 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperVLA: Efficient Inference in Vision-Language-Action Models via Hypernetworks
Oct 06, 2025Built upon language and vision foundation models with strong generalization ability and trained on large-scale robotic data, Vision-Language-Action (VLA) models have recently emerged as a promising approach to learning generalist robotic policies. However, a key drawback of existing VLAs is their extremely high inference costs. In this paper, we propose HyperVLA to address this problem. Unlike existing monolithic VLAs that activate the whole model during both training and inference, HyperVLA uses a novel hypernetwork (HN)-based architecture that activates only a small task-specific policy during inference, while still retaining the high model capacity needed to accommodate diverse multi-task behaviors during training. Successfully training an HN-based VLA is nontrivial so HyperVLA contains several key algorithm design features that improve its performance, including properly utilizing the prior knowledge from existing vision foundation models, HN normalization, and an action generation strategy. Compared to monolithic VLAs, HyperVLA achieves a similar or even higher success rate for both zero-shot generalization and few-shot adaptation, while significantly reducing inference costs. Compared to OpenVLA, a state-of-the-art VLA model, HyperVLA reduces the number of activated parameters at test time by $90\times$, and accelerates inference speed by $120\times$. Code is publicly available at https://github.com/MasterXiong/HyperVLA
Online learning to accelerate nonlinear PDE solvers: applied to multiphase porous media flow
Apr 25, 2025



We propose a novel type of nonlinear solver acceleration for systems of nonlinear partial differential equations (PDEs) that is based on online/adaptive learning. It is applied in the context of multiphase flow in porous media. The proposed method rely on four pillars: (i) dimensionless numbers as input parameters for the machine learning model, (ii) simplified numerical model (two-dimensional) for the offline training, (iii) dynamic control of a nonlinear solver tuning parameter (numerical relaxation), (iv) and online learning for real-time improvement of the machine learning model. This strategy decreases the number of nonlinear iterations by dynamically modifying a single global parameter, the relaxation factor, and by adaptively learning the attributes of each numerical model on-the-run. Furthermore, this work performs a sensitivity study in the dimensionless parameters (machine learning features), assess the efficacy of various machine learning models, demonstrate a decrease in nonlinear iterations using our method in more intricate, realistic three-dimensional models, and fully couple a machine learning model into an open-source multiphase flow simulator achieving up to 85\% reduction in computational time.
Reinforcement Learning Controllers for Soft Robots using Learned Environments
Oct 25, 2024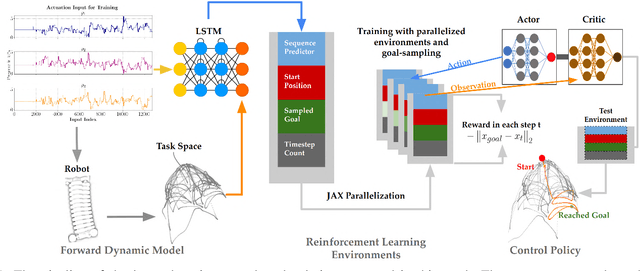
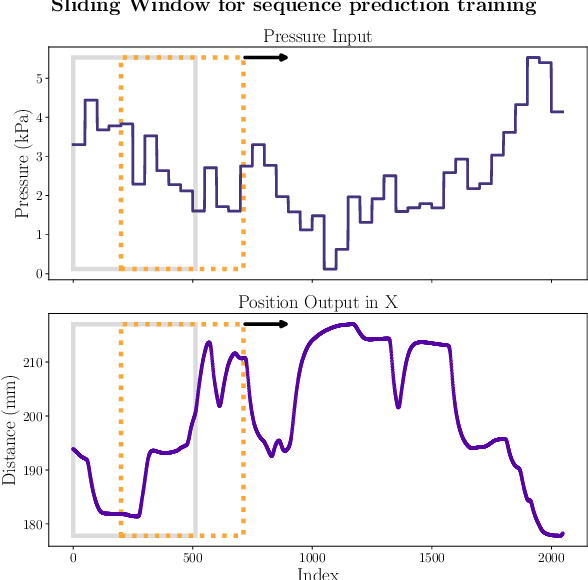
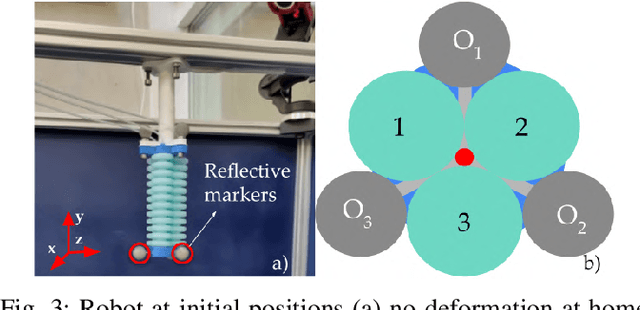
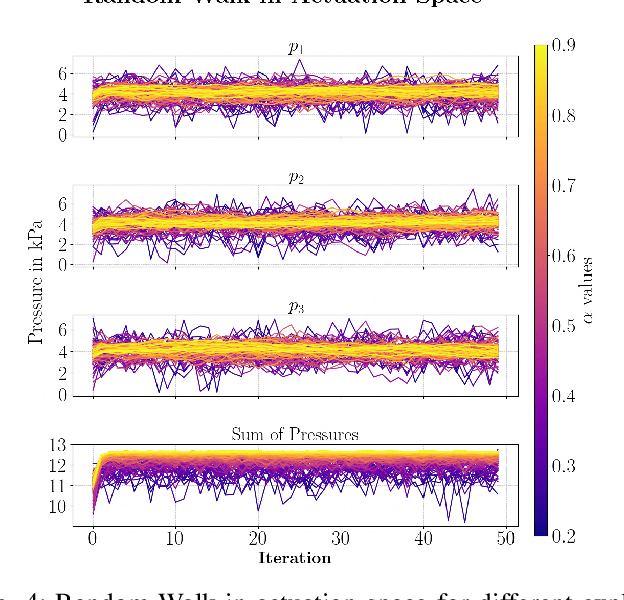
Soft robotic manipulators offer operational advantage due to their compliant and deformable structures. However, their inherently nonlinear dynamics presents substantial challenges. Traditional analytical methods often depend on simplifying assumptions, while learning-based techniques can be computationally demanding and limit the control policies to existing data. This paper introduces a novel approach to soft robotic control, leveraging state-of-the-art policy gradient methods within parallelizable synthetic environments learned from data. We also propose a safety oriented actuation space exploration protocol via cascaded updates and weighted randomness. Specifically, our recurrent forward dynamics model is learned by generating a training dataset from a physically safe \textit{mean reverting} random walk in actuation space to explore the partially-observed state-space. We demonstrate a reinforcement learning approach towards closed-loop control through state-of-the-art actor-critic methods, which efficiently learn high-performance behaviour over long horizons. This approach removes the need for any knowledge regarding the robot's operation or capabilities and sets the stage for a comprehensive benchmarking tool in soft robotics control.
* soft manipulator, reinforcement learning, learned controllers
Towards Reinforcement Learning Controllers for Soft Robots using Learned Environments
Oct 24, 2024Soft robotic manipulators offer operational advantage due to their compliant and deformable structures. However, their inherently nonlinear dynamics presents substantial challenges. Traditional analytical methods often depend on simplifying assumptions, while learning-based techniques can be computationally demanding and limit the control policies to existing data. This paper introduces a novel approach to soft robotic control, leveraging state-of-the-art policy gradient methods within parallelizable synthetic environments learned from data. We also propose a safety oriented actuation space exploration protocol via cascaded updates and weighted randomness. Specifically, our recurrent forward dynamics model is learned by generating a training dataset from a physically safe \textit{mean reverting} random walk in actuation space to explore the partially-observed state-space. We demonstrate a reinforcement learning approach towards closed-loop control through state-of-the-art actor-critic methods, which efficiently learn high-performance behaviour over long horizons. This approach removes the need for any knowledge regarding the robot's operation or capabilities and sets the stage for a comprehensive benchmarking tool in soft robotics control.
* soft manipulator, reinforcement learning, learned controllers
Risks and Opportunities of Open-Source Generative AI
May 14, 2024



Applications of Generative AI (Gen AI) are expected to revolutionize a number of different areas, ranging from science & medicine to education. The potential for these seismic changes has triggered a lively debate about the potential risks of the technology, and resulted in calls for tighter regulation, in particular from some of the major tech companies who are leading in AI development. This regulation is likely to put at risk the budding field of open-source generative AI. Using a three-stage framework for Gen AI development (near, mid and long-term), we analyze the risks and opportunities of open-source generative AI models with similar capabilities to the ones currently available (near to mid-term) and with greater capabilities (long-term). We argue that, overall, the benefits of open-source Gen AI outweigh its risks. As such, we encourage the open sourcing of models, training and evaluation data, and provide a set of recommendations and best practices for managing risks associated with open-source generative AI.
Near to Mid-term Risks and Opportunities of Open Source Generative AI
Apr 25, 2024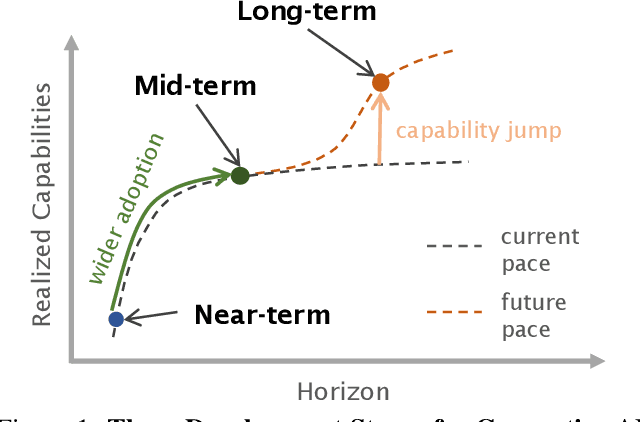
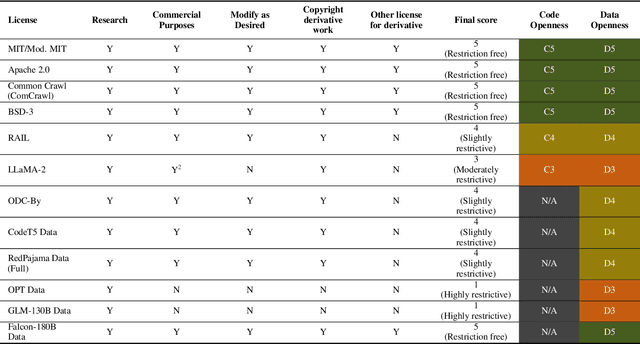
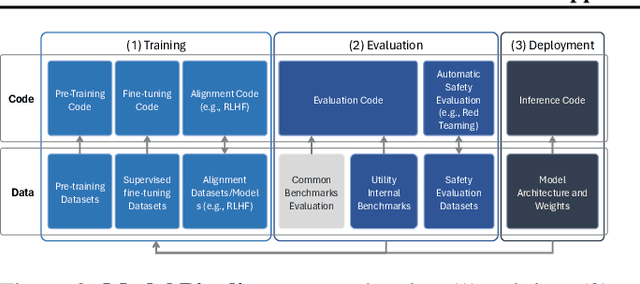
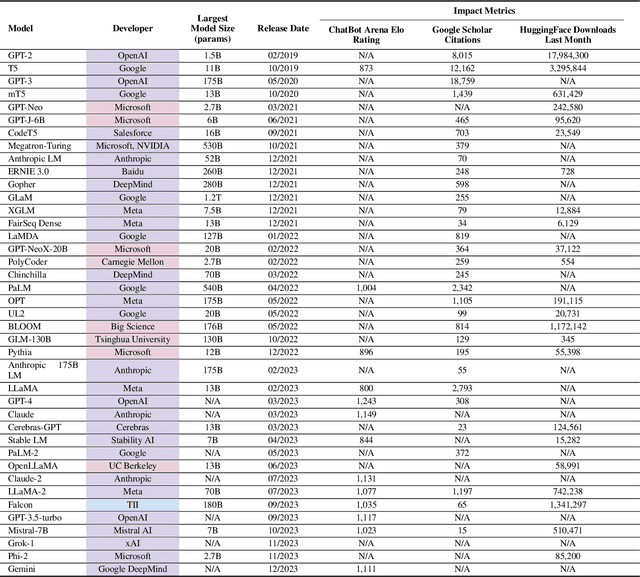
In the next few years, applications of Generative AI are expected to revolutionize a number of different areas, ranging from science & medicine to education. The potential for these seismic changes has triggered a lively debate about potential risks and resulted in calls for tighter regulation, in particular from some of the major tech companies who are leading in AI development. This regulation is likely to put at risk the budding field of open source Generative AI. We argue for the responsible open sourcing of generative AI models in the near and medium term. To set the stage, we first introduce an AI openness taxonomy system and apply it to 40 current large language models. We then outline differential benefits and risks of open versus closed source AI and present potential risk mitigation, ranging from best practices to calls for technical and scientific contributions. We hope that this report will add a much needed missing voice to the current public discourse on near to mid-term AI safety and other societal impact.
SplAgger: Split Aggregation for Meta-Reinforcement Learning
Mar 08, 2024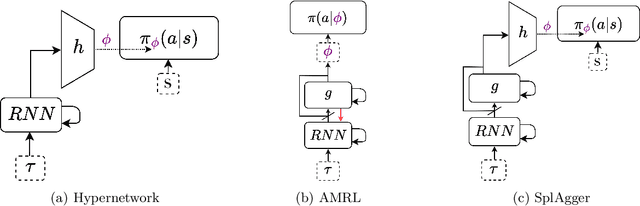
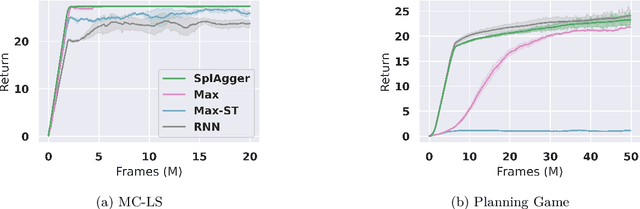
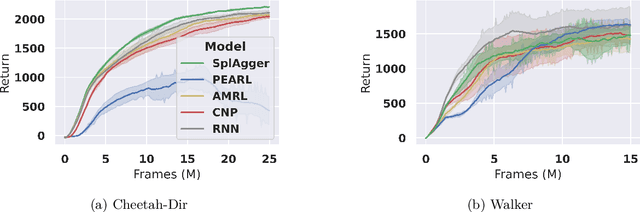
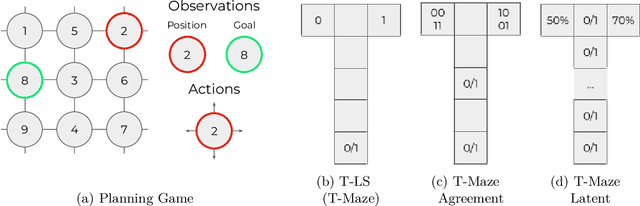
A core ambition of reinforcement learning (RL) is the creation of agents capable of rapid learning in novel tasks. Meta-RL aims to achieve this by directly learning such agents. Black box methods do so by training off-the-shelf sequence models end-to-end. By contrast, task inference methods explicitly infer a posterior distribution over the unknown task, typically using distinct objectives and sequence models designed to enable task inference. Recent work has shown that task inference methods are not necessary for strong performance. However, it remains unclear whether task inference sequence models are beneficial even when task inference objectives are not. In this paper, we present strong evidence that task inference sequence models are still beneficial. In particular, we investigate sequence models with permutation invariant aggregation, which exploit the fact that, due to the Markov property, the task posterior does not depend on the order of data. We empirically confirm the advantage of permutation invariant sequence models without the use of task inference objectives. However, we also find, surprisingly, that there are multiple conditions under which permutation variance remains useful. Therefore, we propose SplAgger, which uses both permutation variant and invariant components to achieve the best of both worlds, outperforming all baselines on continuous control and memory environments.
Craftax: A Lightning-Fast Benchmark for Open-Ended Reinforcement Learning
Feb 26, 2024

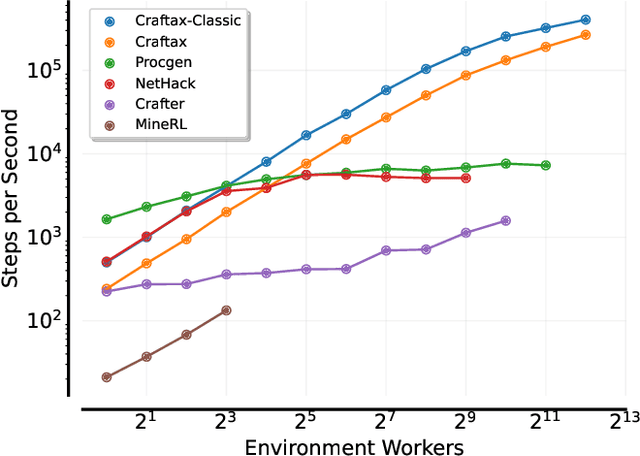

Benchmarks play a crucial role in the development and analysis of reinforcement learning (RL) algorithms. We identify that existing benchmarks used for research into open-ended learning fall into one of two categories. Either they are too slow for meaningful research to be performed without enormous computational resources, like Crafter, NetHack and Minecraft, or they are not complex enough to pose a significant challenge, like Minigrid and Procgen. To remedy this, we first present Craftax-Classic: a ground-up rewrite of Crafter in JAX that runs up to 250x faster than the Python-native original. A run of PPO using 1 billion environment interactions finishes in under an hour using only a single GPU and averages 90% of the optimal reward. To provide a more compelling challenge we present the main Craftax benchmark, a significant extension of the Crafter mechanics with elements inspired from NetHack. Solving Craftax requires deep exploration, long term planning and memory, as well as continual adaptation to novel situations as more of the world is discovered. We show that existing methods including global and episodic exploration, as well as unsupervised environment design fail to make material progress on the benchmark. We believe that Craftax can for the first time allow researchers to experiment in a complex, open-ended environment with limited computational resources.