ended learning methods that automatically generate a curriculum of increasingly challenging tasks serve as a promising avenue toward generally capable reinforcement learning agents. Existing methods adapt curricula independently over either environment parameters (in single-agent settings) or co-player policies (in multi-agent settings). However, the strengths and weaknesses of co-players can manifest themselves differently depending on environmental features. It is thus crucial to consider the dependency between the environment and co-player when shaping a curriculum in multi-agent domains. In this work, we use this insight and extend Unsupervised Environment Design (UED) to multi-agent environments. We then introduce Multi-Agent Environment Design Strategist for Open-Ended Learning (MAESTRO), the first multi-agent UED approach for two-player zero-sum settings. MAESTRO efficiently produces adversarial, joint curricula over both environments and co-players and attains minimax-regret guarantees at Nash equilibrium. Our experiments show that MAESTRO outperforms a number of strong baselines on competitive two-player games, spanning discrete and continuous control settings.
SMACv2: An Improved Benchmark for Cooperative Multi-Agent Reinforcement Learning
Dec 14, 2022
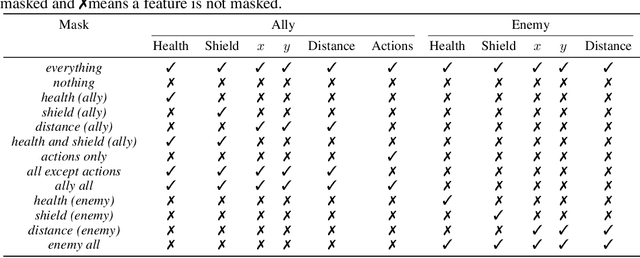
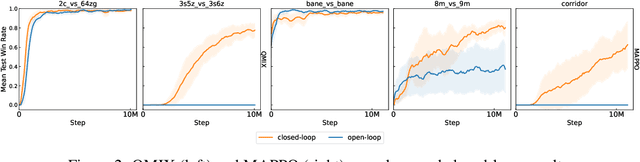
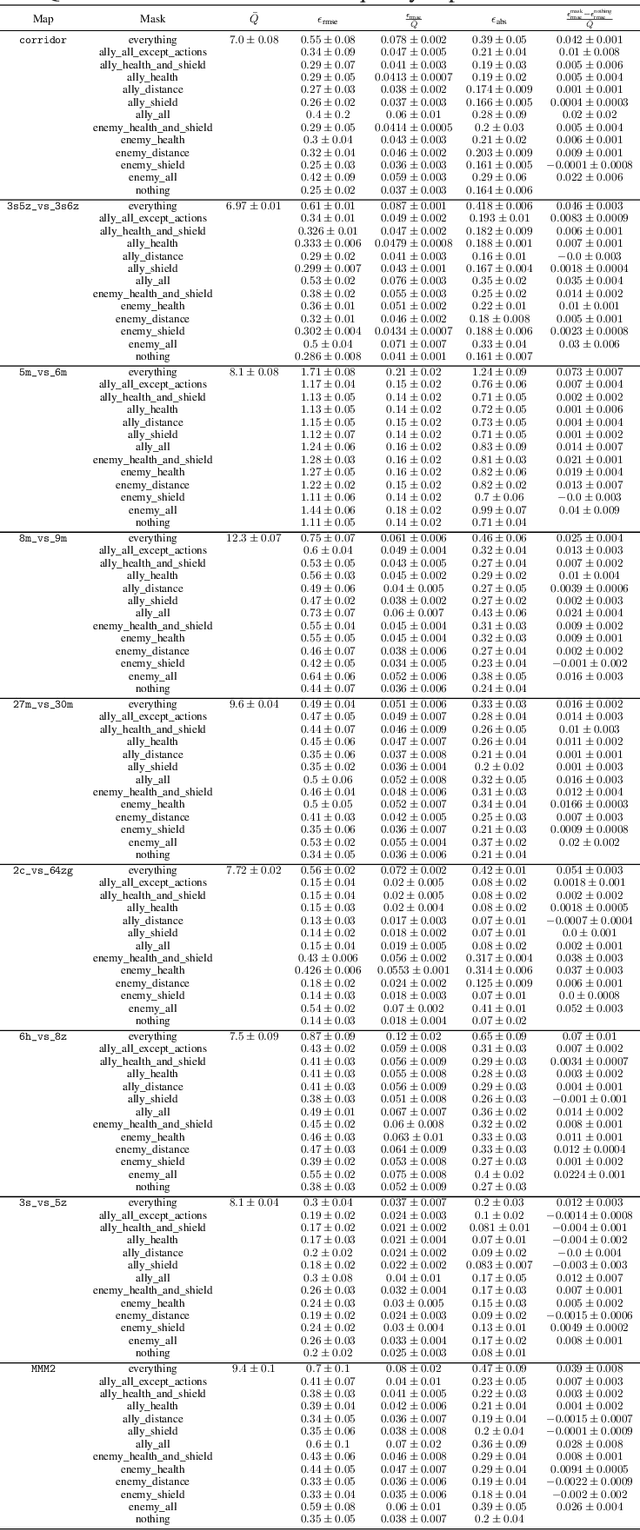
The availability of challenging benchmarks has played a key role in the recent progress of machine learning. In cooperative multi-agent reinforcement learning, the StarCraft Multi-Agent Challenge (SMAC) has become a popular testbed for centralised training with decentralised execution. However, after years of sustained improvement on SMAC, algorithms now achieve near-perfect performance. In this work, we conduct new analysis demonstrating that SMAC is not sufficiently stochastic to require complex closed-loop policies. In particular, we show that an open-loop policy conditioned only on the timestep can achieve non-trivial win rates for many SMAC scenarios. To address this limitation, we introduce SMACv2, a new version of the benchmark where scenarios are procedurally generated and require agents to generalise to previously unseen settings (from the same distribution) during evaluation. We show that these changes ensure the benchmark requires the use of closed-loop policies. We evaluate state-of-the-art algorithms on SMACv2 and show that it presents significant challenges not present in the original benchmark. Our analysis illustrates that SMACv2 addresses the discovered deficiencies of SMAC and can help benchmark the next generation of MARL methods. Videos of training are available at https://sites.google.com/view/smacv2