 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoal-Conditioned Agents that Learn Everything All at Once
May 22, 2026A goal-conditioned reinforcement learning agent exploring an environment will see a wealth of information throughout a trajectory, most of which is discarded when only performing on-policy updates with respect to the commanded goal. All-goals learning, where each transition is used for learning off-policy with respect to every goal, allows agents to extract maximal information, however it is usually computationally infeasible when done via naive relabelling. This can be overcome by jointly outputting values and actions for every goal at once, allowing for efficient, parallel all-goals updates with a single pass through the network, in a process we call Learning Everything all at Once (LEO). We show that this approach significantly outperforms other methods on goal-conditioned Craftax and is competitive with existing baselines on continuous control environments, while achieving a >250x speed-up compared to all-goals relabelling. We then go on to show that this approach can be made even more powerful by using LEO as a teacher network, rather than a direct actor. We hope that, by unlocking all-goals learning at scale, LEO can serve as a useful tool for RL practitioners in complex environments. We open source our code.
Procedural Generation of Algorithm Discovery Tasks in Machine Learning
Mar 18, 2026Automating the development of machine learning algorithms has the potential to unlock new breakthroughs. However, our ability to improve and evaluate algorithm discovery systems has thus far been limited by existing task suites. They suffer from many issues, such as: poor evaluation methodologies; data contamination; and containing saturated or very similar problems. Here, we introduce DiscoGen, a procedural generator of algorithm discovery tasks for machine learning, such as developing optimisers for reinforcement learning or loss functions for image classification. Motivated by the success of procedural generation in reinforcement learning, DiscoGen spans millions of tasks of varying difficulty and complexity from a range of machine learning fields. These tasks are specified by a small number of configuration parameters and can be used to optimise algorithm discovery agents (ADAs). We present DiscoBench, a benchmark consisting of a fixed, small subset of DiscoGen tasks for principled evaluation of ADAs. Finally, we propose a number of ambitious, impactful research directions enabled by DiscoGen, in addition to experiments demonstrating its use for prompt optimisation of an ADA. DiscoGen is released open-source at https://github.com/AlexGoldie/discogen.
An Optimisation Framework for Unsupervised Environment Design
May 27, 2025For reinforcement learning agents to be deployed in high-risk settings, they must achieve a high level of robustness to unfamiliar scenarios. One method for improving robustness is unsupervised environment design (UED), a suite of methods aiming to maximise an agent's generalisability across configurations of an environment. In this work, we study UED from an optimisation perspective, providing stronger theoretical guarantees for practical settings than prior work. Whereas previous methods relied on guarantees if they reach convergence, our framework employs a nonconvex-strongly-concave objective for which we provide a provably convergent algorithm in the zero-sum setting. We empirically verify the efficacy of our method, outperforming prior methods in a number of environments with varying difficulties.
Kinetix: Investigating the Training of General Agents through Open-Ended Physics-Based Control Tasks
Oct 30, 2024While large models trained with self-supervised learning on offline datasets have shown remarkable capabilities in text and image domains, achieving the same generalisation for agents that act in sequential decision problems remains an open challenge. In this work, we take a step towards this goal by procedurally generating tens of millions of 2D physics-based tasks and using these to train a general reinforcement learning (RL) agent for physical control. To this end, we introduce Kinetix: an open-ended space of physics-based RL environments that can represent tasks ranging from robotic locomotion and grasping to video games and classic RL environments, all within a unified framework. Kinetix makes use of our novel hardware-accelerated physics engine Jax2D that allows us to cheaply simulate billions of environment steps during training. Our trained agent exhibits strong physical reasoning capabilities, being able to zero-shot solve unseen human-designed environments. Furthermore, fine-tuning this general agent on tasks of interest shows significantly stronger performance than training an RL agent *tabula rasa*. This includes solving some environments that standard RL training completely fails at. We believe this demonstrates the feasibility of large scale, mixed-quality pre-training for online RL and we hope that Kinetix will serve as a useful framework to investigate this further.
JaxLife: An Open-Ended Agentic Simulator
Sep 01, 2024Human intelligence emerged through the process of natural selection and evolution on Earth. We investigate what it would take to re-create this process in silico. While past work has often focused on low-level processes (such as simulating physics or chemistry), we instead take a more targeted approach, aiming to evolve agents that can accumulate open-ended culture and technologies across generations. Towards this, we present JaxLife: an artificial life simulator in which embodied agents, parameterized by deep neural networks, must learn to survive in an expressive world containing programmable systems. First, we describe the environment and show that it can facilitate meaningful Turing-complete computation. We then analyze the evolved emergent agents' behavior, such as rudimentary communication protocols, agriculture, and tool use. Finally, we investigate how complexity scales with the amount of compute used. We believe JaxLife takes a step towards studying evolved behavior in more open-ended simulations. Our code is available at https://github.com/luchris429/JaxLife
No Regrets: Investigating and Improving Regret Approximations for Curriculum Discovery
Aug 27, 2024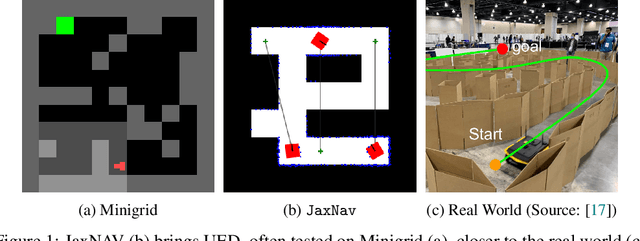
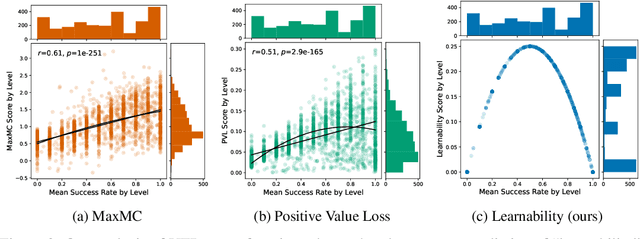
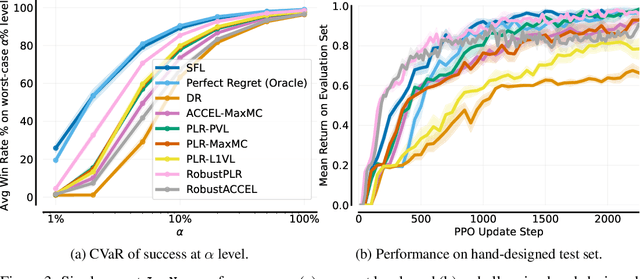
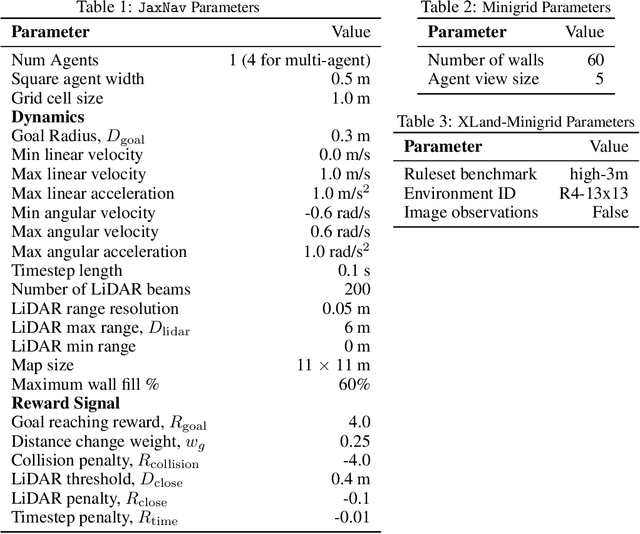
What data or environments to use for training to improve downstream performance is a longstanding and very topical question in reinforcement learning. In particular, Unsupervised Environment Design (UED) methods have gained recent attention as their adaptive curricula enable agents to be robust to in- and out-of-distribution tasks. We ask to what extent these methods are themselves robust when applied to a novel setting, closely inspired by a real-world robotics problem. Surprisingly, we find that the state-of-the-art UED methods either do not improve upon the na\"{i}ve baseline of Domain Randomisation (DR), or require substantial hyperparameter tuning to do so. Our analysis shows that this is due to their underlying scoring functions failing to predict intuitive measures of ``learnability'', i.e., in finding the settings that the agent sometimes solves, but not always. Based on this, we instead directly train on levels with high learnability and find that this simple and intuitive approach outperforms UED methods and DR in several binary-outcome environments, including on our domain and the standard UED domain of Minigrid. We further introduce a new adversarial evaluation procedure for directly measuring robustness, closely mirroring the conditional value at risk (CVaR). We open-source all our code and present visualisations of final policies here: https://github.com/amacrutherford/sampling-for-learnability.
JaxUED: A simple and useable UED library in Jax
Mar 19, 2024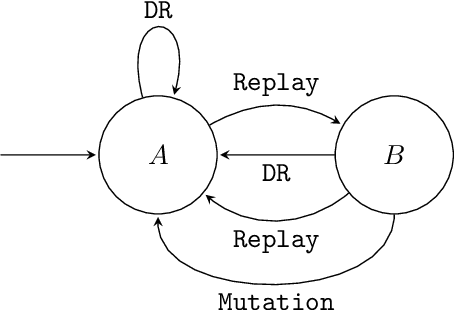


We present JaxUED, an open-source library providing minimal dependency implementations of modern Unsupervised Environment Design (UED) algorithms in Jax. JaxUED leverages hardware acceleration to obtain on the order of 100x speedups compared to prior, CPU-based implementations. Inspired by CleanRL, we provide fast, clear, understandable, and easily modifiable implementations, with the aim of accelerating research into UED. This paper describes our library and contains baseline results. Code can be found at https://github.com/DramaCow/jaxued.
Craftax: A Lightning-Fast Benchmark for Open-Ended Reinforcement Learning
Feb 26, 2024

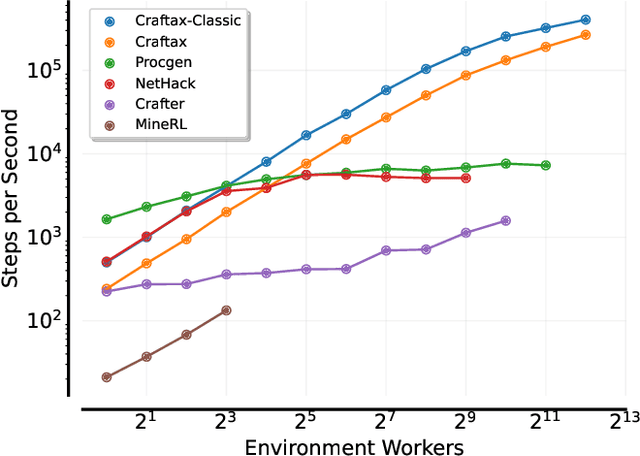

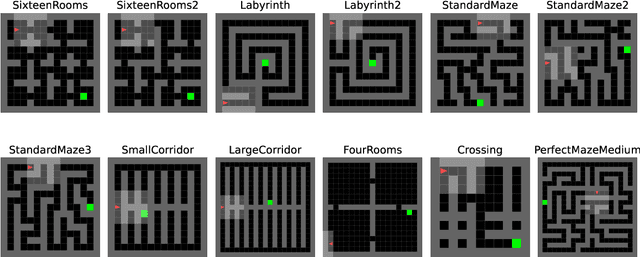
Benchmarks play a crucial role in the development and analysis of reinforcement learning (RL) algorithms. We identify that existing benchmarks used for research into open-ended learning fall into one of two categories. Either they are too slow for meaningful research to be performed without enormous computational resources, like Crafter, NetHack and Minecraft, or they are not complex enough to pose a significant challenge, like Minigrid and Procgen. To remedy this, we first present Craftax-Classic: a ground-up rewrite of Crafter in JAX that runs up to 250x faster than the Python-native original. A run of PPO using 1 billion environment interactions finishes in under an hour using only a single GPU and averages 90% of the optimal reward. To provide a more compelling challenge we present the main Craftax benchmark, a significant extension of the Crafter mechanics with elements inspired from NetHack. Solving Craftax requires deep exploration, long term planning and memory, as well as continual adaptation to novel situations as more of the world is discovered. We show that existing methods including global and episodic exploration, as well as unsupervised environment design fail to make material progress on the benchmark. We believe that Craftax can for the first time allow researchers to experiment in a complex, open-ended environment with limited computational resources.
Refining Minimax Regret for Unsupervised Environment Design
Feb 19, 2024In unsupervised environment design, reinforcement learning agents are trained on environment configurations (levels) generated by an adversary that maximises some objective. Regret is a commonly used objective that theoretically results in a minimax regret (MMR) policy with desirable robustness guarantees; in particular, the agent's maximum regret is bounded. However, once the agent reaches this regret bound on all levels, the adversary will only sample levels where regret cannot be further reduced. Although there are possible performance improvements to be made outside of these regret-maximising levels, learning stagnates. In this work, we introduce Bayesian level-perfect MMR (BLP), a refinement of the minimax regret objective that overcomes this limitation. We formally show that solving for this objective results in a subset of MMR policies, and that BLP policies act consistently with a Perfect Bayesian policy over all levels. We further introduce an algorithm, ReMiDi, that results in a BLP policy at convergence. We empirically demonstrate that training on levels from a minimax regret adversary causes learning to prematurely stagnate, but that ReMiDi continues learning.
Dynamics Generalisation in Reinforcement Learning via Adaptive Context-Aware Policies
Oct 25, 2023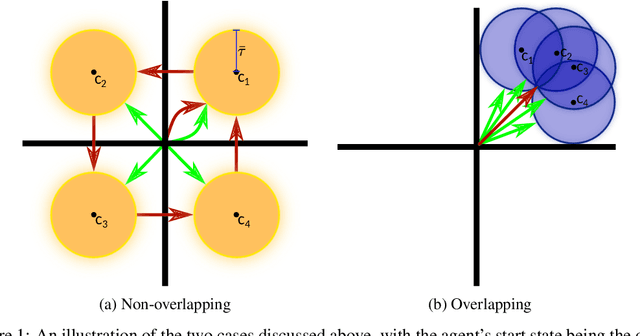
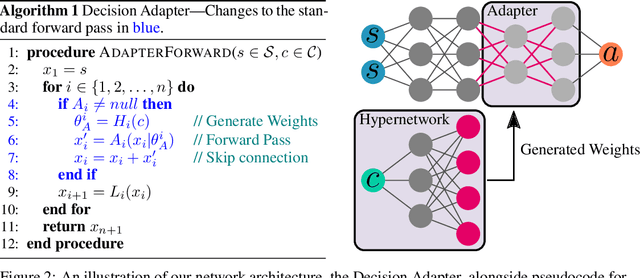
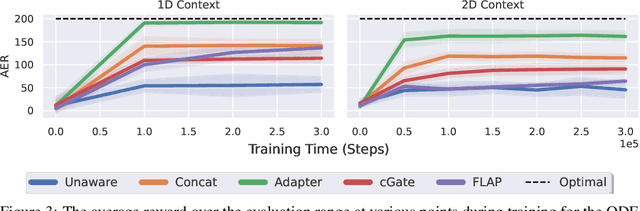
While reinforcement learning has achieved remarkable successes in several domains, its real-world application is limited due to many methods failing to generalise to unfamiliar conditions. In this work, we consider the problem of generalising to new transition dynamics, corresponding to cases in which the environment's response to the agent's actions differs. For example, the gravitational force exerted on a robot depends on its mass and changes the robot's mobility. Consequently, in such cases, it is necessary to condition an agent's actions on extrinsic state information and pertinent contextual information reflecting how the environment responds. While the need for context-sensitive policies has been established, the manner in which context is incorporated architecturally has received less attention. Thus, in this work, we present an investigation into how context information should be incorporated into behaviour learning to improve generalisation. To this end, we introduce a neural network architecture, the Decision Adapter, which generates the weights of an adapter module and conditions the behaviour of an agent on the context information. We show that the Decision Adapter is a useful generalisation of a previously proposed architecture and empirically demonstrate that it results in superior generalisation performance compared to previous approaches in several environments. Beyond this, the Decision Adapter is more robust to irrelevant distractor variables than several alternative methods.